 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltra Fast PDE Solving via Physics Guided Few-step Diffusion
Feb 03, 2026Diffusion-based models have demonstrated impressive accuracy and generalization in solving partial differential equations (PDEs). However, they still face significant limitations, such as high sampling costs and insufficient physical consistency, stemming from their many-step iterative sampling mechanism and lack of explicit physics constraints. To address these issues, we propose Phys-Instruct, a novel physics-guided distillation framework which not only (1) compresses a pre-trained diffusion PDE solver into a few-step generator via matching generator and prior diffusion distributions to enable rapid sampling, but also (2) enhances the physics consistency by explicitly injecting PDE knowledge through a PDE distillation guidance. Physic-Instruct is built upon a solid theoretical foundation, leading to a practical physics-constrained training objective that admits tractable gradients. Across five PDE benchmarks, Phys-Instruct achieves orders-of-magnitude faster inference while reducing PDE error by more than 8 times compared to state-of-the-art diffusion baselines. Moreover, the resulting unconditional student model functions as a compact prior, enabling efficient and physically consistent inference for various downstream conditional tasks. Our results indicate that Phys-Instruct is a novel, effective, and efficient framework for ultra-fast PDE solving powered by deep generative models.
Masked Auto-Regressive Variational Acceleration: Fast Inference Makes Practical Reinforcement Learning
Nov 19, 2025Masked auto-regressive diffusion models (MAR) benefit from the expressive modeling ability of diffusion models and the flexibility of masked auto-regressive ordering. However, vanilla MAR suffers from slow inference due to its hierarchical inference mechanism: an outer AR unmasking loop and an inner diffusion denoising chain. Such decoupled structure not only harm the generation efficiency but also hinder the practical use of MAR for reinforcement learning (RL), an increasingly critical paradigm for generative model post-training.To address this fundamental issue, we introduce MARVAL (Masked Auto-regressive Variational Acceleration), a distillation-based framework that compresses the diffusion chain into a single AR generation step while preserving the flexible auto-regressive unmasking order. Such a distillation with MARVAL not only yields substantial inference acceleration but, crucially, makes RL post-training with verifiable rewards practical, resulting in scalable yet human-preferred fast generative models. Our contributions are twofold: (1) a novel score-based variational objective for distilling masked auto-regressive diffusion models into a single generation step without sacrificing sample quality; and (2) an efficient RL framework for masked auto-regressive models via MARVAL-RL. On ImageNet 256*256, MARVAL-Huge achieves an FID of 2.00 with more than 30 times speedup compared with MAR-diffusion, and MARVAL-RL yields consistent improvements in CLIP and image-reward scores on ImageNet datasets with entity names. In conclusion, MARVAL demonstrates the first practical path to distillation and RL of masked auto-regressive diffusion models, enabling fast sampling and better preference alignments.
Let Language Constrain Geometry: Vision-Language Models as Semantic and Spatial Critics for 3D Generation
Nov 18, 2025
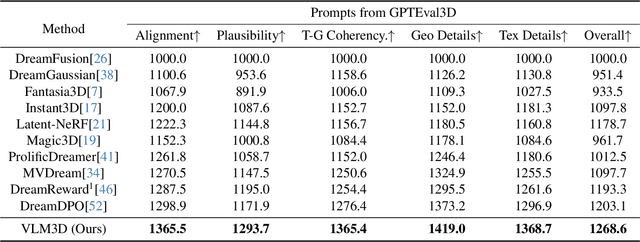
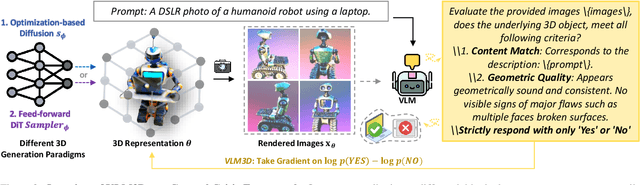
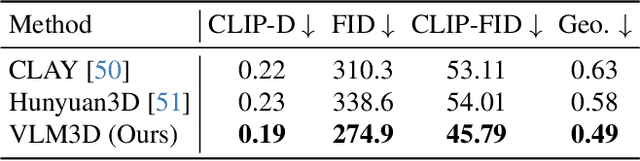
Text-to-3D generation has advanced rapidly, yet state-of-the-art models, encompassing both optimization-based and feed-forward architectures, still face two fundamental limitations. First, they struggle with coarse semantic alignment, often failing to capture fine-grained prompt details. Second, they lack robust 3D spatial understanding, leading to geometric inconsistencies and catastrophic failures in part assembly and spatial relationships. To address these challenges, we propose VLM3D, a general framework that repurposes large vision-language models (VLMs) as powerful, differentiable semantic and spatial critics. Our core contribution is a dual-query critic signal derived from the VLM's Yes or No log-odds, which assesses both semantic fidelity and geometric coherence. We demonstrate the generality of this guidance signal across two distinct paradigms: (1) As a reward objective for optimization-based pipelines, VLM3D significantly outperforms existing methods on standard benchmarks. (2) As a test-time guidance module for feed-forward pipelines, it actively steers the iterative sampling process of SOTA native 3D models to correct severe spatial errors. VLM3D establishes a principled and generalizable path to inject the VLM's rich, language-grounded understanding of both semantics and space into diverse 3D generative pipelines.
