 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEquilibrium Reasoners: Learning Attractors Enables Scalable Reasoning
May 20, 2026Scaling test-time compute by iteratively updating a latent state has emerged as a powerful paradigm for reasoning. Yet the internal mechanisms that enable these iterative models to generalize beyond memorized patterns remain unclear. We hypothesize that generalizable reasoning arises from learning task-conditioned attractors: latent dynamical systems whose stable fixed points correspond to valid solutions. We formalize this process through Equilibrium Reasoners (EqR), which enable test-time scaling without external verifiers or task-specific priors. EqR scales internal dynamics along two axes: depth, by running more iterations, and breadth, by aggregating stochastic trajectories from multiple initializations. Empirically, gains from test-time scaling are tightly coupled with stronger convergence toward solution-aligned attractors. This attractor perspective allows neural networks to adaptively allocate test-time compute based on task difficulty. While simple cases converge within 1 to 5 iteration steps, harder cases benefit from massive test-time scaling. By unrolling up to the equivalent of 40,000 layers, scalable latent reasoning boosts accuracy from 2.6% for feedforward models to over 99% on Sudoku-Extreme. These results suggest that learned attractor landscapes provide a useful mechanistic lens for understanding scalable reasoning in iterative latent models.
One-step Latent-free Image Generation with Pixel Mean Flows
Jan 29, 2026Modern diffusion/flow-based models for image generation typically exhibit two core characteristics: (i) using multi-step sampling, and (ii) operating in a latent space. Recent advances have made encouraging progress on each aspect individually, paving the way toward one-step diffusion/flow without latents. In this work, we take a further step towards this goal and propose "pixel MeanFlow" (pMF). Our core guideline is to formulate the network output space and the loss space separately. The network target is designed to be on a presumed low-dimensional image manifold (i.e., x-prediction), while the loss is defined via MeanFlow in the velocity space. We introduce a simple transformation between the image manifold and the average velocity field. In experiments, pMF achieves strong results for one-step latent-free generation on ImageNet at 256x256 resolution (2.22 FID) and 512x512 resolution (2.48 FID), filling a key missing piece in this regime. We hope that our study will further advance the boundaries of diffusion/flow-based generative models.
RBench-V: A Primary Assessment for Visual Reasoning Models with Multi-modal Outputs
May 22, 2025The rapid advancement of native multi-modal models and omni-models, exemplified by GPT-4o, Gemini, and o3, with their capability to process and generate content across modalities such as text and images, marks a significant milestone in the evolution of intelligence. Systematic evaluation of their multi-modal output capabilities in visual thinking processes (also known as multi-modal chain of thought, M-CoT) becomes critically important. However, existing benchmarks for evaluating multi-modal models primarily focus on assessing multi-modal inputs and text-only reasoning while neglecting the importance of reasoning through multi-modal outputs. In this paper, we present a benchmark, dubbed RBench-V, designed to assess models' vision-indispensable reasoning abilities. To construct RBench-V, we carefully hand-pick 803 questions covering math, physics, counting, and games. Unlike previous benchmarks that typically specify certain input modalities, RBench-V presents problems centered on multi-modal outputs, which require image manipulation such as generating novel images and constructing auxiliary lines to support the reasoning process. We evaluate numerous open- and closed-source models on RBench-V, including o3, Gemini 2.5 Pro, Qwen2.5-VL, etc. Even the best-performing model, o3, achieves only 25.8% accuracy on RBench-V, far below the human score of 82.3%, highlighting that current models struggle to leverage multi-modal reasoning. Data and code are available at https://evalmodels.github.io/rbenchv
Mean Flows for One-step Generative Modeling
May 19, 2025We propose a principled and effective framework for one-step generative modeling. We introduce the notion of average velocity to characterize flow fields, in contrast to instantaneous velocity modeled by Flow Matching methods. A well-defined identity between average and instantaneous velocities is derived and used to guide neural network training. Our method, termed the MeanFlow model, is self-contained and requires no pre-training, distillation, or curriculum learning. MeanFlow demonstrates strong empirical performance: it achieves an FID of 3.43 with a single function evaluation (1-NFE) on ImageNet 256x256 trained from scratch, significantly outperforming previous state-of-the-art one-step diffusion/flow models. Our study substantially narrows the gap between one-step diffusion/flow models and their multi-step predecessors, and we hope it will motivate future research to revisit the foundations of these powerful models.
