 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataLadder: A Simulation-Enabled Interconversion Toolchain for the Embodied Data Pyramid
Jun 15, 2026Generalist robot policies require trustworthy evaluation and robot-usable training data, but both are difficult to scale with physical robots alone. Real-robot trials and demonstrations remain the most faithful source of deployment signals, yet they are slow, costly, and hard to reproduce. We present DataLadder, a simulation-enabled interconversion toolchain for human-robot aligned model evaluation and data generation, denoted as Robot $\rightleftharpoons$ Simulation $\rightleftharpoons$ Human. On the one hand, the Robot $\rightarrow$ Simulation $\rightarrow$ Human pathway supports human-robot aligned model evaluation by reconstructing real-robot tabletop organization tasks as calibrated digital twins for scalable evaluation, while using human embodied feedback to inspect and refine the naturalness of simulated motions. On the other hand, the Human $\rightarrow$ Simulation $\rightarrow$ Robot pathway supports human-robot aligned data generation: it lifts ego-centric human demonstrations into simulation, checks them under robot physical constraints, and converts them into robot-centered trajectories, annotations, and visual observations. Together, these pathways use the JoySim simulator as both a scalable evaluation layer and a physical consistency filter for robot data generation. We further package the core reconstruction, simulation, rendering, and realism-augmentation modules as cloud services on JD Cloud, turning the system into reusable infrastructure for robot data generation and model evaluation.
Awakening the Hydra: Stabilizing Multi-Concept Backdoor Injection in Text-to-Image Diffusion Models
May 19, 2026Text-to-image diffusion models are increasingly developed through open-source reuse and repeated downstream fine-tuning, where reused checkpoints are difficult to verify and thus more susceptible to hidden backdoor behaviors. In such ecosystems, a single pretrained model may be sequentially adapted and redistributed by multiple independent parties, allowing multiple concept-specific trigger-target associations to accumulate in the same model. When these associations coexist, semantic conflicts can be amplified in the shared representation space, leading to cross-concept entanglement and degraded generation quality. Notably, instead of strengthening the attack, such accumulation can destabilize previously injected behaviors and reduce attack reliability. In this work, we systematically investigate backdoor attacks under this interference-prone setting and propose Hydra, a unified framework for robust and controlled multi-concept backdoor injection under cumulative and decentralized reuse. Our core insight is that stable backdoor injection under large-scale multi-concept settings requires explicitly constraining trigger semantics while coordinating cross-task interactions during optimization. Specifically, Hydra performs evolutionary trigger search in the text encoder space to identify triggers that are semantically aligned with their target concepts while remaining stable across other injected concepts. It further combines multi-task fine-tuning with trigger-clean regularization to improve training stability under dense multi-concept injection. Extensive experiments across multiple diffusion backbones under rigorous multi-concept settings show that Hydra maintains effective backdoor activation while preserving clean generation fidelity and image quality. For instance, across 8 attackers and 500 concept pairs, Hydra maintains ~95% ASR and strong clean generation.
BadRSSD: Backdoor Attacks on Regularized Self-Supervised Diffusion Models
Mar 01, 2026Self-supervised diffusion models learn high-quality visual representations via latent space denoising. However, their representation layer poses a distinct threat: unlike traditional attacks targeting generative outputs, its unconstrained latent semantic space allows for stealthy backdoors, permitting malicious control upon triggering. In this paper, we propose BadRSSD, the first backdoor attack targeting the representation layer of self-supervised diffusion models. Specifically, it hijacks the semantic representations of poisoned samples with triggers in Principal Component Analysis (PCA) space toward those of a target image, then controls the denoising trajectory during diffusion by applying coordinated constraints across latent, pixel, and feature distribution spaces to steer the model toward generating the specified target. Additionally, we integrate representation dispersion regularization into the constraint framework to maintain feature space uniformity, significantly enhancing attack stealth. This approach preserves normal model functionality (high utility) while achieving precise target generation upon trigger activation (high specificity). Experiments on multiple benchmark datasets demonstrate that BadRSSD substantially outperforms existing attacks in both FID and MSE metrics, reliably establishing backdoors across different architectures and configurations, and effectively resisting state-of-the-art backdoor defenses.
