 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocusDiT: Masking Queries in Diffusion Transformers for Fine-grained Image Generation
Jun 01, 2026Diffusion transformer (DiT) has been widely adopted in the generative diffusion field, advancing the denoising of query tokens through attention and Feed-Forward (\text{FFN}) layers. FFN actually acts as the key-value vocabulary for decoding visual contents where the value embeds the visual semantical knowledge. We present that focusing on critical query tokens corresponding to more complex details and encouraging the model to improve these tokens is essential for fine-grained visual generation. To this end, we propose FocusDiT, which applies a Masking scheme to focus on critical query tokens that are exclusively fed into FFN. The masked queries can retrieve visual tokens from the FFN vocabularies, and use them to decode their visual details. Extensive text-to-image experiments validate the effectiveness of token masking in enhancing generative performance.
Equilibrated Diffusion: Frequency-aware Textual Embedding for Equilibrated Image Customization
Jun 01, 2026Image customization learns target subjects from reference concept images and generates conditioned images per text prompts, mainly modifying styles or backgrounds. Prevailing methods adopt fine-tuning to pack diverse concept attributes into a unified latent embedding, yet entangled attributes hinder elimination of irrelevant disturbances from style and background. To address this issue, we propose Equilibrated Diffusion, a frequency-driven approach that disentangles tangled concept features for balanced customization and consistent text-visual matching. Unlike conventional methods learning full concepts with shared embeddings and unified tuning, our work utilizes the inherent link between image frequency components and semantics: low frequencies represent subject content and high frequencies correspond to styles. We decompose concepts in frequency space and optimize each embedding independently. This separate optimization enables the denoiser to capture style detached from subject identity and generalize better to unseen stylistic prompts. Merging multi-frequency embeddings preserves the model's original spatial customization ability. We further deploy mask-guided diffusion to restrict irrelevant background changes and boost text alignment. Residual Reference Attention (RRA) is inserted into spatial attention to retain subject structure and identity consistency. Experiments prove Equilibrated Diffusion exceeds mainstream baselines on subject fidelity and text adherence, verifying our method's superiority.
RSGMamba: Reliability-Aware Self-Gated State Space Model for Multimodal Semantic Segmentation
Apr 14, 2026Multimodal semantic segmentation has emerged as a powerful paradigm for enhancing scene understanding by leveraging complementary information from multiple sensing modalities (e.g., RGB, depth, and thermal). However, existing cross-modal fusion methods often implicitly assume that all modalities are equally reliable, which can lead to feature degradation when auxiliary modalities are noisy, misaligned, or incomplete. In this paper, we revisit cross-modal fusion from the perspective of modality reliability and propose a novel framework termed the Reliability-aware Self-Gated State Space Model (RSGMamba). At the core of our method is the Reliability-aware Self-Gated Mamba Block (RSGMB), which explicitly models modality reliability and dynamically regulates cross-modal interactions through a self-gating mechanism. Unlike conventional fusion strategies that indiscriminately exchange information across modalities, RSGMB enables reliability-aware feature selection and enhancing informative feature aggregation. In addition, a lightweight Local Cross-Gated Modulation (LCGM) is incorporated to refine fine-grained spatial details, complementing the global modeling capability of RSGMB. Extensive experiments demonstrate that RSGMamba achieves state-of-the-art performance on both RGB-D and RGB-T semantic segmentation benchmarks, resulting 58.8% / 54.0% mIoU on NYUDepth V2 and SUN-RGBD (+0.4% / +0.7% over prior best), and 61.1% / 88.9% mIoU on MFNet and PST900 (up to +1.6%), with only 48.6M parameters, thereby validating the effectiveness and superiority of the proposed approach.
Mastering Negation: Boosting Grounding Models via Grouped Opposition-Based Learning
Mar 13, 2026Current vision-language detection and grounding models predominantly focus on prompts with positive semantics and often struggle to accurately interpret and ground complex expressions containing negative semantics. A key reason for this limitation is the lack of high-quality training data that explicitly captures discriminative negative samples and negation-aware language descriptions. To address this challenge, we introduce D-Negation, a new dataset that provides objects annotated with both positive and negative semantic descriptions. Building upon the observation that negation reasoning frequently appears in natural language, we further propose a grouped opposition-based learning framework that learns negation-aware representations from limited samples. Specifically, our method organizes opposing semantic descriptions from D-Negation into structured groups and formulates two complementary loss functions that encourage the model to reason about negation and semantic qualifiers. We integrate the proposed dataset and learning strategy into a state-of-the-art language-based grounding model. By fine-tuning fewer than 10 percent of the model parameters, our approach achieves improvements of up to 4.4 mAP and 5.7 mAP on positive and negative semantic evaluations, respectively. These results demonstrate that explicitly modeling negation semantics can substantially enhance the robustness and localization accuracy of vision-language grounding models.
