 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgedots.llm1 Technical Report
Jun 06, 2025Mixture of Experts (MoE) models have emerged as a promising paradigm for scaling language models efficiently by activating only a subset of parameters for each input token. In this report, we present dots.llm1, a large-scale MoE model that activates 14B parameters out of a total of 142B parameters, delivering performance on par with state-of-the-art models while reducing training and inference costs. Leveraging our meticulously crafted and efficient data processing pipeline, dots.llm1 achieves performance comparable to Qwen2.5-72B after pretraining on 11.2T high-quality tokens and post-training to fully unlock its capabilities. Notably, no synthetic data is used during pretraining. To foster further research, we open-source intermediate training checkpoints at every one trillion tokens, providing valuable insights into the learning dynamics of large language models.
The Devil Is in the Details: Tackling Unimodal Spurious Correlations for Generalizable Multimodal Reward Models
Mar 05, 2025Multimodal Reward Models (MM-RMs) are crucial for aligning Large Language Models (LLMs) with human preferences, particularly as LLMs increasingly interact with multimodal data. However, we find that MM-RMs trained on existing datasets often struggle to generalize to out-of-distribution data due to their reliance on unimodal spurious correlations, primarily text-only shortcuts within the training distribution, which prevents them from leveraging true multimodal reward functions. To address this, we introduce a Shortcut-aware MM-RM learning algorithm that mitigates this issue by dynamically reweighting training samples, shifting the distribution toward better multimodal understanding, and reducing dependence on unimodal spurious correlations. Our experiments demonstrate significant improvements in generalization, downstream task performance, and scalability, establishing a more robust framework for multimodal reward modeling.
Cheems: A Practical Guidance for Building and Evaluating Chinese Reward Models from Scratch
Feb 24, 2025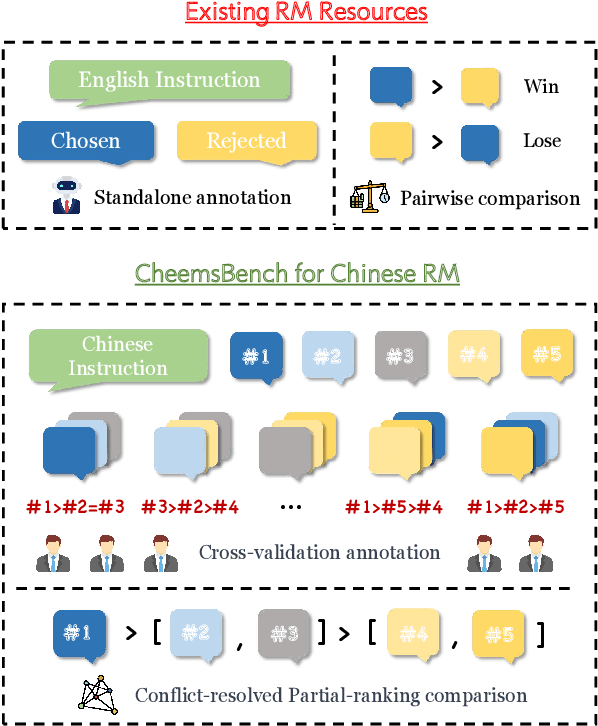
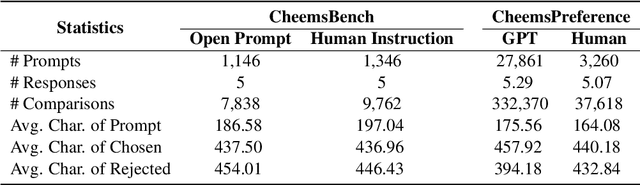
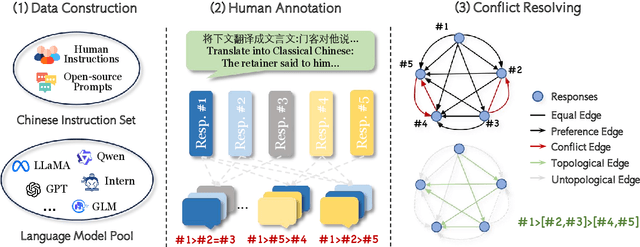
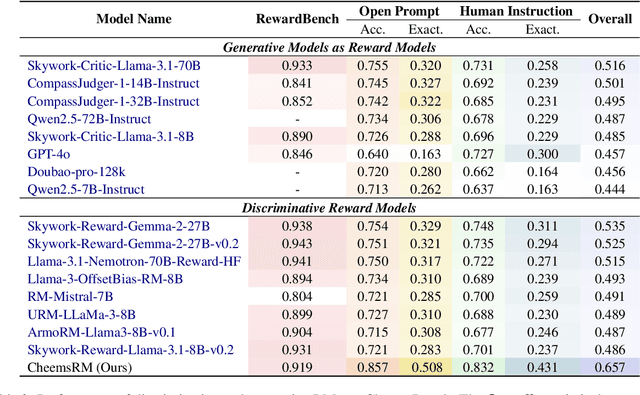
Reward models (RMs) are crucial for aligning large language models (LLMs) with human preferences. However, most RM research is centered on English and relies heavily on synthetic resources, which leads to limited and less reliable datasets and benchmarks for Chinese. To address this gap, we introduce CheemsBench, a fully human-annotated RM evaluation benchmark within Chinese contexts, and CheemsPreference, a large-scale and diverse preference dataset annotated through human-machine collaboration to support Chinese RM training. We systematically evaluate open-source discriminative and generative RMs on CheemsBench and observe significant limitations in their ability to capture human preferences in Chinese scenarios. Additionally, based on CheemsPreference, we construct an RM that achieves state-of-the-art performance on CheemsBench, demonstrating the necessity of human supervision in RM training. Our findings reveal that scaled AI-generated data struggles to fully capture human preferences, emphasizing the importance of high-quality human supervision in RM development.
Critic-CoT: Boosting the reasoning abilities of large language model via Chain-of-thoughts Critic
Aug 29, 2024



Self-critic has become an important mechanism for enhancing the reasoning performance of LLMs. However, current approaches mainly involve basic prompts without further training, which tend to be over-simplified, leading to limited accuracy.Moreover, there is a lack of in-depth investigation of the relationship between LLM's ability to criticism and its task-solving performance.To address these issues, we propose Critic-CoT, a novel framework that pushes LLMs toward System-2-like critic capability, via step-wise CoT reasoning format and distant-supervision data construction, without the need for human annotation. Experiments on GSM8K and MATH show that via filtering out invalid solutions or iterative refinement, our enhanced model boosts task-solving performance, which demonstrates the effectiveness of our method. Further, we find that training on critique and refinement alone improves the generation. We hope our work could shed light on future research on improving the reasoning and critic ability of LLMs.