 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo-o3: Native Interleaved Clue Seeking for Long Video Multi-Hop Reasoning
Jan 30, 2026Existing multimodal large language models for long-video understanding predominantly rely on uniform sampling and single-turn inference, limiting their ability to identify sparse yet critical evidence amid extensive redundancy. We introduce Video-o3, a novel framework that supports iterative discovery of salient visual clues, fine-grained inspection of key segments, and adaptive termination once sufficient evidence is acquired. Technically, we address two core challenges in interleaved tool invocation. First, to mitigate attention dispersion induced by the heterogeneity of reasoning and tool-calling, we propose Task-Decoupled Attention Masking, which isolates per-step concentration while preserving shared global context. Second, to control context length growth in multi-turn interactions, we introduce a Verifiable Trajectory-Guided Reward that balances exploration coverage with reasoning efficiency. To support training at scale, we further develop a data synthesis pipeline and construct Seeker-173K, comprising 173K high-quality tool-interaction trajectories for effective supervised and reinforcement learning. Extensive experiments show that Video-o3 substantially outperforms state-of-the-art methods, achieving 72.1% accuracy on MLVU and 46.5% on Video-Holmes. These results demonstrate Video-o3's strong multi-hop evidence-seeking and reasoning capabilities, and validate the effectiveness of native tool invocation in long-video scenarios.
AI-Salesman: Towards Reliable Large Language Model Driven Telemarketing
Nov 15, 2025Goal-driven persuasive dialogue, exemplified by applications like telemarketing, requires sophisticated multi-turn planning and strict factual faithfulness, which remains a significant challenge for even state-of-the-art Large Language Models (LLMs). A lack of task-specific data often limits previous works, and direct LLM application suffers from strategic brittleness and factual hallucination. In this paper, we first construct and release TeleSalesCorpus, the first real-world-grounded dialogue dataset for this domain. We then propose AI-Salesman, a novel framework featuring a dual-stage architecture. For the training stage, we design a Bayesian-supervised reinforcement learning algorithm that learns robust sales strategies from noisy dialogues. For the inference stage, we introduce the Dynamic Outline-Guided Agent (DOGA), which leverages a pre-built script library to provide dynamic, turn-by-turn strategic guidance. Moreover, we design a comprehensive evaluation framework that combines fine-grained metrics for key sales skills with the LLM-as-a-Judge paradigm. Experimental results demonstrate that our proposed AI-Salesman significantly outperforms baseline models in both automatic metrics and comprehensive human evaluations, showcasing its effectiveness in complex persuasive scenarios.
exUMI: Extensible Robot Teaching System with Action-aware Task-agnostic Tactile Representation
