 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized Emotion Detection from Floor Vibrations Induced by Footsteps
Mar 06, 2025Emotion recognition is critical for various applications such as early detection of mental health disorders and emotion based smart home systems. Previous studies used various sensing methods for emotion recognition, such as wearable sensors, cameras, and microphones. However, these methods have limitations in long term domestic, including intrusiveness and privacy concerns. To overcome these limitations, this paper introduces a nonintrusive and privacy friendly personalized emotion recognition system, EmotionVibe, which leverages footstep induced floor vibrations for emotion recognition. The main idea of EmotionVibe is that individuals' emotional states influence their gait patterns, subsequently affecting the floor vibrations induced by their footsteps. However, there are two main research challenges: 1) the complex and indirect relationship between human emotions and footstep induced floor vibrations and 2) the large between person variations within the relationship between emotions and gait patterns. To address these challenges, we first empirically characterize this complex relationship and develop an emotion sensitive feature set including gait related and vibration related features from footstep induced floor vibrations. Furthermore, we personalize the emotion recognition system for each user by calculating gait similarities between the target person (i.e., the person whose emotions we aim to recognize) and those in the training dataset and assigning greater weights to training people with similar gait patterns in the loss function. We evaluated our system in a real-world walking experiment with 20 participants, summing up to 37,001 footstep samples. EmotionVibe achieved the mean absolute error (MAE) of 1.11 and 1.07 for valence and arousal score estimations, respectively, reflecting 19.0% and 25.7% error reduction compared to the baseline method.
Road Boundary Detection Using 4D mmWave Radar for Autonomous Driving
Mar 03, 2025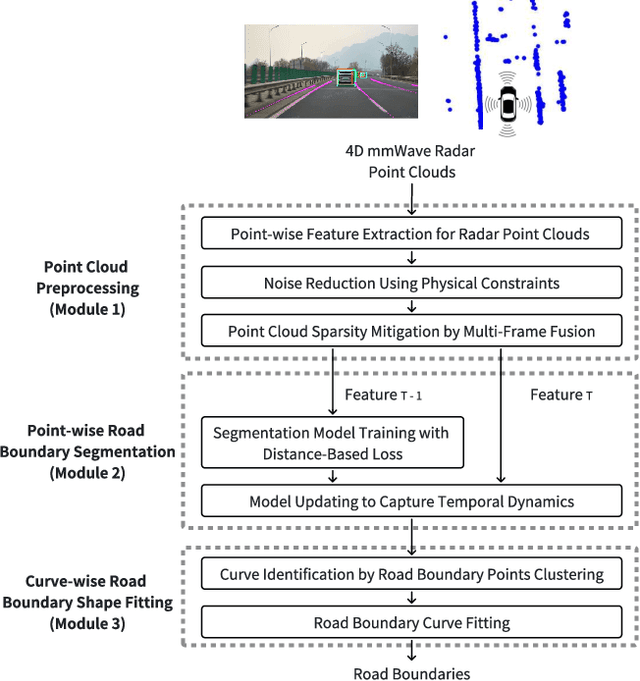
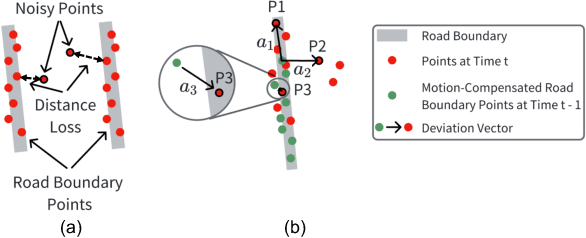
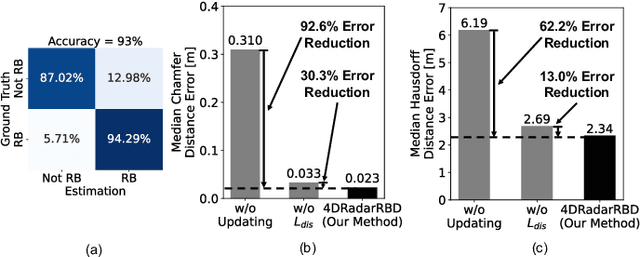
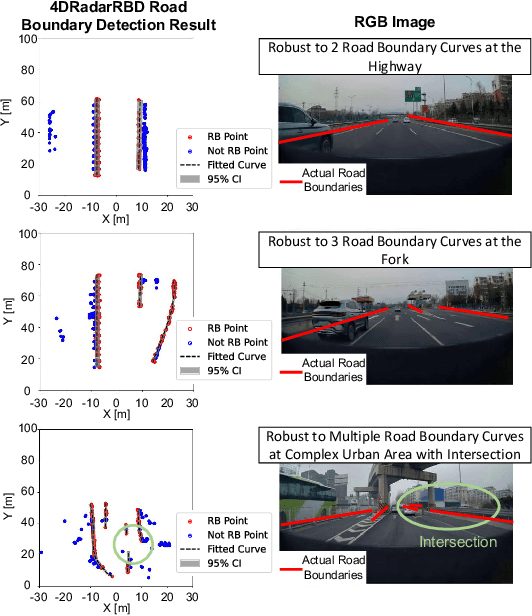
Detecting road boundaries, the static physical edges of the available driving area, is important for safe navigation and effective path planning in autonomous driving and advanced driver-assistance systems (ADAS). Traditionally, road boundary detection in autonomous driving relies on cameras and LiDAR. However, they are vulnerable to poor lighting conditions, such as nighttime and direct sunlight glare, or prohibitively expensive for low-end vehicles. To this end, this paper introduces 4DRadarRBD, the first road boundary detection method based on 4D mmWave radar which