 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcing the Diffusion Chain of Lateral Thought with Diffusion Language Models
May 15, 2025We introduce the \emph{Diffusion Chain of Lateral Thought (DCoLT)}, a reasoning framework for diffusion language models. DCoLT treats each intermediate step in the reverse diffusion process as a latent "thinking" action and optimizes the entire reasoning trajectory to maximize the reward on the correctness of the final answer with outcome-based Reinforcement Learning (RL). Unlike traditional Chain-of-Thought (CoT) methods that follow a causal, linear thinking process, DCoLT allows bidirectional, non-linear reasoning with no strict rule on grammatical correctness amid its intermediate steps of thought. We implement DCoLT on two representative Diffusion Language Models (DLMs). First, we choose SEDD as a representative continuous-time discrete diffusion model, where its concrete score derives a probabilistic policy to maximize the RL reward over the entire sequence of intermediate diffusion steps. We further consider the discrete-time masked diffusion language model -- LLaDA, and find that the order to predict and unmask tokens plays an essential role to optimize its RL action resulting from the ranking-based Unmasking Policy Module (UPM) defined by the Plackett-Luce model. Experiments on both math and code generation tasks show that using only public data and 16 H800 GPUs, DCoLT-reinforced DLMs outperform other DLMs trained by SFT or RL or even both. Notably, DCoLT-reinforced LLaDA boosts its reasoning accuracy by +9.8%, +5.7%, +11.4%, +19.5% on GSM8K, MATH, MBPP, and HumanEval.
Schedule On the Fly: Diffusion Time Prediction for Faster and Better Image Generation
Dec 02, 2024



Diffusion and flow models have achieved remarkable successes in various applications such as text-to-image generation. However, these models typically rely on the same predetermined denoising schedules during inference for each prompt, which potentially limits the inference efficiency as well as the flexibility when handling different prompts. In this paper, we argue that the optimal noise schedule should adapt to each inference instance, and introduce the Time Prediction Diffusion Model (TPDM) to accomplish this. TPDM employs a plug-and-play Time Prediction Module (TPM) that predicts the next noise level based on current latent features at each denoising step. We train the TPM using reinforcement learning, aiming to maximize a reward that discounts the final image quality by the number of denoising steps. With such an adaptive scheduler, TPDM not only generates high-quality images that are aligned closely with human preferences but also adjusts the number of denoising steps and time on the fly, enhancing both performance and efficiency. We train TPDMs on multiple diffusion model benchmarks. With Stable Diffusion 3 Medium architecture, TPDM achieves an aesthetic score of 5.44 and a human preference score (HPS) of 29.59, while using around 50% fewer denoising steps to achieve better performance. We will release our best model alongside this paper.
Flow Generator Matching
Oct 25, 2024



In the realm of Artificial Intelligence Generated Content (AIGC), flow-matching models have emerged as a powerhouse, achieving success due to their robust theoretical underpinnings and solid ability for large-scale generative modeling. These models have demonstrated state-of-the-art performance, but their brilliance comes at a cost. The process of sampling from these models is notoriously demanding on computational resources, as it necessitates the use of multi-step numerical ordinary differential equations (ODEs). Against this backdrop, this paper presents a novel solution with theoretical guarantees in the form of Flow Generator Matching (FGM), an innovative approach designed to accelerate the sampling of flow-matching models into a one-step generation, while maintaining the original performance. On the CIFAR10 unconditional generation benchmark, our one-step FGM model achieves a new record Fr\'echet Inception Distance (FID) score of 3.08 among few-step flow-matching-based models, outperforming original 50-step flow-matching models. Furthermore, we use the FGM to distill the Stable Diffusion 3, a leading text-to-image flow-matching model based on the MM-DiT architecture. The resulting MM-DiT-FGM one-step text-to-image model demonstrates outstanding industry-level performance. When evaluated on the GenEval benchmark, MM-DiT-FGM has delivered remarkable generating qualities, rivaling other multi-step models in light of the efficiency of a single generation step.
One-Step Diffusion Distillation through Score Implicit Matching
Oct 22, 2024
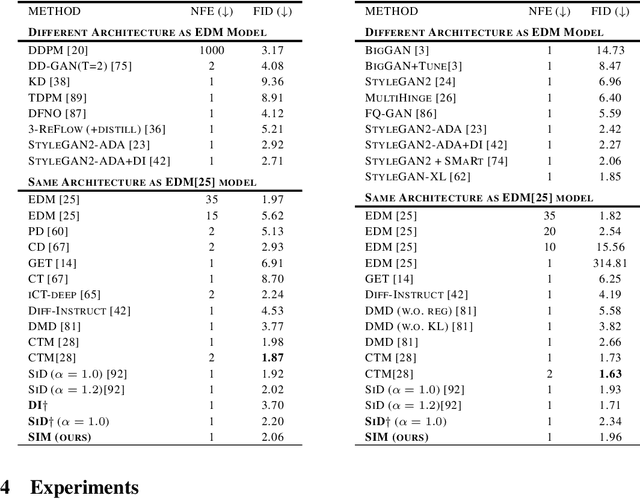


Despite their strong performances on many generative tasks, diffusion models require a large number of sampling steps in order to generate realistic samples. This has motivated the community to develop effective methods to distill pre-trained diffusion models into more efficient models, but these methods still typically require few-step inference or perform substantially worse than the underlying model. In this paper, we present Score Implicit Matching (SIM) a new approach to distilling pre-trained diffusion models into single-step generator models, while maintaining almost the same sample generation ability as the original model as well as being data-free with no need of training samples for distillation. The method rests upon the fact that, although the traditional score-based loss is intractable to minimize for generator models, under certain conditions we can efficiently compute the gradients for a wide class of score-based divergences between a diffusion model and a generator. SIM shows strong empirical performances for one-step generators: on the CIFAR10 dataset, it achieves an FID of 2.06 for unconditional generation and 1.96 for class-conditional generation. Moreover, by applying SIM to a leading transformer-based diffusion model, we distill a single-step generator for text-to-image (T2I) generation that attains an aesthetic score of 6.42 with no performance decline over the original multi-step counterpart, clearly outperforming the other one-step generators including SDXL-TURBO of 5.33, SDXL-LIGHTNING of 5.34 and HYPER-SDXL of 5.85. We will release this industry-ready one-step transformer-based T2I generator along with this paper.
* Accepted by NeurIPS 2024