R-Bench: Graduate-level Multi-disciplinary Benchmarks for LLM & MLLM Complex Reasoning Evaluation
May 04, 2025Reasoning stands as a cornerstone of intelligence, enabling the synthesis of existing knowledge to solve complex problems. Despite remarkable progress, existing reasoning benchmarks often fail to rigorously evaluate the nuanced reasoning capabilities required for complex, real-world problemsolving, particularly in multi-disciplinary and multimodal contexts. In this paper, we introduce a graduate-level, multi-disciplinary, EnglishChinese benchmark, dubbed as Reasoning Bench (R-Bench), for assessing the reasoning capability of both language and multimodal models. RBench spans 1,094 questions across 108 subjects for language model evaluation and 665 questions across 83 subjects for multimodal model testing in both English and Chinese. These questions are meticulously curated to ensure rigorous difficulty calibration, subject balance, and crosslinguistic alignment, enabling the assessment to be an Olympiad-level multi-disciplinary benchmark. We evaluate widely used models, including OpenAI o1, GPT-4o, DeepSeek-R1, etc. Experimental results indicate that advanced models perform poorly on complex reasoning, especially multimodal reasoning. Even the top-performing model OpenAI o1 achieves only 53.2% accuracy on our multimodal evaluation. Data and code are made publicly available at here.
Diff-Instruct*: Towards Human-Preferred One-step Text-to-image Generative Models
Oct 28, 2024
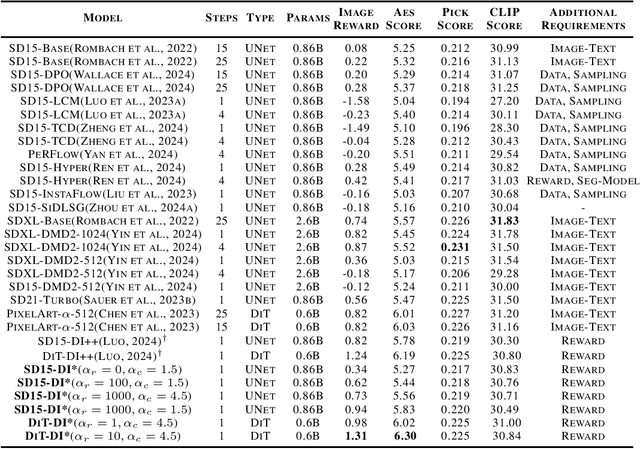

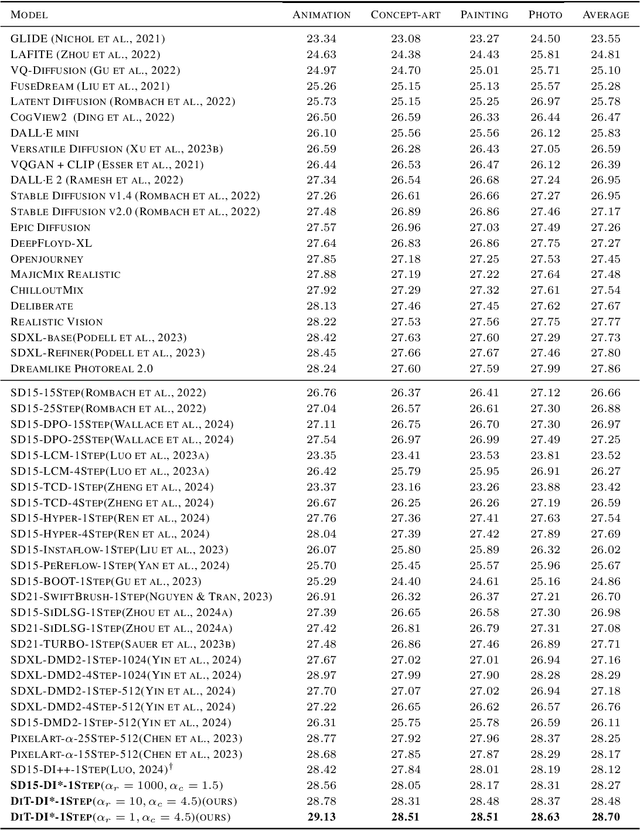
In this paper, we introduce the Diff-Instruct*(DI*), a data-free approach for building one-step text-to-image generative models that align with human preference while maintaining the ability to generate highly realistic images. We frame human preference alignment as online reinforcement learning using human feedback (RLHF), where the goal is to maximize the reward function while regularizing the generator distribution to remain close to a reference diffusion process. Unlike traditional RLHF approaches, which rely on the KL divergence for regularization, we introduce a novel score-based divergence regularization, which leads to significantly better performances. Although the direct calculation of this divergence remains intractable, we demonstrate that we can efficiently compute its \emph{gradient} by deriving an equivalent yet tractable loss function. Remarkably, with Stable Diffusion V1.5 as the reference diffusion model, DI* outperforms \emph{all} previously leading models by