is cost-effective and robust in complex driving scenarios. The main idea is that road boundaries (e.g., fences, bushes, roadblocks), reflect millimeter waves, thus generating point cloud data for the radar. To overcome the challenge that the 4D mmWave radar point clouds contain many noisy points, we initially reduce noisy points via physical constraints for road boundaries and then segment the road boundary points from the noisy points by incorporating a distance-based loss which penalizes for falsely detecting the points far away from the actual road boundaries. In addition, we capture the temporal dynamics of point cloud sequences by utilizing each point's deviation from the vehicle motion-compensated road boundary detection result obtained from the previous frame, along with the spatial distribution of the point cloud for point-wise road boundary segmentation. We evaluated 4DRadarRBD through real-world driving tests and achieved a road boundary point segmentation accuracy of 93$\%$, with a median distance error of up to 0.023 m and an error reduction of 92.6$\%$ compared to the baseline model.
Continual Person Identification using Footstep-Induced Floor Vibrations on Heterogeneous Floor Structures
Feb 21, 2025



Person identification is important for smart buildings to provide personalized services such as health monitoring, activity tracking, and personnel management. However, previous person identification relies on pre-collected data from everyone, which is impractical in many buildings and public facilities in which visitors are typically expected. This calls for a continual person identification system that gradually learns people's identities on the fly. Existing studies use cameras to achieve this goal, but they require direct line-of-sight and also have raised privacy concerns in public. Other modalities such as wearables and pressure mats are limited by the requirement of device-carrying or dense deployment. Thus, prior studies introduced footstep-induced structural vibration sensing, which is non-intrusive and perceived as more privacy-friendly. However, this approach has a significant challenge: the high variability of vibration data due to structural heterogeneity and human gait variations, which makes online person identification algorithms perform poorly. In this paper, we characterize the variability in footstep-induced structural vibration data for accurate online person identification. To achieve this, we quantify and decompose different sources of variability and then design a feature transformation function to reduce the variability within each person's data to make different people's data more separable. We evaluate our approach through field experiments with 20 people. The results show a 70% variability reduction and a 90% accuracy for online person identification.
