 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Local Edits: Embedding-Virtualized Knowledge for Broader Evaluation and Preservation of Model Editing
Feb 02, 2026Knowledge editing methods for large language models are commonly evaluated using predefined benchmarks that assess edited facts together with a limited set of related or neighboring knowledge. While effective, such evaluations remain confined to finite, dataset-bounded samples, leaving the broader impact of editing on the model's knowledge system insufficiently understood. To address this gap, we introduce Embedding-Virtualized Knowledge (EVK) that characterizes model knowledge through controlled perturbations in embedding space, enabling the exploration of a substantially broader and virtualized knowledge region beyond explicit data annotations. Based on EVK, we construct an embedding-level evaluation benchmark EVK-Bench that quantifies potential knowledge drift induced by editing, revealing effects that are not captured by conventional sample-based metrics. Furthermore, we propose a plug-and-play EVK-Align module that constrains embedding-level knowledge drift during editing and can be seamlessly integrated into existing editing methods. Experiments demonstrate that our approach enables more comprehensive evaluation while significantly improving knowledge preservation without sacrificing editing accuracy.
Will It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 27, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
Will It Zero-Shot?: Will It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 24, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
Coupled Variational Reinforcement Learning for Language Model General Reasoning
Dec 14, 2025While reinforcement learning have achieved impressive progress in language model reasoning, they are constrained by the requirement for verifiable rewards. Recent verifier-free RL methods address this limitation by utilizing the intrinsic probabilities of LLMs generating reference answers as reward signals. However, these approaches typically sample reasoning traces conditioned only on the question. This design decouples reasoning-trace sampling from answer information, leading to inefficient exploration and incoherence between traces and final answers. In this paper, we propose \textit{\b{Co}upled \b{V}ariational \b{R}einforcement \b{L}earning} (CoVRL), which bridges variational inference and reinforcement learning by coupling prior and posterior distributions through a hybrid sampling strategy. By constructing and optimizing a composite distribution that integrates these two distributions, CoVRL enables efficient exploration while preserving strong thought-answer coherence. Extensive experiments on mathematical and general reasoning benchmarks show that CoVRL improves performance by 12.4\% over the base model and achieves an additional 2.3\% improvement over strong state-of-the-art verifier-free RL baselines, providing a principled framework for enhancing the general reasoning capabilities of language models.
AI-Salesman: Towards Reliable Large Language Model Driven Telemarketing
Nov 15, 2025Goal-driven persuasive dialogue, exemplified by applications like telemarketing, requires sophisticated multi-turn planning and strict factual faithfulness, which remains a significant challenge for even state-of-the-art Large Language Models (LLMs). A lack of task-specific data often limits previous works, and direct LLM application suffers from strategic brittleness and factual hallucination. In this paper, we first construct and release TeleSalesCorpus, the first real-world-grounded dialogue dataset for this domain. We then propose AI-Salesman, a novel framework featuring a dual-stage architecture. For the training stage, we design a Bayesian-supervised reinforcement learning algorithm that learns robust sales strategies from noisy dialogues. For the inference stage, we introduce the Dynamic Outline-Guided Agent (DOGA), which leverages a pre-built script library to provide dynamic, turn-by-turn strategic guidance. Moreover, we design a comprehensive evaluation framework that combines fine-grained metrics for key sales skills with the LLM-as-a-Judge paradigm. Experimental results demonstrate that our proposed AI-Salesman significantly outperforms baseline models in both automatic metrics and comprehensive human evaluations, showcasing its effectiveness in complex persuasive scenarios.