Sep 18, 2025Tactile-aware robot learning faces critical challenges in data collection and representation due to data scarcity and sparsity, and the absence of force feedback in existing systems. To address these limitations, we introduce a tactile robot learning system with both hardware and algorithm innovations. We present exUMI, an extensible data collection device that enhances the vanilla UMI with robust proprioception (via AR MoCap and rotary encoder), modular visuo-tactile sensing, and automated calibration, achieving 100% data usability. Building on an efficient collection of over 1 M tactile frames, we propose Tactile Prediction Pretraining (TPP), a representation learning framework through action-aware temporal tactile prediction, capturing contact dynamics and mitigating tactile sparsity. Real-world experiments show that TPP outperforms traditional tactile imitation learning. Our work bridges the gap between human tactile intuition and robot learning through co-designed hardware and algorithms, offering open-source resources to advance contact-rich manipulation research. Project page: https://silicx.github.io/exUMI.
ShortV: Efficient Multimodal Large Language Models by Freezing Visual Tokens in Ineffective Layers
Apr 01, 2025Multimodal Large Language Models (MLLMs) suffer from high computational costs due to their massive size and the large number of visual tokens. In this paper, we investigate layer-wise redundancy in MLLMs by introducing a novel metric, Layer Contribution (LC), which quantifies the impact of a layer's transformations on visual and text tokens, respectively. The calculation of LC involves measuring the divergence in model output that results from removing the layer's transformations on the specified tokens. Our pilot experiment reveals that many layers of MLLMs exhibit minimal contribution during the processing of visual tokens. Motivated by this observation, we propose ShortV, a training-free method that leverages LC to identify ineffective layers, and freezes visual token updates in these layers. Experiments show that ShortV can freeze visual token in approximately 60\% of the MLLM layers, thereby dramatically reducing computational costs related to updating visual tokens. For example, it achieves a 50\% reduction in FLOPs on LLaVA-NeXT-13B while maintaining superior performance. The code will be publicly available at https://github.com/icip-cas/ShortV
AI2Agent: An End-to-End Framework for Deploying AI Projects as Autonomous Agents
Mar 31, 2025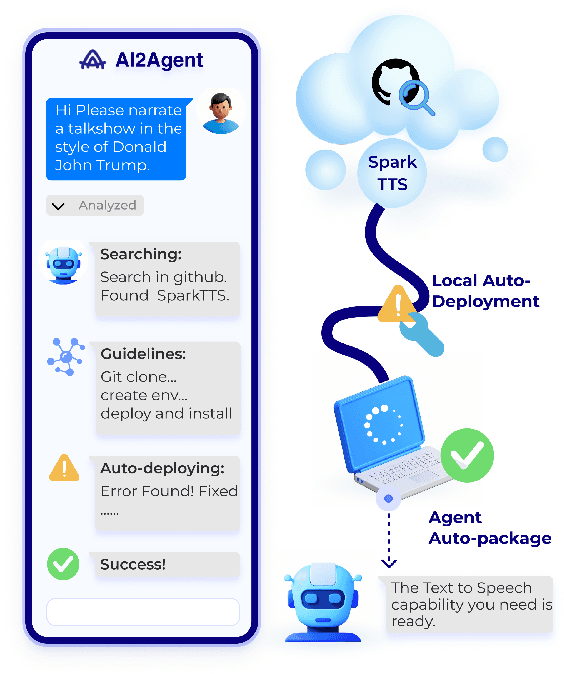
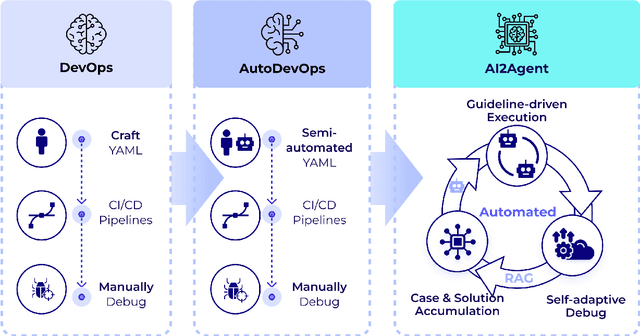
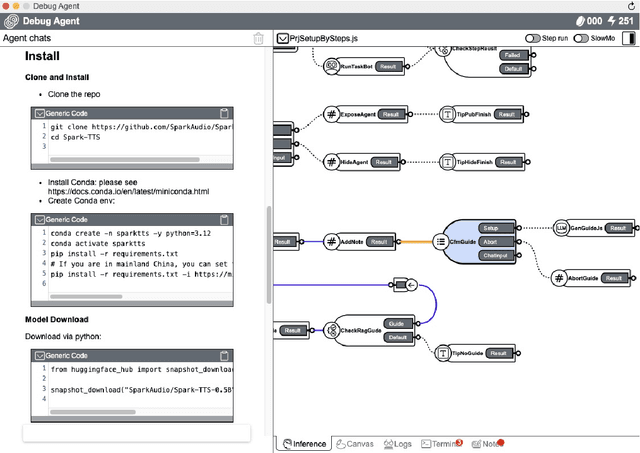
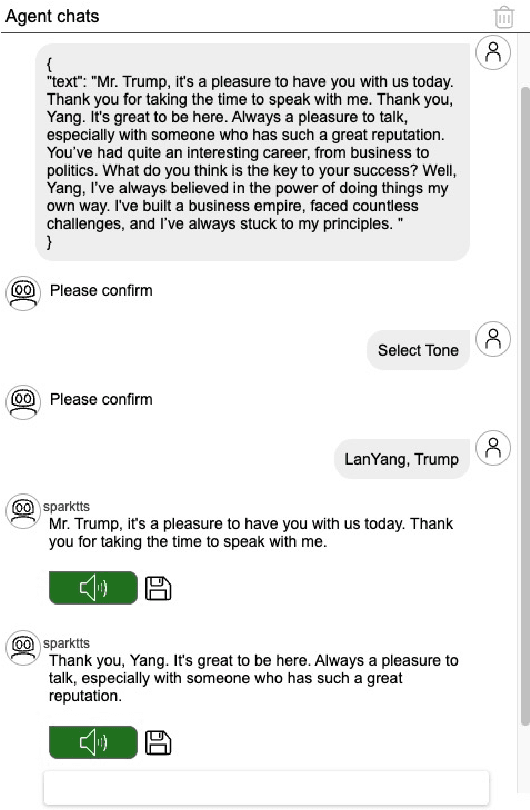
As AI technology advances, it is driving innovation across industries, increasing the demand for scalable AI project deployment. However, deployment remains a critical challenge due to complex environment configurations, dependency conflicts, cross-platform adaptation, and debugging difficulties, which hinder automation and adoption. This paper introduces AI2Agent, an end-to-end framework that automates AI project deployment through guideline-driven execution, self-adaptive debugging, and case \& solution accumulation. AI2Agent dynamically analyzes deployment challenges, learns from past cases, and iteratively refines its approach, significantly reducing human intervention. To evaluate its effectiveness, we conducted experiments on 30 AI deployment cases, covering TTS, text-to-image generation, image editing, and other AI applications. Results show that AI2Agent significantly reduces deployment time and improves success rates. The code and demo video are now publicly accessible.