WeVibe: Weight Change Estimation Through Audio-Induced Shelf Vibrations In Autonomous Stores
Feb 17, 2025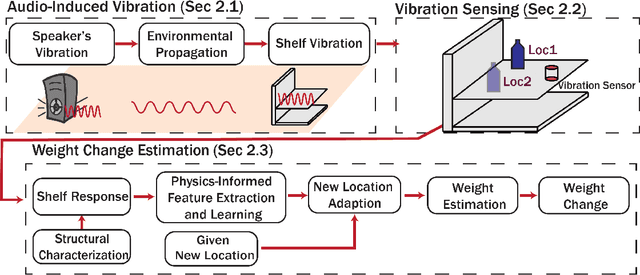
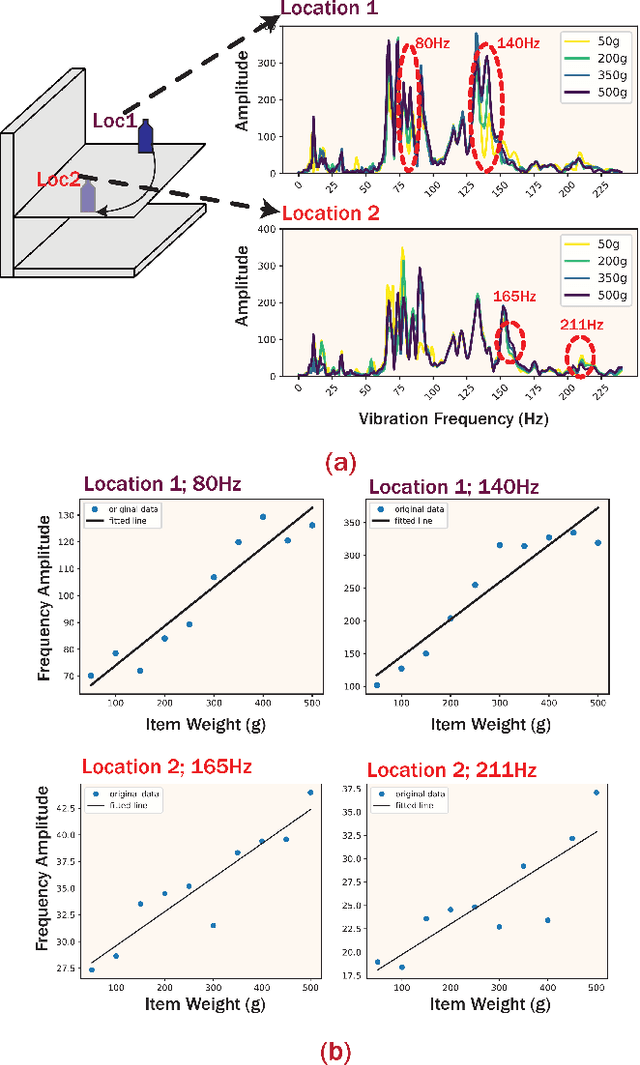

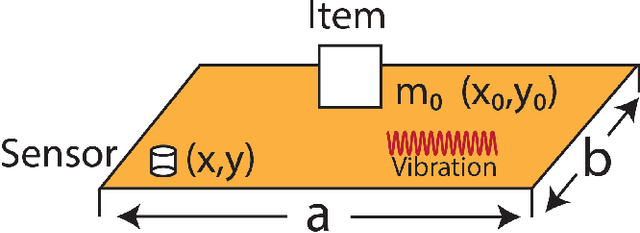
Weight change estimation is crucial in various applications, particularly for detecting pick-up and put-back actions when people interact with the shelf while shopping in autonomous stores. Moreover, accurate weight change estimation allows autonomous stores to automatically identify items being picked up or put back, ensuring precise cost estimation. However, the conventional approach of estimating weight changes requires specialized weight-sensing shelves, which are densely deployed weight scales, incurring intensive sensor consumption and high costs. Prior works explored the vibration-based weight sensing method, but they failed when the location of weight change varies. In response to these limitations, we made the following contributions: (1) We propose WeVibe, a first item weight change estimation system through active shelf vibration sensing. The main intuition of the system is that the weight placed on the shelf influences the dynamic vibration response of the shelf, thus altering the shelf vibration patterns. (2) We model a physics-informed relationship between the shelf vibration response and item weight across multiple locations on the shelf based on structural dynamics theory. This relationship is linear and allows easy training of a weight estimation model at a new location without heavy data collection. (3) We evaluate our system on a gondola shelf organized as the real-store settings. WeVibe achieved a mean absolute error down to 38.07g and a standard deviation of 31.2g with one sensor and 10% samples from three weight classes on estimating weight change from 0g to 450g, which can be leveraged for differentiating items with more than 100g differences.