a large margin. When using the 0.6B PixelArt-$\alpha$ model as the reference diffusion, DI* achieves a new record Aesthetic Score of 6.30 and an Image Reward of 1.31 with only a single generation step, almost doubling the scores of the rest of the models with similar sizes. It also achieves an HPSv2 score of 28.70, establishing a new state-of-the-art benchmark. We also observe that DI* can improve the layout and enrich the colors of generated images.
Flow Generator Matching
Oct 25, 2024



In the realm of Artificial Intelligence Generated Content (AIGC), flow-matching models have emerged as a powerhouse, achieving success due to their robust theoretical underpinnings and solid ability for large-scale generative modeling. These models have demonstrated state-of-the-art performance, but their brilliance comes at a cost. The process of sampling from these models is notoriously demanding on computational resources, as it necessitates the use of multi-step numerical ordinary differential equations (ODEs). Against this backdrop, this paper presents a novel solution with theoretical guarantees in the form of Flow Generator Matching (FGM), an innovative approach designed to accelerate the sampling of flow-matching models into a one-step generation, while maintaining the original performance. On the CIFAR10 unconditional generation benchmark, our one-step FGM model achieves a new record Fr\'echet Inception Distance (FID) score of 3.08 among few-step flow-matching-based models, outperforming original 50-step flow-matching models. Furthermore, we use the FGM to distill the Stable Diffusion 3, a leading text-to-image flow-matching model based on the MM-DiT architecture. The resulting MM-DiT-FGM one-step text-to-image model demonstrates outstanding industry-level performance. When evaluated on the GenEval benchmark, MM-DiT-FGM has delivered remarkable generating qualities, rivaling other multi-step models in light of the efficiency of a single generation step.
Stable Consistency Tuning: Understanding and Improving Consistency Models
Oct 24, 2024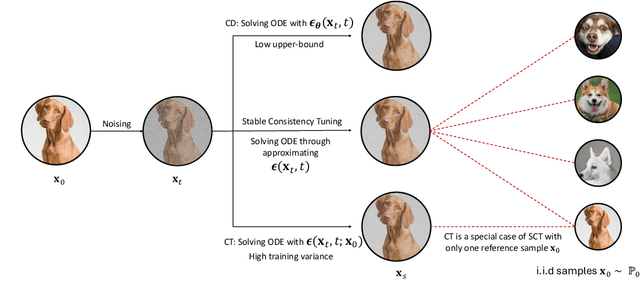

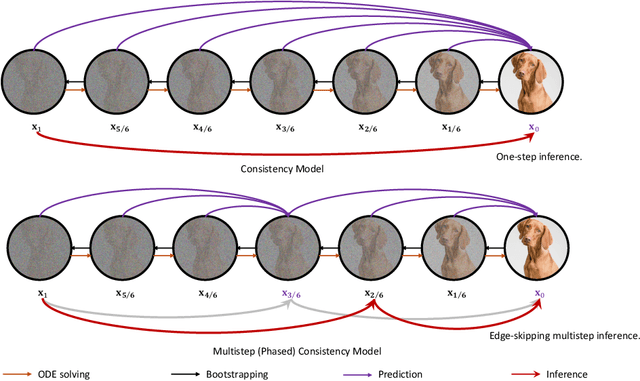
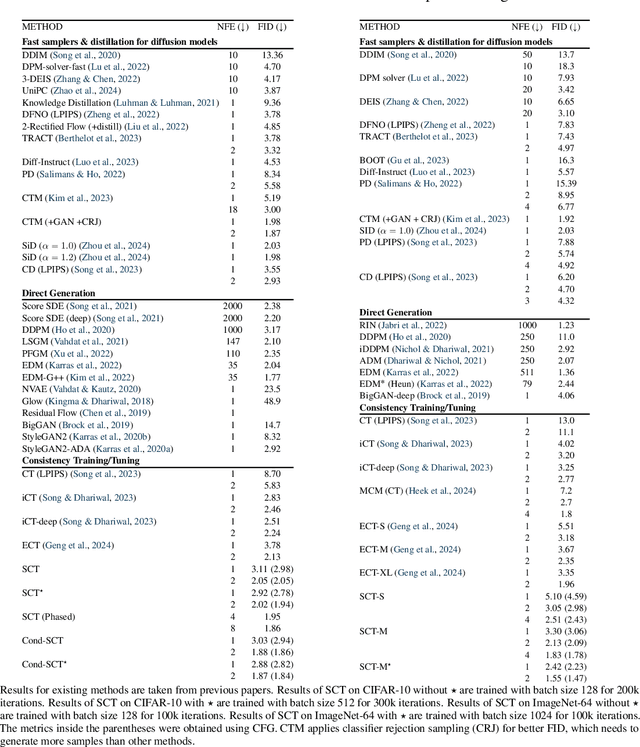
Diffusion models achieve superior generation quality but suffer from slow generation speed due to the iterative nature of denoising. In contrast, consistency models, a new generative family, achieve competitive performance with significantly faster sampling. These models are trained either through consistency distillation, which leverages pretrained diffusion models, or consistency