Meta-FC: Meta-Learning with Feature Consistency for Robust and Generalizable Watermarking
Feb 25, 2026Deep learning-based watermarking has made remarkable progress in recent years. To achieve robustness against various distortions, current methods commonly adopt a training strategy where a \underline{\textbf{s}}ingle \underline{\textbf{r}}andom \underline{\textbf{d}}istortion (SRD) is chosen as the noise layer in each training batch. However, the SRD strategy treats distortions independently within each batch, neglecting the inherent relationships among different types of distortions and causing optimization conflicts across batches. As a result, the robustness and generalizability of the watermarking model are limited. To address this issue, we propose a novel training strategy that enhances robustness and generalization via \underline{\textbf{meta}}-learning with \underline{\textbf{f}}eature \underline{\textbf{c}}onsistency (Meta-FC). Specifically, we randomly sample multiple distortions from the noise pool to construct a meta-training task, while holding out one distortion as a simulated ``unknown'' distortion for the meta-testing phase. Through meta-learning, the model is encouraged to identify and utilize neurons that exhibit stable activations across different types of distortions, mitigating the optimization conflicts caused by the random sampling of diverse distortions in each batch. To further promote the transformation of stable activations into distortion-invariant representations, we introduce a feature consistency loss that constrains the decoded features of the same image subjected to different distortions to remain consistent. Extensive experiments demonstrate that, compared to the SRD training strategy, Meta-FC improves the robustness and generalization of various watermarking models by an average of 1.59\%, 4.71\%, and 2.38\% under high-intensity, combined, and unknown distortions.
FireRed-Image-Edit-1.0 Techinical Report
Feb 12, 2026We present FireRed-Image-Edit, a diffusion transformer for instruction-based image editing that achieves state-of-the-art performance through systematic optimization of data curation, training methodology, and evaluation design. We construct a 1.6B-sample training corpus, comprising 900M text-to-image and 700M image editing pairs from diverse sources. After rigorous cleaning, stratification, auto-labeling, and two-stage filtering, we retain over 100M high-quality samples balanced between generation and editing, ensuring strong semantic coverage and instruction alignment. Our multi-stage training pipeline progressively builds editing capability via pre-training, supervised fine-tuning, and reinforcement learning. To improve data efficiency, we introduce a Multi-Condition Aware Bucket Sampler for variable-resolution batching and Stochastic Instruction Alignment with dynamic prompt re-indexing. To stabilize optimization and enhance controllability, we propose Asymmetric Gradient Optimization for DPO, DiffusionNFT with layout-aware OCR rewards for text editing, and a differentiable Consistency Loss for identity preservation. We further establish REDEdit-Bench, a comprehensive benchmark spanning 15 editing categories, including newly introduced beautification and low-level enhancement tasks. Extensive experiments on REDEdit-Bench and public benchmarks (ImgEdit and GEdit) demonstrate competitive or superior performance against both open-source and proprietary systems. We release code, models, and the benchmark suite to support future research.
Federated Unlearning in the Wild: Rethinking Fairness and Data Discrepancy
Oct 08, 2025Machine unlearning is critical for enforcing data deletion rights like the "right to be forgotten." As a decentralized paradigm, Federated Learning (FL) also requires unlearning, but realistic implementations face two major challenges. First, fairness in Federated Unlearning (FU) is often overlooked. Exact unlearning methods typically force all clients into costly retraining, even those uninvolved. Approximate approaches, using gradient ascent or distillation, make coarse interventions that can unfairly degrade performance for clients with only retained data. Second, most FU evaluations rely on synthetic data assumptions (IID/non-IID) that ignore real-world heterogeneity. These unrealistic benchmarks obscure the true impact of unlearning and limit the applicability of current methods. We first conduct a comprehensive benchmark of existing FU methods under realistic data heterogeneity and fairness conditions. We then propose a novel, fairness-aware FU approach, Federated Cross-Client-Constrains Unlearning (FedCCCU), to explicitly address both challenges. FedCCCU offers a practical and scalable solution for real-world FU. Experimental results show that existing methods perform poorly in realistic settings, while our approach consistently outperforms them.
A transformer-BiGRU-based framework with data augmentation and confident learning for network intrusion detection
Sep 05, 2025



In today's fast-paced digital communication, the surge in network traffic data and frequency demands robust and precise network intrusion solutions. Conventional machine learning methods struggle to grapple with complex patterns within the vast network intrusion datasets, which suffer from data scarcity and class imbalance. As a result, we have integrated machine learning and deep learning techniques within the network intrusion detection system to bridge this gap. This study has developed TrailGate, a novel framework that combines machine learning and deep learning techniques. By integrating Transformer and Bidirectional Gated Recurrent Unit (BiGRU) architectures with advanced feature selection strategies and supplemented by data augmentation techniques, TrailGate can identifies common attack types and excels at detecting and mitigating emerging threats. This algorithmic fusion excels at detecting common and well-understood attack types and has the unique ability to swiftly identify and neutralize emerging threats that stem from existing paradigms.
