 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-resolution Score-Based Variational Graphical Diffusion for Causal Disaster System Modeling and Inference
Apr 05, 2025Complex systems with intricate causal dependencies challenge accurate prediction. Effective modeling requires precise physical process representation, integration of interdependent factors, and incorporation of multi-resolution observational data. These systems manifest in both static scenarios with instantaneous causal chains and temporal scenarios with evolving dynamics, complicating modeling efforts. Current methods struggle to simultaneously handle varying resolutions, capture physical relationships, model causal dependencies, and incorporate temporal dynamics, especially with inconsistently sampled data from diverse sources. We introduce Temporal-SVGDM: Score-based Variational Graphical Diffusion Model for Multi-resolution observations. Our framework constructs individual SDEs for each variable at its native resolution, then couples these SDEs through a causal score mechanism where parent nodes inform child nodes' evolution. This enables unified modeling of both immediate causal effects in static scenarios and evolving dependencies in temporal scenarios. In temporal models, state representations are processed through a sequence prediction model to predict future states based on historical patterns and causal relationships. Experiments on real-world datasets demonstrate improved prediction accuracy and causal understanding compared to existing methods, with robust performance under varying levels of background knowledge. Our model exhibits graceful degradation across different disaster types, successfully handling both static earthquake scenarios and temporal hurricane and wildfire scenarios, while maintaining superior performance even with limited data.
Spatially-Heterogeneous Causal Bayesian Networks for Seismic Multi-Hazard Estimation: A Variational Approach with Gaussian Processes and Normalizing Flows
Apr 05, 2025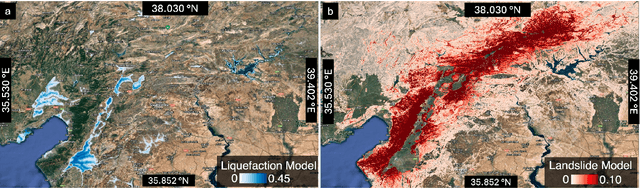



Post-earthquake hazard and impact estimation are critical for effective disaster response, yet current approaches face significant limitations. Traditional models employ fixed parameters regardless of geographical context, misrepresenting how seismic effects vary across diverse landscapes, while remote sensing technologies struggle to distinguish between co-located hazards. We address these challenges with a spatially-aware causal Bayesian network that decouples co-located hazards by modeling their causal relationships with location-specific parameters. Our framework integrates sensing observations, latent variables, and spatial heterogeneity through a novel combination of Gaussian Processes with normalizing flows, enabling us to capture how same earthquake produces different effects across varied geological and topographical features. Evaluations across three earthquakes demonstrate Spatial-VCBN achieves Area Under the Curve (AUC) improvements of up to 35.2% over existing methods. These results highlight the critical importance of modeling spatial heterogeneity in causal mechanisms for accurate disaster assessment, with direct implications for improving emergency response resource allocation.
Multi-class Seismic Building Damage Assessment from InSAR Imagery using Quadratic Variational Causal Bayesian Inference
Feb 25, 2025