CONGRA: Benchmarking Automatic Conflict Resolution
Sep 21, 2024
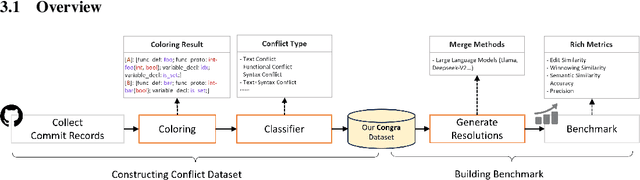


Resolving conflicts from merging different software versions is a challenging task. To reduce the overhead of manual merging, researchers develop various program analysis-based tools which only solve specific types of conflicts and have a limited scope of application. With the development of language models, researchers treat conflict code as text, which theoretically allows for addressing almost all types of conflicts. However, the absence of effective conflict difficulty grading methods hinders a comprehensive evaluation of large language models (LLMs), making it difficult to gain a deeper understanding of their limitations. Furthermore, there is a notable lack of large-scale open benchmarks for evaluating the performance of LLMs in automatic conflict resolution. To address these issues, we introduce ConGra, a CONflict-GRAded benchmarking scheme designed to evaluate the performance of software merging tools under varying complexity conflict scenarios. We propose a novel approach to classify conflicts based on code operations and use it to build a large-scale evaluation dataset based on 44,948 conflicts from 34 real-world projects. We evaluate state-of-the-art LLMs on conflict resolution tasks using this dataset. By employing the dataset, we assess the performance of multiple state-of-the-art LLMs and code LLMs, ultimately uncovering two counterintuitive yet insightful phenomena. ConGra will be released at https://github.com/HKU-System-Security-Lab/ConGra.
Base of RoPE Bounds Context Length
May 23, 2024



Position embedding is a core component of current Large Language Models (LLMs). Rotary position embedding (RoPE), a technique that encodes the position information with a rotation matrix, has been the de facto choice for position embedding in many LLMs, such as the Llama series. RoPE has been further utilized to extend long context capability, which is roughly based on adjusting the \textit{base} parameter of RoPE to mitigate out-of-distribution (OOD) problems in position embedding. However, in this paper, we find that LLMs may obtain a superficial long-context ability based on the OOD theory. We revisit the role of RoPE in LLMs and propose a novel property of long-term decay, we derive that the \textit{base of RoPE bounds context length}: there is an absolute lower bound for the base value to obtain certain context length capability. Our work reveals the relationship between context length and RoPE base both theoretically and empirically, which may shed light on future long context training.
ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
Mar 07, 2024



As Large Language Models (LLMs) continue to advance in performance, their size has escalated significantly, with current LLMs containing billions or even trillions of parameters. However, in this study, we discovered that many layers of LLMs exhibit high similarity, and some layers play a negligible role in network functionality. Based on this observation, we define a metric called Block Influence (BI) to gauge the significance of each layer in LLMs. We then propose a straightforward pruning approach: layer removal, in which we directly delete the redundant layers in LLMs based on their BI scores. Experiments demonstrate that our method, which we call ShortGPT, significantly outperforms previous state-of-the-art (SOTA) methods in model pruning. Moreover, ShortGPT is orthogonal to quantization-like methods, enabling further reduction in parameters and computation. The ability to achieve better results through simple layer removal, as opposed to more complex pruning techniques, suggests a high degree of redundancy in the model architecture.
MDIA: A Benchmark for Multilingual Dialogue Generation in 46 Languages
Aug 27, 2022

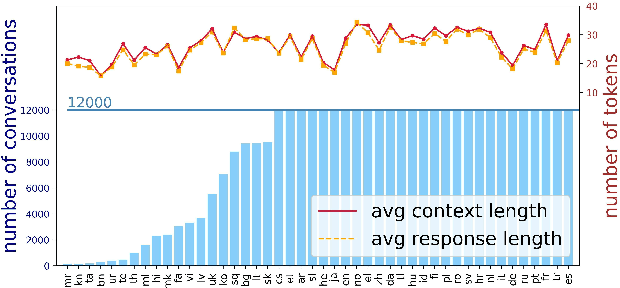
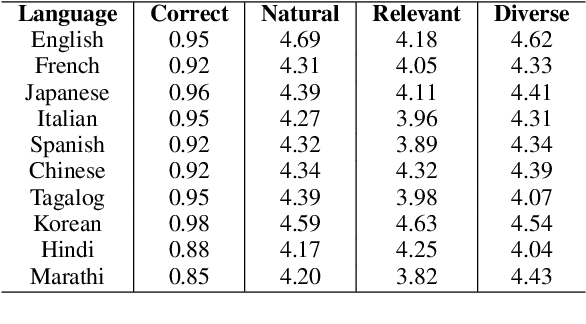
Owing to the lack of corpora for low-resource languages, current works on dialogue generation have mainly focused on English. In this paper, we present mDIA, the first large-scale multilingual benchmark for dialogue generation across low- to high-resource languages. It covers real-life conversations in 46 languages across 19 language families. We present baseline results obtained by fine-tuning the multilingual, non-dialogue-focused pre-trained model mT5 as well as English-centric, dialogue-focused pre-trained chatbot DialoGPT. The results show that mT5-based models perform better on sacreBLEU and BertScore but worse on diversity. Even though promising results are found in few-shot and zero-shot scenarios, there is a large gap between the generation quality in English and other languages. We hope that the release of mDIA could encourage more works on multilingual dialogue generation to promote language diversity.