FADPNet: Frequency-Aware Dual-Path Network for Face Super-Resolution
Jun 17, 2025Face super-resolution (FSR) under limited computational costs remains an open problem. Existing approaches typically treat all facial pixels equally, resulting in suboptimal allocation of computational resources and degraded FSR performance. CNN is relatively sensitive to high-frequency facial features, such as component contours and facial outlines. Meanwhile, Mamba excels at capturing low-frequency features like facial color and fine-grained texture, and does so with lower complexity than Transformers. Motivated by these observations, we propose FADPNet, a Frequency-Aware Dual-Path Network that decomposes facial features into low- and high-frequency components and processes them via dedicated branches. For low-frequency regions, we introduce a Mamba-based Low-Frequency Enhancement Block (LFEB), which combines state-space attention with squeeze-and-excitation operations to extract low-frequency global interactions and emphasize informative channels. For high-frequency regions, we design a CNN-based Deep Position-Aware Attention (DPA) module to enhance spatially-dependent structural details, complemented by a lightweight High-Frequency Refinement (HFR) module that further refines frequency-specific representations. Through the above designs, our method achieves an excellent balance between FSR quality and model efficiency, outperforming existing approaches.
S2AFormer: Strip Self-Attention for Efficient Vision Transformer
May 28, 2025Vision Transformer (ViT) has made significant advancements in computer vision, thanks to its token mixer's sophisticated ability to capture global dependencies between all tokens. However, the quadratic growth in computational demands as the number of tokens increases limits its practical efficiency. Although recent methods have combined the strengths of convolutions and self-attention to achieve better trade-offs, the expensive pairwise token affinity and complex matrix operations inherent in self-attention remain a bottleneck. To address this challenge, we propose S2AFormer, an efficient Vision Transformer architecture featuring novel Strip Self-Attention (SSA). We design simple yet effective Hybrid Perception Blocks (HPBs) to effectively integrate the local perception capabilities of CNNs with the global context modeling of Transformer's attention mechanisms. A key innovation of SSA lies in its reducing the spatial dimensions of $K$ and $V$ while compressing the channel dimensions of $Q$ and $K$. This design significantly reduces computational overhead while preserving accuracy, striking an optimal balance between efficiency and effectiveness. We evaluate the robustness and efficiency of S2AFormer through extensive experiments on multiple vision benchmarks, including ImageNet-1k for image classification, ADE20k for semantic segmentation, and COCO for object detection and instance segmentation. Results demonstrate that S2AFormer achieves significant accuracy gains with superior efficiency in both GPU and non-GPU environments, making it a strong candidate for efficient vision Transformers.
Reinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models
May 15, 2025We introduce the \emph{Diffusion Chain of Lateral Thought (DCoLT)}, a reasoning framework for diffusion language models. DCoLT treats each intermediate step in the reverse diffusion process as a latent "thinking" action and optimizes the entire reasoning trajectory to maximize the reward on the correctness of the final answer with outcome-based Reinforcement Learning (RL). Unlike traditional Chain-of-Thought (CoT) methods that follow a causal, linear thinking process, DCoLT allows bidirectional, non-linear reasoning with no strict rule on grammatical correctness amid its intermediate steps of thought. We implement DCoLT on two representative Diffusion Language Models (DLMs). First, we choose SEDD as a representative continuous-time discrete diffusion model, where its concrete score derives a probabilistic policy to maximize the RL reward over the entire sequence of intermediate diffusion steps. We further consider the discrete-time masked diffusion language model -- LLaDA, and find that the order to predict and unmask tokens plays an essential role to optimize its RL action resulting from the ranking-based Unmasking Policy Module (UPM) defined by the Plackett-Luce model. Experiments on both math and code generation tasks show that using only public data and 16 H800 GPUs, DCoLT-reinforced DLMs outperform other DLMs trained by SFT or RL or even both. Notably, DCoLT-reinforced LLaDA boosts its reasoning accuracy by +9.8%, +5.7%, +11.4%, +19.5% on GSM8K, MATH, MBPP, and HumanEval.
Self-Guidance: Boosting Flow and Diffusion Generation on Their Own
Dec 08, 2024



Proper guidance strategies are essential to get optimal generation results without re-training diffusion and flow-based text-to-image models. However, existing guidances either require specific training or strong inductive biases of neural network architectures, potentially limiting their applications. To address these issues, in this paper, we introduce Self-Guidance (SG), a strong diffusion guidance that neither needs specific training nor requires certain forms of neural network architectures. Different from previous approaches, the Self-Guidance calculates the guidance vectors by measuring the difference between the velocities of two successive diffusion timesteps. Therefore, SG can be readily applied for both conditional and unconditional models with flexible network architectures. We conduct intensive experiments on both text-to-image generation and text-to-video generations across flexible architectures including UNet-based models and diffusion transformer-based models. On current state-of-the-art diffusion models such as Stable Diffusion 3.5 and FLUX, SG significantly boosts the image generation performance in terms of FID, and Human Preference Scores. Moreover, we find that SG has a surprisingly positive effect on the generation of high-quality human bodies such as hands, faces, and arms, showing strong potential to overcome traditional challenges on human body generations with minimal effort. We will release our implementation of SG on SD 3.5 and FLUX models along with this paper.
