 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedots.tts Technical Report
Jun 05, 2026We present dots.tts, a 2B-parameter continuous autoregressive text-to-speech (TTS) foundation model that models speech in a continuous latent space. Compared with existing continuous autoregressive models, our key innovations are threefold. First, we train an AudioVAE with multiple objectives to build a semantically structured and prediction-friendly continuous speech space. Second, we use full-history conditioning in the flow-matching head to preserve long-range consistency and reduce drift during generation. Third, we apply reward-free self-corrective post-training to the flow-matching head to further improve robustness and acoustic quality. After being trained on a large-scale multilingual corpus, dots.tts achieves the best average performance on Seed-TTS-Eval, with WERs of 0.94%/1.30%/6.60% and SIM scores of 81.0/77.1/79.5 on the zh/en/zh-hard test sets, respectively. Across other benchmarks, dots.tts also consistently demonstrates open-source state-of-the-art performance, exhibiting strong generation stability, voice cloning ability, and emotional expressiveness. For efficient inference, we further apply CFG-aware MeanFlow distillation, enabling low-latency speech generation with first-packet latencies of 85/54 ms in output streaming and dual-streaming modes, respectively. To facilitate reproducible research and practical deployment, we release the training and inference code, together with the pretrained, post-trained, and MeanFlow-distilled checkpoints, under the Apache 2.0 license.
HoliTok:A Coutinuous Holistic Tokenization with Robust Dual Capabilities of Speech Generation and Understanding
May 28, 2026Unified speech foundation models require a holistic tokenization space that is both learnable by language models and decodable into high-quality waveforms. Existing speech tokenizers, however, often fail to satisfy these requirements simultaneously, leading to increased architectural complexity and more involved training designs. We propose HoliTok, a continuous Holistic speech Tokenization model designed for unified generation-understanding modeling. HoliTok encodes 48~kHz speech into a compact 25~Hz sequence of 128-dimensional latents. It is trained with a progressive strategy that jointly preserves signal-level fidelity, incorporates semantic information, and maintains strong latent learnability. Based on this tokenization, we build a unified AR+DiT model for speech synthesis and recognition, where the same latent sequence supports both generation-specific and unified generation-understanding tasks. Experiments show that HoliTok achieves competitive reconstruction fidelity, improves generative learnability for high-quality and controllable synthesis, and, among the evaluated representations, is the only one that operates robustly in our unified generation-understanding architecture without additional optimization tricks. These results suggest that HoliTok serves as an effective speech tokenizer and a foundational representation interface for unified spoken language modeling. The code is available at: https://github.com/bovod-sjtu/HoliTok.
Autoregressive Visual Generation Needs a Prologue
May 07, 2026In this work, we propose Prologue, an approach to bridging the reconstruction-generation gap in autoregressive (AR) image generation. Instead of modifying visual tokens to satisfy both reconstruction and generation, Prologue generates a small set of prologue tokens prepended to the visual token sequence. These prologue tokens are trained exclusively with the AR cross-entropy (CE) loss, while visual tokens remain dedicated to reconstruction. This decoupled design lets us optimize generation through the AR model's true distribution without affecting reconstruction quality, which we further formalize from an ELBO perspective. On ImageNet 256x256, Prologue-Base reduces gFID from 21.01 to 10.75 without classifier-free guidance while keeping reconstruction almost unchanged; Prologue-Large reaches a competitive rFID of 0.99 and gFID of 1.46 using a standard AR model without auxiliary semantic supervision. Interestingly, driven only by AR gradients, prologue tokens exhibit emergent semantic structure: linear probing on 16 prologue tokens reaches 35.88% Top-1, far above the 23.71% of the first 16 tokens from a standard tokenizer; resampling with fixed prologue tokens preserves a similar high-level semantic layout. Our results suggest a new direction: generation quality can be improved by introducing a separate learned generative representation while leaving the original representation intact.