Detecting Gait Abnormalities in Foot-Floor Contacts During Walking Through FootstepInduced Structural Vibrations
May 22, 2024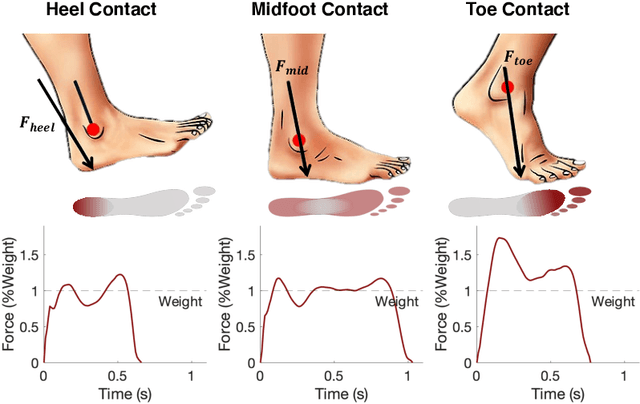
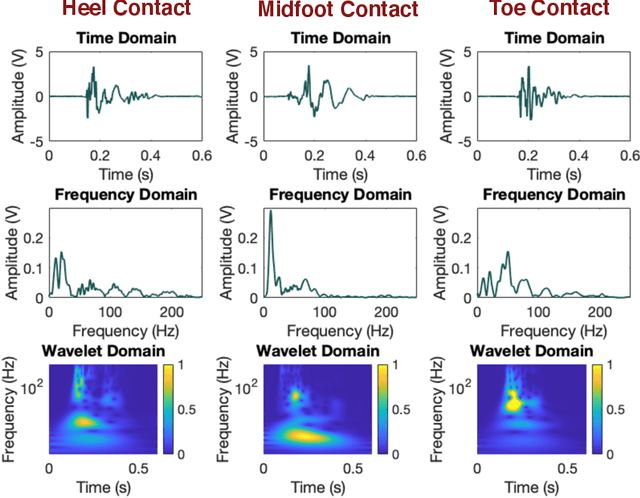
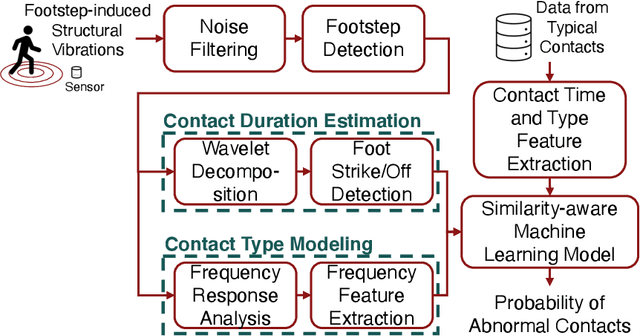
Gait abnormality detection is critical for the early discovery and progressive tracking of musculoskeletal and neurological disorders, such as Parkinson's and Cerebral Palsy. Especially, analyzing the foot-floor contacts during walking provides important insights into gait patterns, such as contact area, contact force, and contact time, enabling gait abnormality detection through these measurements. Existing studies use various sensing devices to capture such information, including cameras, wearables, and force plates. However, the former two lack force-related information, making it difficult to identify the causes of gait health issues, while the latter has limited coverage of the walking path. In this study, we leverage footstep-induced structural vibrations to infer foot-floor contact profiles and detect gait abnormalities. The main challenge lies in modeling the complex force transfer mechanism between the foot and the floor surfaces, leading to difficulty in reconstructing the force and contact profile during foot-floor interaction using structural vibrations. To overcome the challenge, we first characterize the floor vibration for each contact type (e.g., heel, midfoot, and toe contact) to understand how contact forces and areas affect the induced floor vibration. Then, we leverage the time-frequency response spectrum resulting from those contacts to develop features that are representative of each contact type. Finally, gait abnormalities are detected by comparing the predicted foot-floor contact force and motion with the healthy gait. To evaluate our approach, we conducted a real-world walking experiment with 8 subjects. Our approach achieves 91.6% and 96.7% accuracy in predicting contact type and time, respectively, leading to 91.9% accuracy in detecting various types of gait abnormalities, including asymmetry, dragging, and midfoot/toe contacts.