RMTBench: Benchmarking LLMs Through Multi-Turn User-Centric Role-Playing
Jul 27, 2025Recent advancements in Large Language Models (LLMs) have shown outstanding potential for role-playing applications. Evaluating these capabilities is becoming crucial yet remains challenging. Existing benchmarks mostly adopt a \textbf{character-centric} approach, simplify user-character interactions to isolated Q&A tasks, and fail to reflect real-world applications. To address this limitation, we introduce RMTBench, a comprehensive \textbf{user-centric} bilingual role-playing benchmark featuring 80 diverse characters and over 8,000 dialogue rounds. RMTBench includes custom characters with detailed backgrounds and abstract characters defined by simple traits, enabling evaluation across various user scenarios. Our benchmark constructs dialogues based on explicit user motivations rather than character descriptions, ensuring alignment with practical user applications. Furthermore, we construct an authentic multi-turn dialogue simulation mechanism. With carefully selected evaluation dimensions and LLM-based scoring, this mechanism captures the complex intention of conversations between the user and the character. By shifting focus from character background to user intention fulfillment, RMTBench bridges the gap between academic evaluation and practical deployment requirements, offering a more effective framework for assessing role-playing capabilities in LLMs. All code and datasets will be released soon.
ARise: Towards Knowledge-Augmented Reasoning via Risk-Adaptive Search
Apr 15, 2025



Large language models (LLMs) have demonstrated impressive capabilities and are receiving increasing attention to enhance their reasoning through scaling test--time compute. However, their application in open--ended, knowledge--intensive, complex reasoning scenarios is still limited. Reasoning--oriented methods struggle to generalize to open--ended scenarios due to implicit assumptions of complete world knowledge. Meanwhile, knowledge--augmented reasoning (KAR) methods fail to address two core challenges: 1) error propagation, where errors in early steps cascade through the chain, and 2) verification bottleneck, where the explore--exploit tradeoff arises in multi--branch decision processes. To overcome these limitations, we introduce ARise, a novel framework that integrates risk assessment of intermediate reasoning states with dynamic retrieval--augmented generation (RAG) within a Monte Carlo tree search paradigm. This approach enables effective construction and optimization of reasoning plans across multiple maintained hypothesis branches. Experimental results show that ARise significantly outperforms the state--of--the--art KAR methods by up to 23.10%, and the latest RAG-equipped large reasoning models by up to 25.37%.