Taming the Entropy Cliff: Variable Codebook Size Quantization for Autoregressive Visual Generation
May 07, 2026Most discrete visual tokenizers rely on a default design: every position in the sequence shares the same codebook. Researchers try to scale the codebook size $K$ to get better reconstruction performance. Such a constant-codebook design hits a fundamental information-theoretic limit. We observe that the per-position conditional entropy of the training set decays so quickly along the sequence that, after a few positions, the conditional distribution becomes essentially deterministic. On ImageNet with $K=16384$, this happens within only 2 out of 256 positions, turning the remaining 254 into a memorization problem. We call this phenomenon the Entropy Cliff and formalize it with a simple expression: $t^{*} = \lceil \log_2 N / \log_2 K \rceil$. Interestingly, this phenomenon is not observed in language, as its natural structure keeps the effective entropy per position well below the codebook capacity. To address this, we propose Variable Codebook Size Quantization (VCQ), where the codebook size $K_t$ grows monotonically along the sequence from $K_{\min}=2$ to $K_{\max}$, leaving the loss function, parameter count, and AR training procedure unchanged. With a vanilla autoregressive Transformer and standard next-token prediction, a base version of VCQ reduces gFID w/o CFG from 27.98 to 14.80 on ImageNet $256\times256$ over the baseline. Scaled up, it reaches gFID 1.71 with 684M autoregressive parameters, without any extra training techniques such as semantic regularization or causal alignment. The extreme information bottleneck at $K_{\min}=2$ naturally induces a coarse-to-fine semantic hierarchy: a linear probe on only the first 10 tokens reaches 43.8% top-1 accuracy on ImageNet, compared to 27.1% for uniform codebooks. Ultimately, these results show that what matters is not only the total capacity of the codebook, but also how that capacity is distributed and organized.
Multimodal OCR: Parse Anything from Documents
Mar 13, 2026We present Multimodal OCR (MOCR), a document parsing paradigm that jointly parses text and graphics into unified textual representations. Unlike conventional OCR systems that focus on text recognition and leave graphical regions as cropped pixels, our method, termed dots.mocr, treats visual elements such as charts, diagrams, tables, and icons as first-class parsing targets, enabling systems to parse documents while preserving semantic relationships across elements. It offers several advantages: (1) it reconstructs both text and graphics as structured outputs, enabling more faithful document reconstruction; (2) it supports end-to-end training over heterogeneous document elements, allowing models to exploit semantic relations between textual and visual components; and (3) it converts previously discarded graphics into reusable code-level supervision, unlocking multimodal supervision embedded in existing documents. To make this paradigm practical at scale, we build a comprehensive data engine from PDFs, rendered webpages, and native SVG assets, and train a compact 3B-parameter model through staged pretraining and supervised fine-tuning. We evaluate dots.mocr from two perspectives: document parsing and structured graphics parsing. On document parsing benchmarks, it ranks second only to Gemini 3 Pro on our OCR Arena Elo leaderboard, surpasses existing open-source document parsing systems, and sets a new state of the art of 83.9 on olmOCR Bench. On structured graphics parsing, dots.mocr achieves higher reconstruction quality than Gemini 3 Pro across image-to-SVG benchmarks, demonstrating strong performance on charts, UI layouts, scientific figures, and chemical diagrams. These results show a scalable path toward building large-scale image-to-code corpora for multimodal pretraining. Code and models are publicly available at https://github.com/rednote-hilab/dots.mocr.
