 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNITP: Next Implicit Token Prediction for LLM Pre-training
May 24, 2026Standard next-token prediction (NTP) supervises language models solely through discrete labels in the output logit space. We argue that this sparse one-hot supervision leaves the latent representation space under-constrained, allowing hidden states to drift into degenerate and anisotropic configurations that can limit generalization. To address this issue, we propose Next Implicit Token Prediction (NITP), which augments discrete prediction with dense continuous supervision directly in the representation space. NITP trains the model to predict the implicit semantic content of the next token, using shallow-layer representations from the same model as stable self-supervised targets. We provide theoretical analysis showing that NITP regularizes the optimization landscape by mitigating under-constrained degrees of freedom and encouraging a compact, structured representation geometry. Empirically, across dense and MoE models ranging from 0.5B to 9B parameters, NITP consistently improves downstream performance with negligible computational overhead. On a 9B MoE model, NITP achieves a 5.7% absolute improvement on MMLU-Pro, along with gains of 6.4% on C3 and 4.3% on CommonsenseQA, with approximately 2% additional training FLOPs and no additional inference cost. Our implementation is available at https://github.com/aHapBean/NITP.
SigLoMa: Learning Open-World Quadrupedal Loco-Manipulation from Ego-Centric Vision
May 05, 2026Designing an open-world quadrupedal loco-manipulation system is highly challenging. Traditional reinforcement learning frameworks utilizing exteroception often suffer from extreme sample inefficiency and massive sim-to-real gaps. Furthermore, the inherent latency of visual tracking fundamentally conflicts with the high-frequency demands of precise floating-base control. Consequently, existing systems lean heavily on expensive external motion capture and off-board computation. To eliminate these dependencies, we present SigLoMa, a fully onboard, ego-centric vision-based pick-and-place framework. At the core of SigLoMa is the introduction of Sigma Points, a lightweight geometric representation for exteroception that guarantees high scalability and native sim-to-real alignment. To bridge the frequency divide between slow perception and fast control, we design an ego-centric Kalman Filter to provide robust, high-rate state estimation. On the learning front, we alleviate sample inefficiency via an Active Sampling Curriculum guided by Hint Poses, and tackle the robot's structural visual blind spots using temporal encoding coupled with simulated random-walk drift. Real-world experiments validate that, relying solely on a 5Hz (200 ms latency) open-vocabulary detector, SigLoMa successfully executes dynamic loco-manipulation across multiple tasks, achieving performance comparable to expert human teleoperation.
Tackling Length Inflation Without Trade-offs: Group Relative Reward Rescaling for Reinforcement Learning
Mar 11, 2026Reinforcement learning significantly enhances LLM capabilities but suffers from a critical issue: length inflation, where models adopt verbosity or inefficient reasoning to maximize rewards. Prior approaches struggle to address this challenge in a general and lossless manner, primarily because additive penalties introduce a compensatory effect that creates optimization shortcuts, while heuristic gating strategies lack generality beyond binary feedback. To bridge this gap, we present Group Relative Reward Rescaling (GR$^3$), which reframes length control as a multiplicative rescaling paradigm, effectively establishing a generalized, continuous, and reward-dependent gating mechanism. To further ensure lossless optimization, we incorporate group-relative regularization and advantage-aware calibration, which dynamically adapt length budgets to instance difficulty and preserve the advantage signal of high-quality trajectories. Empirically, across both RLHF and RLVR settings, GR$^3$~maintains training dynamics and downstream performance comparable to standard GRPO while significantly mitigating length inflation, outperforming state-of-the-art length-regularized baselines.
SEA-Nav: Efficient Policy Learning for Safe and Agile Quadruped Navigation in Cluttered Environments
Mar 10, 2026Efficiently training quadruped robot navigation in densely cluttered environments remains a significant challenge. Existing methods are either limited by a lack of safety and agility in simple obstacle distributions or suffer from slow locomotion in complex environments, often requiring excessively long training phases. To this end, we propose SEA-Nav (Safe, Efficient, and Agile Navigation), a reinforcement learning framework for quadruped navigation. Within diverse and dense obstacle environments, a differentiable control barrier function (CBF)-based shield constraints the navigation policy to output safe velocity commands. An adaptive collision replay mechanism and hazardous exploration rewards are introduced to increase the probability of learning from critical experiences, guiding efficient exploration and exploitation. Finally, kinematic action constraints are incorporated to ensure safe velocity commands, facilitating successful physical deployment. To the best of our knowledge, this is the first approach that achieves highly challenging quadruped navigation in the real world with minute-level training time.
JTok: On Token Embedding as another Axis of Scaling Law via Joint Token Self-modulation
Jan 31, 2026LLMs have traditionally scaled along dense dimensions, where performance is coupled with near-linear increases in computational cost. While MoE decouples capacity from compute, it introduces large memory overhead and hardware efficiency challenges. To overcome these, we propose token-indexed parameters as a novel, orthogonal scaling axis that decouple model capacity from FLOPs. Specifically, we introduce Joint-Token (JTok) and Mixture of Joint-Token (JTok-M), which augment Transformer layers with modulation vectors retrieved from auxiliary embedding tables. These vectors modulate the backbone via lightweight, element-wise operations, incurring negligible FLOPs overhead. Extensive experiments on both dense and MoE backbones, spanning from 650M (190M + 460M embedding) to 61B (17B + 44B embedding) total parameters, demonstrate that our approach consistently reduces validation loss and significantly improves downstream task performance (e.g., +4.1 on MMLU, +8.3 on ARC, +8.9 on CEval). Rigorous isoFLOPs analysis further confirms that JTok-M fundamentally shifts the quality-compute Pareto frontier, achieving comparable model quality with 35% less compute relative to vanilla MoE architectures, and we validate that token-indexed parameters exhibit a predictable power-law scaling behavior. Moreover, our efficient implementation ensures that the overhead introduced by JTok and JTok-M remains marginal.