Vision-Language Models as Differentiable Semantic and Spatial Rewards for Text-to-3D Generation
Sep 19, 2025Score Distillation Sampling (SDS) enables high-quality text-to-3D generation by supervising 3D models through the denoising of multi-view 2D renderings, using a pretrained text-to-image diffusion model to align with the input prompt and ensure 3D consistency. However, existing SDS-based methods face two fundamental limitations: (1) their reliance on CLIP-style text encoders leads to coarse semantic alignment and struggles with fine-grained prompts; and (2) 2D diffusion priors lack explicit 3D spatial constraints, resulting in geometric inconsistencies and inaccurate object relationships in multi-object scenes. To address these challenges, we propose VLM3D, a novel text-to-3D generation framework that integrates large vision-language models (VLMs) into the SDS pipeline as differentiable semantic and spatial priors. Unlike standard text-to-image diffusion priors, VLMs leverage rich language-grounded supervision that enables fine-grained prompt alignment. Moreover, their inherent vision language modeling provides strong spatial understanding, which significantly enhances 3D consistency for single-object generation and improves relational reasoning in multi-object scenes. We instantiate VLM3D based on the open-source Qwen2.5-VL model and evaluate it on the GPTeval3D benchmark. Experiments across diverse objects and complex scenes show that VLM3D significantly outperforms prior SDS-based methods in semantic fidelity, geometric coherence, and spatial correctness.
Dive3D: Diverse Distillation-based Text-to-3D Generation via Score Implicit Matching
Jun 16, 2025Distilling pre-trained 2D diffusion models into 3D assets has driven remarkable advances in text-to-3D synthesis. However, existing methods typically rely on Score Distillation Sampling (SDS) loss, which involves asymmetric KL divergence--a formulation that inherently favors mode-seeking behavior and limits generation diversity. In this paper, we introduce Dive3D, a novel text-to-3D generation framework that replaces KL-based objectives with Score Implicit Matching (SIM) loss, a score-based objective that effectively mitigates mode collapse. Furthermore, Dive3D integrates both diffusion distillation and reward-guided optimization under a unified divergence perspective. Such reformulation, together with SIM loss, yields significantly more diverse 3D outputs while improving text alignment, human preference, and overall visual fidelity. We validate Dive3D across various 2D-to-3D prompts and find that it consistently outperforms prior methods in qualitative assessments, including diversity, photorealism, and aesthetic appeal. We further evaluate its performance on the GPTEval3D benchmark, comparing against nine state-of-the-art baselines. Dive3D also achieves strong results on quantitative metrics, including text-asset alignment, 3D plausibility, text-geometry consistency, texture quality, and geometric detail.
Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction
May 27, 2025In this paper, we unify more than 10 existing one-step diffusion distillation approaches, such as Diff-Instruct, DMD, SIM, SiD, $f$-distill, etc, inside a theory-driven framework which we name the \textbf{\emph{Uni-Instruct}}. Uni-Instruct is motivated by our proposed diffusion expansion theory of the $f$-divergence family. Then we introduce key theories that overcome the intractability issue of the original expanded $f$-divergence, resulting in an equivalent yet tractable loss that effectively trains one-step diffusion models by minimizing the expanded $f$-divergence family. The novel unification introduced by Uni-Instruct not only offers new theoretical contributions that help understand existing approaches from a high-level perspective but also leads to state-of-the-art one-step diffusion generation performances. On the CIFAR10 generation benchmark, Uni-Instruct achieves record-breaking Frechet Inception Distance (FID) values of \textbf{\emph{1.46}} for unconditional generation and \textbf{\emph{1.38}} for conditional generation. On the ImageNet-$64\times 64$ generation benchmark, Uni-Instruct achieves a new SoTA one-step generation FID of \textbf{\emph{1.02}}, which outperforms its 79-step teacher diffusion with a significant improvement margin of 1.33 (1.02 vs 2.35). We also apply Uni-Instruct on broader tasks like text-to-3D generation. For text-to-3D generation, Uni-Instruct gives decent results, which slightly outperforms previous methods, such as SDS and VSD, in terms of both generation quality and diversity. Both the solid theoretical and empirical contributions of Uni-Instruct will potentially help future studies on one-step diffusion distillation and knowledge transferring of diffusion models.