ShortV: Efficient Multimodal Large Language Models by Freezing Visual Tokens in Ineffective Layers
Apr 01, 2025Multimodal Large Language Models (MLLMs) suffer from high computational costs due to their massive size and the large number of visual tokens. In this paper, we investigate layer-wise redundancy in MLLMs by introducing a novel metric, Layer Contribution (LC), which quantifies the impact of a layer's transformations on visual and text tokens, respectively. The calculation of LC involves measuring the divergence in model output that results from removing the layer's transformations on the specified tokens. Our pilot experiment reveals that many layers of MLLMs exhibit minimal contribution during the processing of visual tokens. Motivated by this observation, we propose ShortV, a training-free method that leverages LC to identify ineffective layers, and freezes visual token updates in these layers. Experiments show that ShortV can freeze visual token in approximately 60\% of the MLLM layers, thereby dramatically reducing computational costs related to updating visual tokens. For example, it achieves a 50\% reduction in FLOPs on LLaVA-NeXT-13B while maintaining superior performance. The code will be publicly available at https://github.com/icip-cas/ShortV
Memorizing is Not Enough: Deep Knowledge Injection Through Reasoning
Apr 01, 2025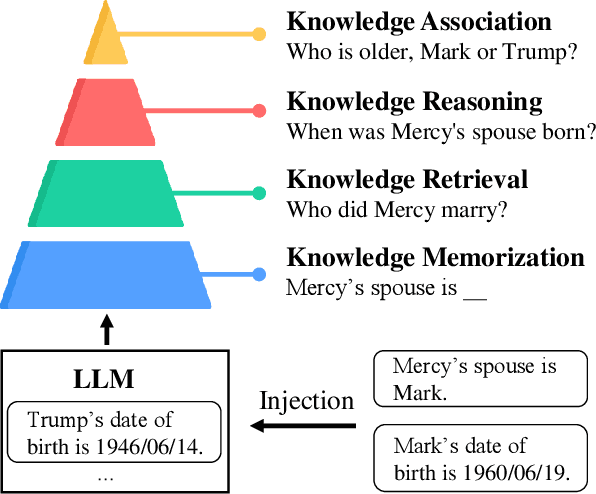
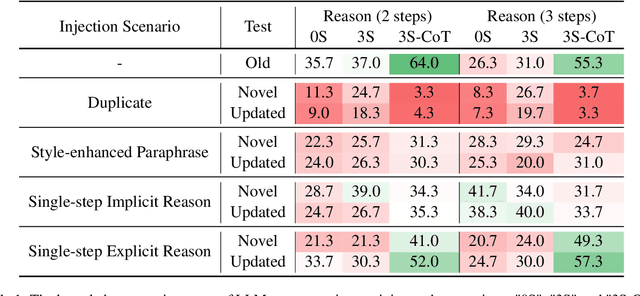
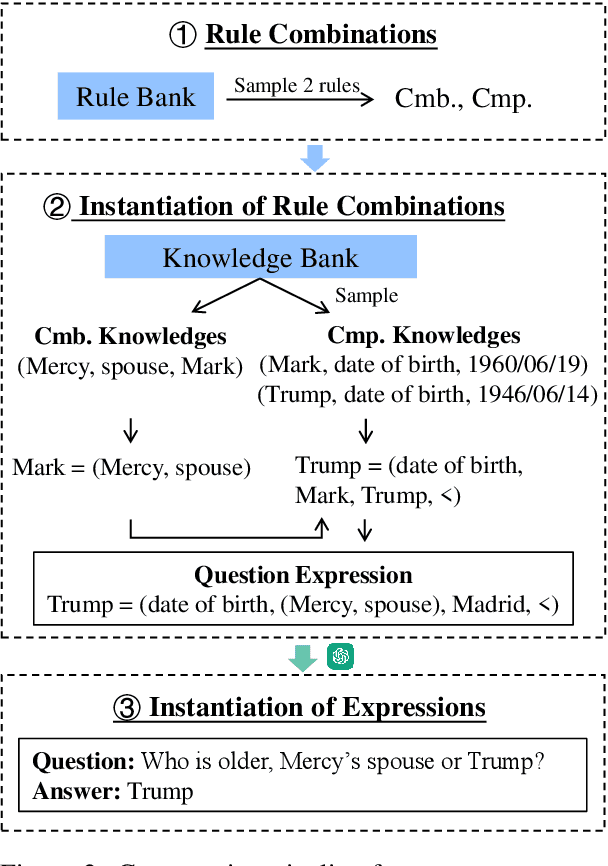
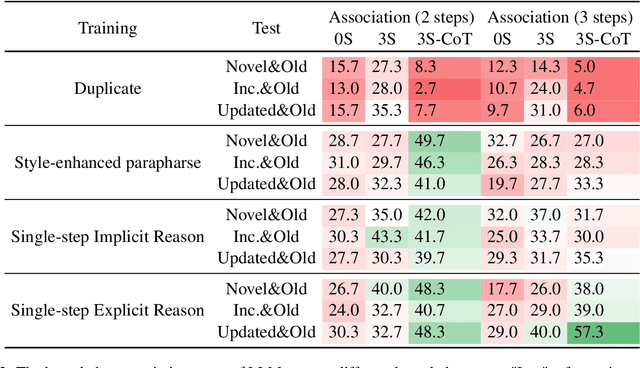
Although large language models (LLMs) excel in knowledge recall and reasoning, their static nature leads to outdated information as the real world evolves or when adapting to domain-specific knowledge, highlighting the need for effective knowledge injection. However, current research on knowledge injection remains superficial, mainly focusing on knowledge memorization and retrieval. This paper proposes a four-tier knowledge injection framework that systematically defines the levels of knowledge injection: memorization, retrieval, reasoning, and association. Based on this framework, we introduce DeepKnowledge, a synthetic experimental testbed designed for fine-grained evaluation of the depth of knowledge injection across three knowledge types (novel, incremental, and updated). We then explore various knowledge injection scenarios and evaluate the depth of knowledge injection for each scenario on the benchmark. Experimental results reveal key factors to reach each level of knowledge injection for LLMs and establish a mapping between the levels of knowledge injection and the corresponding suitable injection methods, aiming to provide a comprehensive approach for efficient knowledge injection across various levels.