training/tuning directly from raw data. In this work, we propose a novel framework for understanding consistency models by modeling the denoising process of the diffusion model as a Markov Decision Process (MDP) and framing consistency model training as the value estimation through Temporal Difference~(TD) Learning. More importantly, this framework allows us to analyze the limitations of current consistency training/tuning strategies. Built upon Easy Consistency Tuning (ECT), we propose Stable Consistency Tuning (SCT), which incorporates variance-reduced learning using the score identity. SCT leads to significant performance improvements on benchmarks such as CIFAR-10 and ImageNet-64. On ImageNet-64, SCT achieves 1-step FID 2.42 and 2-step FID 1.55, a new SoTA for consistency models.
One-Step Diffusion Distillation through Score Implicit Matching
Oct 22, 2024
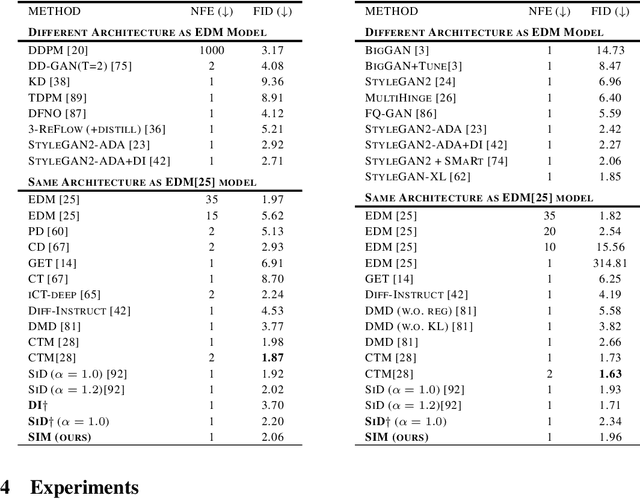


Despite their strong performances on many generative tasks, diffusion models require a large number of sampling steps in order to generate realistic samples. This has motivated the community to develop effective methods to distill pre-trained diffusion models into more efficient models, but these methods still typically require few-step inference or perform substantially worse than the underlying model. In this paper, we present Score Implicit Matching (SIM) a new approach to distilling pre-trained diffusion models into single-step generator models, while maintaining almost the same sample generation ability as the original model as well as being data-free with no need of training samples for distillation. The method rests upon the fact that, although the traditional score-based loss is intractable to minimize for generator models, under certain conditions we can efficiently compute the gradients for a wide class of score-based divergences between a diffusion model and a generator. SIM shows strong empirical performances for one-step generators: on the CIFAR10 dataset, it achieves an FID of 2.06 for unconditional generation and 1.96 for class-conditional generation. Moreover, by applying SIM to a leading transformer-based diffusion model, we distill a single-step generator for text-to-image (T2I) generation that attains an aesthetic score of 6.42 with no performance decline over the original multi-step counterpart, clearly outperforming the other one-step generators including SDXL-TURBO of 5.33, SDXL-LIGHTNING of 5.34 and HYPER-SDXL of 5.85. We will release this industry-ready one-step transformer-based T2I generator along with this paper.