LongBench Pro: A More Realistic and Comprehensive Bilingual Long-Context Evaluation Benchmark
Jan 06, 2026The rapid expansion of context length in large language models (LLMs) has outpaced existing evaluation benchmarks. Current long-context benchmarks often trade off scalability and realism: synthetic tasks underrepresent real-world complexity, while fully manual annotation is costly to scale to extreme lengths and diverse scenarios. We present LongBench Pro, a more realistic and comprehensive bilingual benchmark of 1,500 naturally occurring long-context samples in English and Chinese spanning 11 primary tasks and 25 secondary tasks, with input lengths from 8k to 256k tokens. LongBench Pro supports fine-grained analysis with task-specific metrics and a multi-dimensional taxonomy of context requirement (full vs. partial dependency), length (six levels), and difficulty (four levels calibrated by model performance). To balance quality with scalability, we propose a Human-Model Collaborative Construction pipeline: frontier LLMs draft challenging questions and reference answers, along with design rationales and solution processes, to reduce the cost of expert verification. Experts then rigorously validate correctness and refine problematic cases. Evaluating 46 widely used long-context LLMs on LongBench Pro yields three findings: (1) long-context optimization contributes more to long-context comprehension than parameter scaling; (2) effective context length is typically shorter than the claimed context length, with pronounced cross-lingual misalignment; and (3) the "thinking" paradigm helps primarily models trained with native reasoning, while mixed-thinking designs offer a promising Pareto trade-off. In summary, LongBench Pro provides a robust testbed for advancing long-context understanding.
Coupled Variational Reinforcement Learning for Language Model General Reasoning
Dec 14, 2025While reinforcement learning have achieved impressive progress in language model reasoning, they are constrained by the requirement for verifiable rewards. Recent verifier-free RL methods address this limitation by utilizing the intrinsic probabilities of LLMs generating reference answers as reward signals. However, these approaches typically sample reasoning traces conditioned only on the question. This design decouples reasoning-trace sampling from answer information, leading to inefficient exploration and incoherence between traces and final answers. In this paper, we propose \textit{\b{Co}upled \b{V}ariational \b{R}einforcement \b{L}earning} (CoVRL), which bridges variational inference and reinforcement learning by coupling prior and posterior distributions through a hybrid sampling strategy. By constructing and optimizing a composite distribution that integrates these two distributions, CoVRL enables efficient exploration while preserving strong thought-answer coherence. Extensive experiments on mathematical and general reasoning benchmarks show that CoVRL improves performance by 12.4\% over the base model and achieves an additional 2.3\% improvement over strong state-of-the-art verifier-free RL baselines, providing a principled framework for enhancing the general reasoning capabilities of language models.
LiteLong: Resource-Efficient Long-Context Data Synthesis for LLMs
Sep 19, 2025
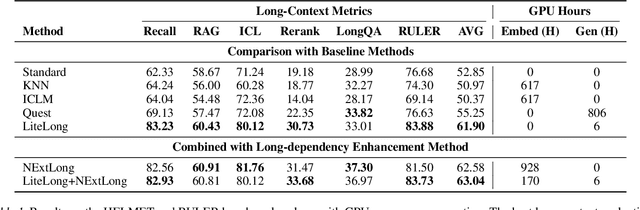


High-quality long-context data is essential for training large language models (LLMs) capable of processing extensive documents, yet existing synthesis approaches using relevance-based aggregation face challenges of computational efficiency. We present LiteLong, a resource-efficient method for synthesizing long-context data through structured topic organization and multi-agent debate. Our approach leverages the BISAC book classification system to provide a comprehensive hierarchical topic organization, and then employs a debate mechanism with multiple LLMs to generate diverse, high-quality topics within this structure. For each topic, we use lightweight BM25 retrieval to obtain relevant documents and concatenate them into 128K-token training samples. Experiments on HELMET and Ruler benchmarks demonstrate that LiteLong achieves competitive long-context performance and can seamlessly integrate with other long-dependency enhancement methods. LiteLong makes high-quality long-context data synthesis more accessible by reducing both computational and data engineering costs, facilitating further research in long-context language training.
Flow-Anything: Learning Real-World Optical Flow Estimation from Large-Scale Single-view Images
Jun 09, 2025Optical flow estimation is a crucial subfield of computer vision, serving as a foundation for video tasks. However, the real-world robustness is limited by animated synthetic datasets for training. This introduces domain gaps when applied to real-world applications and limits the benefits of scaling up datasets. To address these challenges, we propose \textbf{Flow-Anything}, a large-scale data generation framework designed to learn optical flow estimation from any single-view images in the real world. We employ two effective steps to make data scaling-up promising. First, we convert a single-view image into a 3D representation using advanced monocular depth estimation networks. This allows us to render optical flow and novel view images under a virtual camera. Second, we develop an Object-Independent Volume Rendering module and a Depth-Aware Inpainting module to model the dynamic objects in the 3D representation. These two steps allow us to generate realistic datasets for training from large-scale single-view images, namely \textbf{FA-Flow Dataset}. For the first time, we demonstrate the benefits of generating optical flow training data from large-scale real-world images, outperforming the most advanced unsupervised methods and supervised methods on synthetic datasets. Moreover, our models serve as a foundation model and enhance the performance of various downstream video tasks.
dots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.