Rewards Are Enough for Fast Photo-Realistic Text-to-image Generation
Mar 17, 2025Aligning generated images to complicated text prompts and human preferences is a central challenge in Artificial Intelligence-Generated Content (AIGC). With reward-enhanced diffusion distillation emerging as a promising approach that boosts controllability and fidelity of text-to-image models, we identify a fundamental paradigm shift: as conditions become more specific and reward signals stronger, the rewards themselves become the dominant force in generation. In contrast, the diffusion losses serve as an overly expensive form of regularization. To thoroughly validate our hypothesis, we introduce R0, a novel conditional generation approach via regularized reward maximization. Instead of relying on tricky diffusion distillation losses, R0 proposes a new perspective that treats image generations as an optimization problem in data space which aims to search for valid images that have high compositional rewards. By innovative designs of the generator parameterization and proper regularization techniques, we train state-of-the-art few-step text-to-image generative models with R0 at scales. Our results challenge the conventional wisdom of diffusion post-training and conditional generation by demonstrating that rewards play a dominant role in scenarios with complex conditions. We hope our findings can contribute to further research into human-centric and reward-centric generation paradigms across the broader field of AIGC. Code is available at https://github.com/Luo-Yihong/R0.
Self-Guidance: Boosting Flow and Diffusion Generation on Their Own
Dec 08, 2024



Proper guidance strategies are essential to get optimal generation results without re-training diffusion and flow-based text-to-image models. However, existing guidances either require specific training or strong inductive biases of neural network architectures, potentially limiting their applications. To address these issues, in this paper, we introduce Self-Guidance (SG), a strong diffusion guidance that neither needs specific training nor requires certain forms of neural network architectures. Different from previous approaches, the Self-Guidance calculates the guidance vectors by measuring the difference between the velocities of two successive diffusion timesteps. Therefore, SG can be readily applied for both conditional and unconditional models with flexible network architectures. We conduct intensive experiments on both text-to-image generation and text-to-video generations across flexible architectures including UNet-based models and diffusion transformer-based models. On current state-of-the-art diffusion models such as Stable Diffusion 3.5 and FLUX, SG significantly boosts the image generation performance in terms of FID, and Human Preference Scores. Moreover, we find that SG has a surprisingly positive effect on the generation of high-quality human bodies such as hands, faces, and arms, showing strong potential to overcome traditional challenges on human body generations with minimal effort. We will release our implementation of SG on SD 3.5 and FLUX models along with this paper.
Schedule On the Fly: Diffusion Time Prediction for Faster and Better Image Generation
Dec 02, 2024



Diffusion and flow models have achieved remarkable successes in various applications such as text-to-image generation. However, these models typically rely on the same predetermined denoising schedules during inference for each prompt, which potentially limits the inference efficiency as well as the flexibility when handling different prompts. In this paper, we argue that the optimal noise schedule should adapt to each inference instance, and introduce the Time Prediction Diffusion Model (TPDM) to accomplish this. TPDM employs a plug-and-play Time Prediction Module (TPM) that predicts the next noise level based on current latent features at each denoising step. We train the TPM using reinforcement learning, aiming to maximize a reward that discounts the final image quality by the number of denoising steps. With such an adaptive scheduler, TPDM not only generates high-quality images that are aligned closely with human preferences but also adjusts the number of denoising steps and time on the fly, enhancing both performance and efficiency. We train TPDMs on multiple diffusion model benchmarks. With Stable Diffusion 3 Medium architecture, TPDM achieves an aesthetic score of 5.44 and a human preference score (HPS) of 29.59, while using around 50% fewer denoising steps to achieve better performance. We will release our best model alongside this paper.
Denoising Fisher Training For Neural Implicit Samplers
Nov 03, 2024



Efficient sampling from un-normalized target distributions is pivotal in scientific computing and machine learning. While neural samplers have demonstrated potential with a special emphasis on sampling efficiency, existing neural implicit samplers still have issues such as poor mode covering behavior, unstable training dynamics, and sub-optimal performances. To tackle these issues, in this paper, we introduce Denoising Fisher Training (DFT), a novel training approach for neural implicit samplers with theoretical guarantees. We frame the training problem as an objective of minimizing the Fisher divergence by deriving a tractable yet equivalent loss function, which marks a unique theoretical contribution to assessing the intractable Fisher divergences. DFT is empirically validated across diverse sampling benchmarks, including two-dimensional synthetic distribution, Bayesian logistic regression, and high-dimensional energy-based models (EBMs). Notably, in experiments with high-dimensional EBMs, our best one-step DFT neural sampler achieves results on par with MCMC methods with up to 200 sampling steps, leading to a substantially greater efficiency over 100 times higher. This result not only demonstrates the superior performance of DFT in handling complex high-dimensional sampling but also sheds light on efficient sampling methodologies across broader applications.