Normalizing flow-based deep variational Bayesian network for seismic multi-hazards and impacts estimation from InSAR imagery
Oct 20, 2023



Onsite disasters like earthquakes can trigger cascading hazards and impacts, such as landslides and infrastructure damage, leading to catastrophic losses; thus, rapid and accurate estimates are crucial for timely and effective post-disaster responses. Interferometric Synthetic aperture radar (InSAR) data is important in providing high-resolution onsite information for rapid hazard estimation. Most recent methods using InSAR imagery signals predict a single type of hazard and thus often suffer low accuracy due to noisy and complex signals induced by co-located hazards, impacts, and irrelevant environmental changes (e.g., vegetation changes, human activities). We introduce a novel stochastic variational inference with normalizing flows derived to jointly approximate posteriors of multiple unobserved hazards and impacts from noisy InSAR imagery.
Spatial Deep Deconvolution U-Net for Traffic Analyses with Distributed Acoustic Sensing
Dec 20, 2022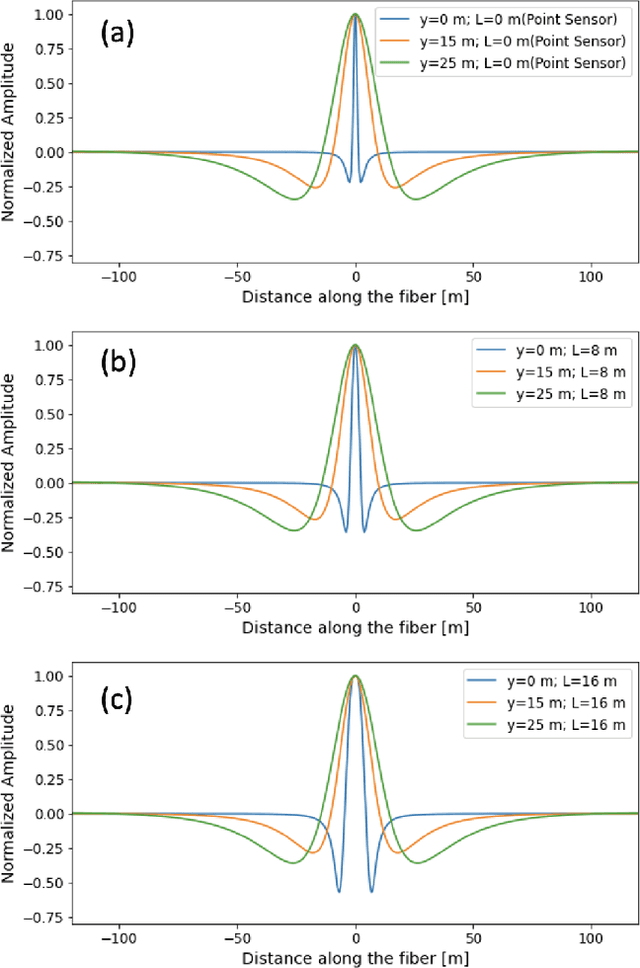
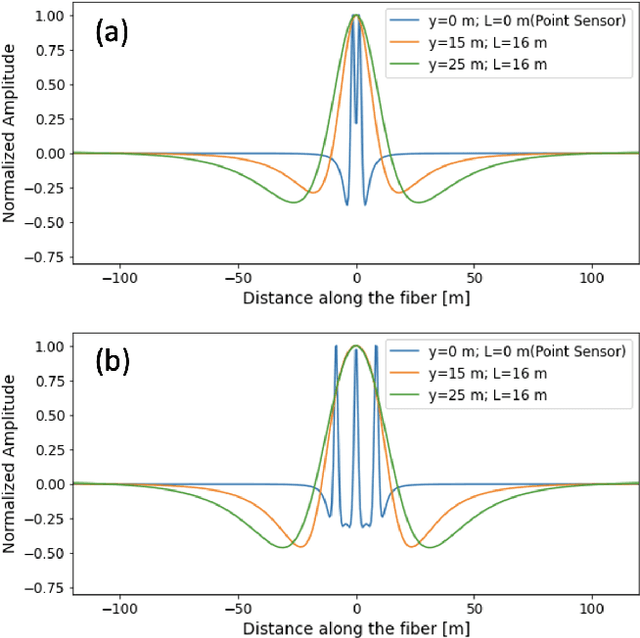
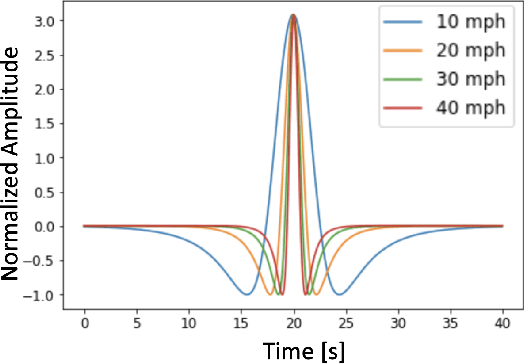
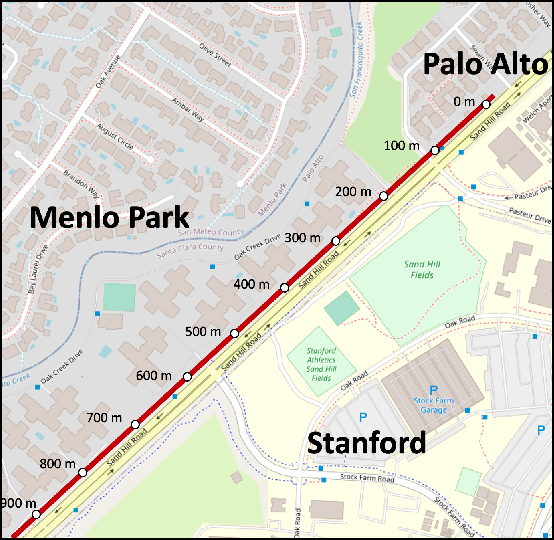
Distributed Acoustic Sensing (DAS) that transforms city-wide fiber-optic cables into a large-scale strain sensing array has shown the potential to revolutionize urban traffic monitoring by providing a fine-grained, scalable, and low-maintenance monitoring solution. However, there are challenges that limit DAS's real-world usage: noise contamination and interference among closely traveling cars. To address the issues, we introduce a self-supervised U-Net model that can suppress background noise and compress car-induced DAS signals into high-resolution pulses through spatial deconvolution. To guide the design of the approach, we investigate the fiber response to vehicles through numerical simulation and field experiments. We show that the localized and narrow outputs from our model lead to accurate and highly resolved car position and speed tracking. We evaluate the