Uni-Instruct: One-step Diffusion Model through Unified Diffusion Divergence Instruction
May 27, 2025In this paper, we unify more than 10 existing one-step diffusion distillation approaches, such as Diff-Instruct, DMD, SIM, SiD, $f$-distill, etc, inside a theory-driven framework which we name the \textbf{\emph{Uni-Instruct}}. Uni-Instruct is motivated by our proposed diffusion expansion theory of the $f$-divergence family. Then we introduce key theories that overcome the intractability issue of the original expanded $f$-divergence, resulting in an equivalent yet tractable loss that effectively trains one-step diffusion models by minimizing the expanded $f$-divergence family. The novel unification introduced by Uni-Instruct not only offers new theoretical contributions that help understand existing approaches from a high-level perspective but also leads to state-of-the-art one-step diffusion generation performances. On the CIFAR10 generation benchmark, Uni-Instruct achieves record-breaking Frechet Inception Distance (FID) values of \textbf{\emph{1.46}} for unconditional generation and \textbf{\emph{1.38}} for conditional generation. On the ImageNet-$64\times 64$ generation benchmark, Uni-Instruct achieves a new SoTA one-step generation FID of \textbf{\emph{1.02}}, which outperforms its 79-step teacher diffusion with a significant improvement margin of 1.33 (1.02 vs 2.35). We also apply Uni-Instruct on broader tasks like text-to-3D generation. For text-to-3D generation, Uni-Instruct gives decent results, which slightly outperforms previous methods, such as SDS and VSD, in terms of both generation quality and diversity. Both the solid theoretical and empirical contributions of Uni-Instruct will potentially help future studies on one-step diffusion distillation and knowledge transferring of diffusion models.
Diff-Instruct*: Towards Human-Preferred One-step Text-to-image Generative Models
Oct 28, 2024
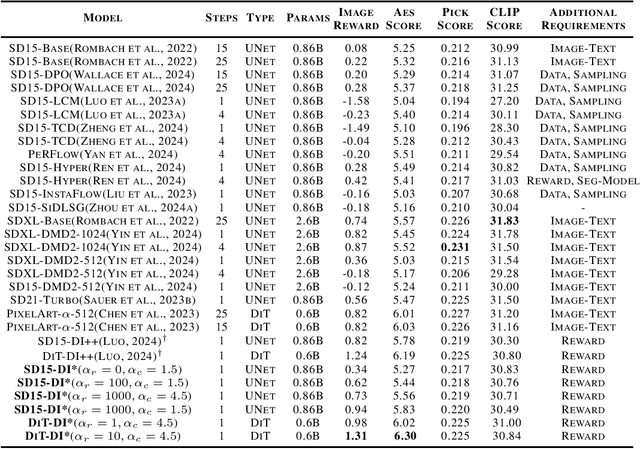

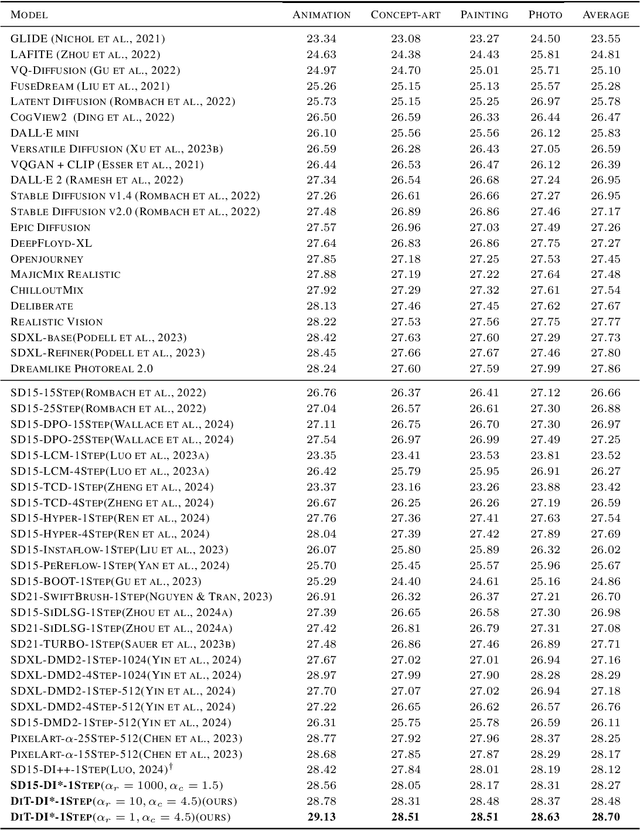
In this paper, we introduce the Diff-Instruct*(DI*), a data-free approach for building one-step text-to-image generative models that align with human preference while maintaining the ability to generate highly realistic images. We frame human preference alignment as online reinforcement learning using human feedback (RLHF), where the goal is to maximize the reward function while regularizing the generator distribution to remain close to a reference diffusion process. Unlike traditional RLHF approaches, which rely on the KL divergence for regularization, we introduce a novel score-based divergence regularization, which leads to significantly better performances. Although the direct calculation of this divergence remains intractable, we demonstrate that we can efficiently compute its \emph{gradient} by deriving an equivalent yet tractable loss function. Remarkably, with Stable Diffusion V1.5 as the reference diffusion model, DI* outperforms \emph{all} previously leading models by a large margin. When using the 0.6B PixelArt-$\alpha$ model as the reference diffusion, DI* achieves a new record Aesthetic Score of 6.30 and an Image Reward of 1.31 with only a single generation step, almost doubling the scores of the rest of the models with similar sizes. It also achieves an HPSv2 score of 28.70, establishing a new state-of-the-art benchmark. We also observe that DI* can improve the layout and enrich the colors of generated images.