* Accepted by NeurIPS 2024
Consistency Models Made Easy
Jun 20, 2024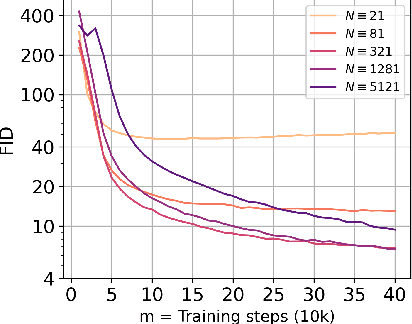
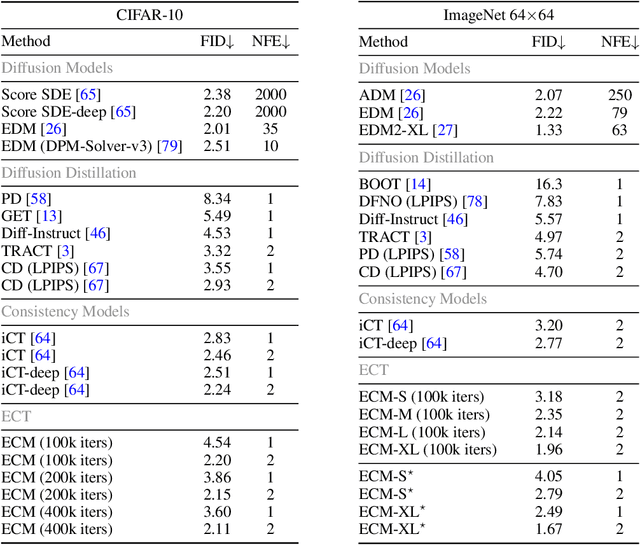
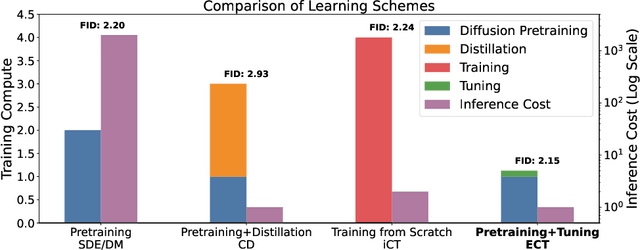

Consistency models (CMs) are an emerging class of generative models that offer faster sampling than traditional diffusion models. CMs enforce that all points along a sampling trajectory are mapped to the same initial point. But this target leads to resource-intensive training: for example, as of 2024, training a SoTA CM on CIFAR-10 takes one week on 8 GPUs. In this work, we propose an alternative scheme for training CMs, vastly improving the efficiency of building such models. Specifically, by expressing CM trajectories via a particular differential equation, we argue that diffusion models can be viewed as a special case of CMs with a specific discretization. We can thus fine-tune a consistency model starting from a pre-trained diffusion model and progressively approximate the full consistency condition to stronger degrees over the training process. Our resulting method, which we term Easy Consistency Tuning (ECT), achieves vastly improved training times while indeed improving upon the quality of previous methods: for example, ECT achieves a 2-step FID of 2.73 on CIFAR10 within 1 hour on a single A100 GPU, matching Consistency Distillation trained of hundreds of GPU hours. Owing to this computational efficiency, we investigate the scaling law of CMs under ECT, showing that they seem to obey classic power law scaling, hinting at their ability to improve efficiency and performance at larger scales. Code (https://github.com/locuslab/ect) is available.