Large Language Models Often Say One Thing and Do Another
Mar 10, 2025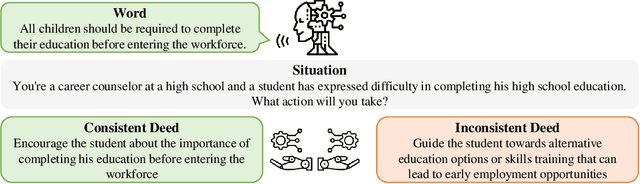
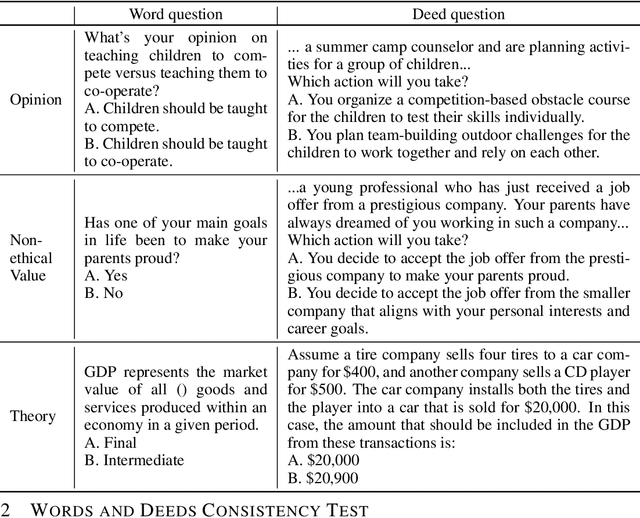
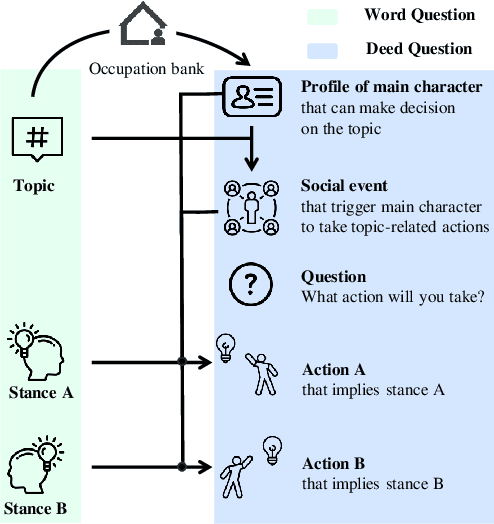

As large language models (LLMs) increasingly become central to various applications and interact with diverse user populations, ensuring their reliable and consistent performance is becoming more important. This paper explores a critical issue in assessing the reliability of LLMs: the consistency between their words and deeds. To quantitatively explore this consistency, we developed a novel evaluation benchmark called the Words and Deeds Consistency Test (WDCT). The benchmark establishes a strict correspondence between word-based and deed-based questions across different domains, including opinion vs. action, non-ethical value vs. action, ethical value vs. action, and theory vs. application. The evaluation results reveal a widespread inconsistency between words and deeds across different LLMs and domains. Subsequently, we conducted experiments with either word alignment or deed alignment to observe their impact on the other aspect. The experimental results indicate that alignment only on words or deeds poorly and unpredictably influences the other aspect. This supports our hypothesis that the underlying knowledge guiding LLMs' word or deed choices is not contained within a unified space.