Untie the Knots: An Efficient Data Augmentation Strategy for Long-Context Pre-Training in Language Models
Sep 07, 2024



Large language models (LLM) have prioritized expanding the context window from which models can incorporate more information. However, training models to handle long contexts presents significant challenges. These include the scarcity of high-quality natural long-context data, the potential for performance degradation on short-context tasks, and the reduced training efficiency associated with attention mechanisms. In this paper, we introduce Untie the Knots (\textbf{UtK}), a novel data augmentation strategy employed during the continue pre-training phase, designed to efficiently enable LLMs to gain long-context capabilities without the need to modify the existing data mixture. In particular, we chunk the documents, shuffle the chunks, and create a complex and knotted structure of long texts; LLMs are then trained to untie these knots and identify relevant segments within seemingly chaotic token sequences. This approach greatly improves the model's performance by accurately attending to relevant information in long context and the training efficiency is also largely increased. We conduct extensive experiments on models with 7B and 72B parameters, trained on 20 billion tokens, demonstrating that UtK achieves 75\% and 84.5\% accurracy on RULER at 128K context length, significantly outperforming other long context strategies. The trained models will open-source for further research.
Predicting Drug Solubility Using Different Machine Learning Methods -- Linear Regression Model with Extracted Chemical Features vs Graph Convolutional Neural Network
Aug 23, 2023



Predicting the solubility of given molecules is an important task in the pharmaceutical industry, and consequently this is a well-studied topic. In this research, we revisited this problem with the advantage of modern computing resources. We applied two machine learning models, a linear regression model and a graph convolutional neural network model, on multiple experimental datasets. Both methods can make reasonable predictions while the GCNN model had the best performance. However, the current GCNN model is a black box, while feature importance analysis from the linear regression model offers more insights into the underlying chemical influences. Using the linear regression model, we show how each functional group affects the overall solubility. Ultimately, knowing how chemical structure influences chemical properties is crucial when designing new drugs. Future work should aim to combine the high performance of GCNNs with the interpretability of linear regression, unlocking new advances in next generation high throughput screening.
Developing novel ligands with enhanced binding affinity for the sphingosine 1-phosphate receptor 1 using machine learning
Jul 29, 2023Multiple sclerosis (MS) is a debilitating neurological disease affecting nearly one million people in the United States. Sphingosine-1-phosphate receptor 1, or S1PR1, is a protein target for MS. Siponimod, a ligand of S1PR1, was approved by the FDA in 2019 for MS treatment, but there is a demonstrated need for better therapies. To this end, we finetuned an autoencoder machine learning model that converts chemical formulas into mathematical vectors and generated over 500 molecular variants based on siponimod, out of which 25 compounds had higher predicted binding affinity to S1PR1. The model was able to generate these ligands in just under one hour. Filtering these compounds led to the discovery of six promising candidates with good drug-like properties and ease of synthesis. Furthermore, by analyzing the binding interactions for these ligands, we uncovered several chemical properties that contribute to high binding affinity to S1PR1. This study demonstrates that machine learning can accelerate the drug discovery process and reveal new insights into protein-drug interactions.