effectiveness and robustness of our method through field recordings under different traffic conditions and various driving speeds. Our results show that our method can enhance the spatial-temporal resolution and better resolve closely traveling cars. The spatial deconvolution U-Net model also enables the characterization of large-size vehicles to identify axle numbers and estimate the vehicle length. Monitoring large-size vehicles also benefits imaging deep earth by leveraging the surface waves induced by the dynamic vehicle-road interaction.
PigV$^2$: Monitoring Pig Vital Signs through Ground Vibrations Induced by Heartbeat and Respiration
Dec 07, 2022



Pig vital sign monitoring (e.g., estimating the heart rate (HR) and respiratory rate (RR)) is essential to understand the stress level of the sow and detect the onset of parturition. It helps to maximize peri-natal survival and improve animal well-being in swine production. The existing approach mainly relies on manual measurement, which is labor-intensive and only provides a few points of information. Other sensing modalities such as wearables and cameras are developed to enable more continuous measurement, but are still limited due to animal discomfort, data transfer, and storage challenges. In this paper, we introduce PigV$^2$, the first system to monitor pig heart rate and respiratory rate through ground vibrations. Our approach leverages the insight that both heartbeat and respiration generate ground vibrations when the sow is lying on the floor. We infer vital information by sensing and analyzing these vibrations. The main challenge in developing PigV$^2$ is the overlap of vital- and non-vital-related information in the vibration signals, including pig movements, pig postures, pig-to-sensor distances, and so on. To address this issue, we first characterize their effects, extract their current status, and then reduce their impact by adaptively interpolating vital rates over multiple sensors. PigV$^2$ is evaluated through a real-world deployment with 30 pigs. It has 3.4% and 8.3% average errors in monitoring the HR and RR of the sows, respectively.