IPBA: Imperceptible Perturbation Backdoor Attack in Federated Self-Supervised Learning
Aug 11, 2025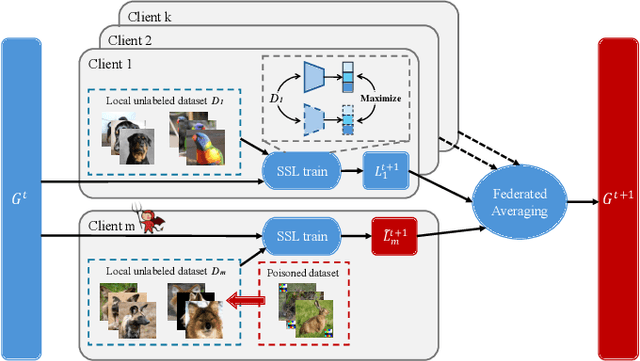
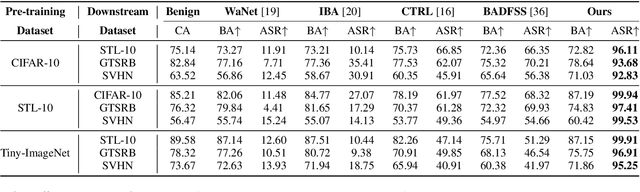

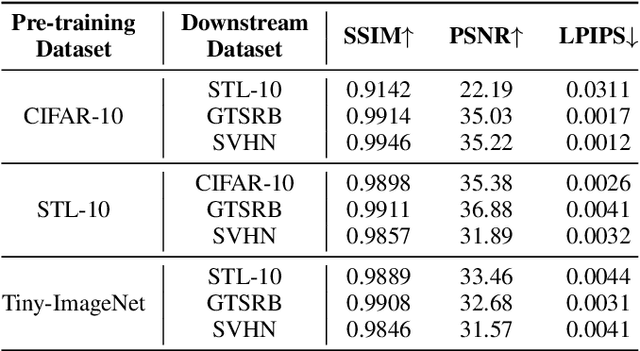
Federated self-supervised learning (FSSL) combines the advantages of decentralized modeling and unlabeled representation learning, serving as a cutting-edge paradigm with strong potential for scalability and privacy preservation. Although FSSL has garnered increasing attention, research indicates that it remains vulnerable to backdoor attacks. Existing methods generally rely on visually obvious triggers, which makes it difficult to meet the requirements for stealth and practicality in real-world deployment. In this paper, we propose an imperceptible and effective backdoor attack method against FSSL, called IPBA. Our empirical study reveals that existing imperceptible triggers face a series of challenges in FSSL, particularly limited transferability, feature entanglement with augmented samples, and out-of-distribution properties. These issues collectively undermine the effectiveness and stealthiness of traditional backdoor attacks in FSSL. To overcome these challenges, IPBA decouples the feature distributions of backdoor and augmented samples, and introduces Sliced-Wasserstein distance to mitigate the out-of-distribution properties of backdoor samples, thereby optimizing the trigger generation process. Our experimental results on several FSSL scenarios and datasets show that IPBA significantly outperforms existing backdoor attack methods in performance and exhibits strong robustness under various defense mechanisms.
Graph Federated Learning for Personalized Privacy Recommendation
Aug 08, 2025Federated recommendation systems (FedRecs) have gained significant attention for providing privacy-preserving recommendation services. However, existing FedRecs assume that all users have the same requirements for privacy protection, i.e., they do not upload any data to the server. The approaches overlook the potential to enhance the recommendation service by utilizing publicly available user data. In real-world applications, users can choose to be private or public. Private users' interaction data is not shared, while public users' interaction data can be shared. Inspired by the issue, this paper proposes a novel Graph Federated Learning for Personalized Privacy Recommendation (GFed-PP) that adapts to different privacy requirements while improving recommendation performance. GFed-PP incorporates the interaction data of public users to build a user-item interaction graph, which is then used to form a user relationship graph. A lightweight graph convolutional network (GCN) is employed to learn each user's user-specific personalized item embedding. To protect user privacy, each client learns the user embedding and the scoring function locally. Additionally, GFed-PP achieves optimization of the federated recommendation framework through the initialization of item embedding on clients and the aggregation of the user relationship graph on the server. Experimental results demonstrate that GFed-PP significantly outperforms existing methods for five datasets, offering superior recommendation accuracy without compromising privacy. This framework provides a practical solution for accommodating varying privacy preferences in federated recommendation systems.
Weather-Magician: Reconstruction and Rendering Framework for 4D Weather Synthesis In Real Time
May 26, 2025For tasks such as urban digital twins, VR/AR/game scene design, or creating synthetic films, the traditional industrial approach often involves manually modeling scenes and using various rendering engines to complete the rendering process. This approach typically requires high labor costs and hardware demands, and can result in poor quality when replicating complex real-world scenes. A more efficient approach is to use data from captured real-world scenes, then apply reconstruction and rendering algorithms to quickly recreate the authentic scene. However, current algorithms are unable to effectively reconstruct and render real-world weather effects. To address this, we propose a framework based on gaussian splatting, that can reconstruct real scenes and render them under synthesized 4D weather effects. Our work can simulate various common weather effects by applying Gaussians modeling and rendering techniques. It supports continuous dynamic weather changes and can easily control the details of the effects. Additionally, our work has low hardware requirements and achieves real-time rendering performance. The result demos can be accessed on our project homepage: weathermagician.github.io