Schedule On the Fly: Diffusion Time Prediction for Faster and Better Image Generation
Dec 02, 2024



Diffusion and flow models have achieved remarkable successes in various applications such as text-to-image generation. However, these models typically rely on the same predetermined denoising schedules during inference for each prompt, which potentially limits the inference efficiency as well as the flexibility when handling different prompts. In this paper, we argue that the optimal noise schedule should adapt to each inference instance, and introduce the Time Prediction Diffusion Model (TPDM) to accomplish this. TPDM employs a plug-and-play Time Prediction Module (TPM) that predicts the next noise level based on current latent features at each denoising step. We train the TPM using reinforcement learning, aiming to maximize a reward that discounts the final image quality by the number of denoising steps. With such an adaptive scheduler, TPDM not only generates high-quality images that are aligned closely with human preferences but also adjusts the number of denoising steps and time on the fly, enhancing both performance and efficiency. We train TPDMs on multiple diffusion model benchmarks. With Stable Diffusion 3 Medium architecture, TPDM achieves an aesthetic score of 5.44 and a human preference score (HPS) of 29.59, while using around 50% fewer denoising steps to achieve better performance. We will release our best model alongside this paper.
SCASeg: Strip Cross-Attention for Efficient Semantic Segmentation
Nov 26, 2024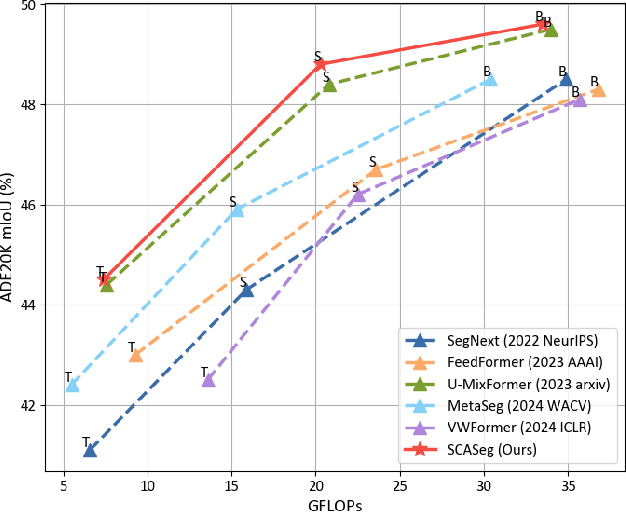

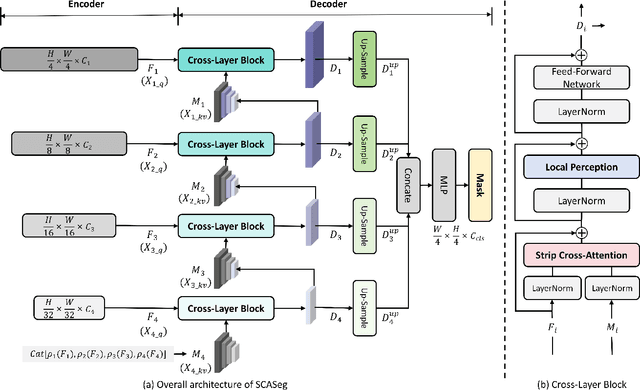

The Vision Transformer (ViT) has achieved notable success in computer vision, with its variants extensively validated across various downstream tasks, including semantic segmentation. However, designed as general-purpose visual encoders, ViT backbones often overlook the specific needs of task decoders, revealing opportunities to design decoders tailored to efficient semantic segmentation. This paper proposes Strip Cross-Attention (SCASeg), an innovative decoder head explicitly designed for semantic segmentation. Instead of relying on the simple conventional skip connections, we employ lateral connections between the encoder and decoder stages, using encoder features as Queries for the cross-attention modules. Additionally, we introduce a Cross-Layer Block that blends hierarchical feature maps from different encoder and decoder stages to create a unified representation for Keys and Values. To further boost computational efficiency, SCASeg compresses queries and keys into strip-like patterns to optimize memory usage and inference speed over the traditional vanilla cross-attention. Moreover, the Cross-Layer Block incorporates the local perceptual strengths of convolution, enabling SCASeg to capture both global and local context dependencies across multiple layers. This approach facilitates effective feature interaction at different scales, improving the overall performance. Experiments show that the adaptable decoder of SCASeg produces competitive performance across different setups, surpassing leading segmentation architectures on all benchmark datasets, including ADE20K, Cityscapes, COCO-Stuff 164k, and Pascal VOC2012, even under varying computational limitations.