GaitVibe+: Enhancing Structural Vibration-based Footstep Localization Using Temporary Cameras for In-home Gait Analysis
Dec 07, 2022



In-home gait analysis is important for providing early diagnosis and adaptive treatments for individuals with gait disorders. Existing systems include wearables and pressure mats, but they have limited scalability. Recent studies have developed vision-based systems to enable scalable, accurate in-home gait analysis, but it faces privacy concerns due to the exposure of people's appearances. Our prior work developed footstep-induced structural vibration sensing for gait monitoring, which is device-free, wide-ranged, and perceived as more privacy-friendly. Although it has succeeded in temporal gait event extraction, it shows limited performance for spatial gait parameter estimation due to imprecise footstep localization. In particular, the localization error mainly comes from the estimation error of the wave arrival time at the vibration sensors and its error propagation to wave velocity estimations. Therefore, we present GaitVibe+, a vibration-based footstep localization method fused with temporarily installed cameras for in-home gait analysis. Our method has two stages: fusion and operating. In the fusion stage, both cameras and vibration sensors are installed to record only a few trials of the subject's footstep data, through which we characterize the uncertainty in wave arrival time and model the wave velocity profiles for the given structure. In the operating stage, we remove the camera to preserve privacy at home. The footstep localization is conducted by estimating the time difference of arrival (TDoA) over multiple vibration sensors, whose accuracy is improved through the reduced uncertainty and velocity modeling during the fusion stage. We evaluate GaitVibe+ through a real-world experiment with 50 walking trials. With only 3 trials of multi-modal fusion, our approach has an average localization error of 0.22 meters, which reduces the spatial gait parameter error from 111% to 27%.
HierMUD: Hierarchical Multi-task Unsupervised Domain Adaptation between Bridges for Drive-by Damage Diagnosis
Jul 23, 2021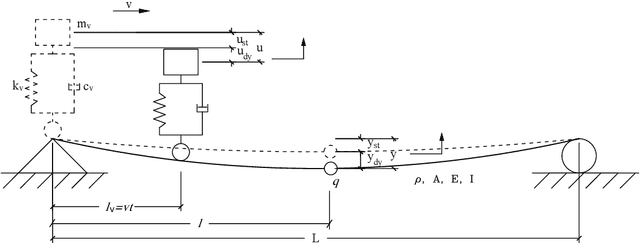
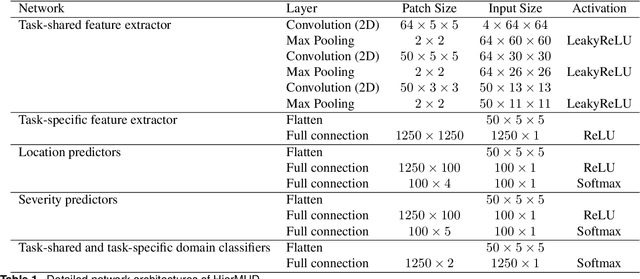
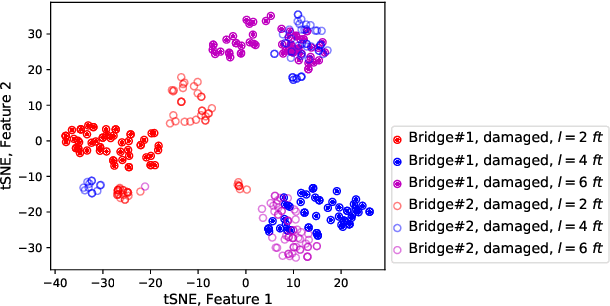
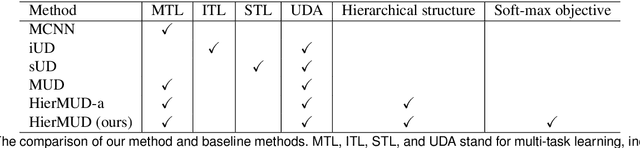
Monitoring bridge health using vibrations of drive-by vehicles has various benefits, such as no need for directly installing and maintaining sensors on the bridge. However, many of the existing drive-by monitoring approaches are based on supervised learning models that require labeled data from every bridge of interest, which is expensive and time-consuming, if not impossible, to obtain. To this end, we introduce a new framework that transfers the model learned from one bridge to diagnose damage in another bridge without any labels from the target bridge. Our framework trains a hierarchical neural network model in an adversarial way to extract task-shared and task-specific features that are informative to multiple diagnostic tasks and invariant across multiple bridges. We evaluate our framework on experimental data collected from 2 bridges and 3 vehicles. We achieve accuracies of 95% for damage detection, 93% for localization, and up to 72% for quantification, which are ~2 times improvements from baseline methods.