 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiff-Instruct*: Towards Human-Preferred One-step Text-to-image Generative Models
Paper and Code
Oct 28, 2024
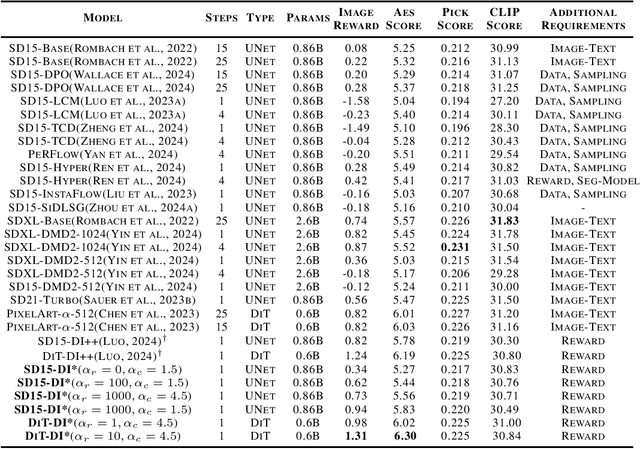

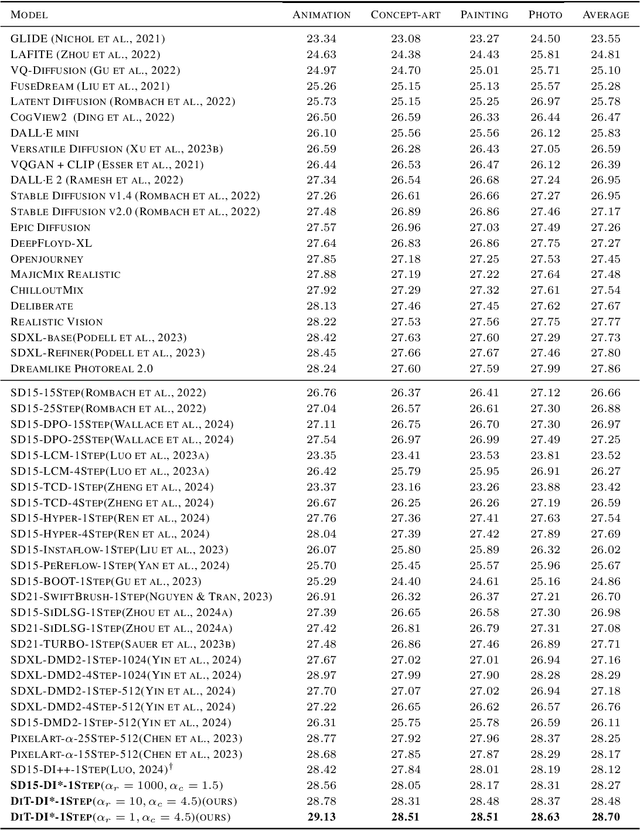
In this paper, we introduce the Diff-Instruct*(DI*), a data-free approach for building one-step text-to-image generative models that align with human preference while maintaining the ability to generate highly realistic images. We frame human preference alignment as online reinforcement learning using human feedback (RLHF), where the goal is to maximize the reward function while regularizing the generator distribution to remain close to a reference diffusion process. Unlike traditional RLHF approaches, which rely on the KL divergence for regularization, we introduce a novel score-based divergence regularization, which leads to significantly better performances. Although the direct calculation of this divergence remains intractable, we demonstrate that we can efficiently compute its \emph{gradient} by deriving an equivalent yet tractable loss function. Remarkably, with Stable Diffusion V1.5 as the reference diffusion model, DI* outperforms \emph{all} previously leading models by a large margin. When using the 0.6B PixelArt-$\alpha$ model as the reference diffusion, DI* achieves a new record Aesthetic Score of 6.30 and an Image Reward of 1.31 with only a single generation step, almost doubling the scores of the rest of the models with similar sizes. It also achieves an HPSv2 score of 28.70, establishing a new state-of-the-art benchmark. We also observe that DI* can improve the layout and enrich the colors of generated images.