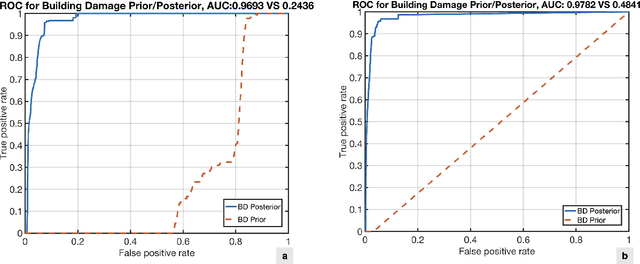
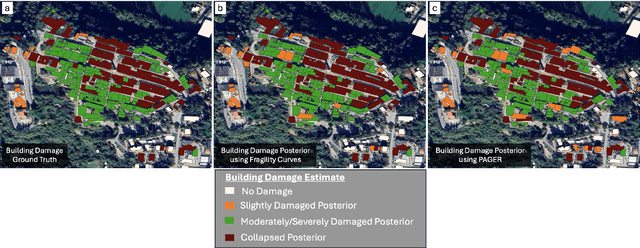
Interferometric Synthetic Aperture Radar (InSAR) technology uses satellite radar to detect surface deformation patterns and monitor earthquake impacts on buildings. While vital for emergency response planning, extracting multi-class building damage classifications from InSAR data faces challenges: overlapping damage signatures with environmental noise, computational complexity in multi-class scenarios, and the need for rapid regional-scale processing. Our novel multi-class variational causal Bayesian inference framework with quadratic variational bounds provides rigorous approximations while ensuring efficiency. By integrating InSAR observations with USGS ground failure models and building fragility functions, our approach separates building damage signals while maintaining computational efficiency through strategic pruning. Evaluation across five major earthquakes (Haiti 2021, Puerto Rico 2020, Zagreb 2020, Italy 2016, Ridgecrest 2019) shows improved damage classification accuracy (AUC: 0.94-0.96), achieving up to 35.7% improvement over existing methods. Our approach maintains high accuracy (AUC > 0.93) across all damage categories while reducing computational overhead by over 40% without requiring extensive ground truth data.
Spatial-variant causal Bayesian inference for rapid seismic ground failures and impacts estimation
Nov 18, 2024Rapid and accurate estimation of post-earthquake ground failures and building damage is critical for effective post-disaster responses. Progression in remote sensing technologies has paved the way for rapid acquisition of detailed, localized data, enabling swift hazard estimation through analysis of correlation deviations between pre- and post-quake satellite imagery. However, discerning seismic hazards and their impacts is challenged by overlapping satellite signals from ground failures, building damage, and environmental noise. Previous advancements introduced a novel causal graph-based Bayesian network that continually refines seismic ground failure and building damage estimates derived from satellite imagery, accounting for the intricate interplay among geospatial elements, seismic activity, ground failures, building structures, damages, and satellite data. However, this model's neglect of spatial heterogeneity across different locations in a seismic region limits its precision in capturing the spatial diversity of seismic effects. In this study, we pioneer an approach that accounts for spatial intricacies by introducing a spatial variable influenced by the bilateral filter to capture relationships from surrounding hazards. The bilateral filter considers both spatial proximity of neighboring hazards and their ground shaking intensity values, ensuring refined modeling of spatial relationships. This integration achieves a balance between site-specific characteristics and spatial tendencies, offering a comprehensive representation of the post-disaster landscape. Our model, tested across multiple earthquake events, demonstrates significant improvements in capturing spatial heterogeneity in seismic hazard estimation. The results highlight enhanced accuracy and efficiency in post-earthquake large-scale multi-impact estimation, effectively informing rapid disaster responses.
* This paper was accepted for 2024 WCEE conference
Near-real-time Earthquake-induced Fatality Estimation using Crowdsourced Data and Large-Language Models
Dec 04, 2023When a damaging earthquake occurs, immediate information about casualties is critical for time-sensitive decision-making by emergency response and aid agencies in the first hours and days. Systems such as Prompt Assessment of Global Earthquakes for Response (PAGER) by the U.S. Geological Survey (USGS) were developed to provide a forecast within about 30 minutes of any significant earthquake globally. Traditional systems for estimating human loss in disasters often depend on manually collected early casualty reports from global media, a process that's labor-intensive and slow with notable time delays. Recently, some systems have employed keyword matching and topic modeling to extract relevant information from social media. However, these methods struggle with the complex semantics in multilingual texts and the challenge of interpreting ever-changing, often conflicting reports of death and injury numbers from various unverified sources on social media platforms. In this work, we introduce an end-to-end framework to significantly improve the timeliness and accuracy of global earthquake-induced human loss forecasting using multi-lingual, crowdsourced social media. Our framework integrates (1) a hierarchical casualty extraction model built upon large language models, prompt design, and few-shot learning to retrieve quantitative human loss claims from social media, (2) a physical constraint-aware, dynamic-truth discovery model that discovers the truthful human loss from massive noisy and potentially conflicting human loss claims, and (3) a Bayesian updating loss projection model that dynamically updates the final loss estimation using discovered truths. We test the framework in real-time on a series of global earthquake events in 2021 and 2022 and show that our framework streamlines casualty data retrieval, achieving speed and accuracy comparable to manual methods by USGS.
Normalizing flow-based deep variational Bayesian network for seismic multi-hazards and impacts estimation from InSAR imagery
Oct 20, 2023



Onsite disasters like earthquakes can trigger cascading hazards and impacts, such as landslides and infrastructure damage, leading to catastrophic losses; thus, rapid and accurate estimates are crucial for timely and effective post-disaster responses. Interferometric Synthetic aperture radar (InSAR) data is important in providing high-resolution onsite information for rapid hazard estimation. Most recent methods using InSAR imagery signals predict a single type of hazard and thus often suffer low accuracy due to noisy and complex signals induced by co-located hazards, impacts, and irrelevant environmental changes (e.g., vegetation changes, human activities). We introduce a novel stochastic variational inference with normalizing flows derived to jointly approximate posteriors of multiple unobserved hazards and impacts from noisy InSAR imagery.
Causality-informed Rapid Post-hurricane Building Damage Detection in Large Scale from InSAR Imagery
Oct 02, 2023



Timely and accurate assessment of hurricane-induced building damage is crucial for effective post-hurricane response and recovery efforts. Recently, remote sensing technologies provide large-scale optical or Interferometric Synthetic Aperture Radar (InSAR) imagery data immediately after a disastrous event, which can be readily used to conduct rapid building damage assessment. Compared to optical satellite imageries, the Synthetic Aperture Radar can penetrate cloud cover and provide more complete spatial coverage of damaged zones in various weather conditions. However, these InSAR imageries often contain highly noisy and mixed signals induced by co-occurring or co-located building damage, flood, flood/wind-induced vegetation changes, as well as anthropogenic activities, making it challenging to extract accurate building damage information. In this paper, we introduced an approach for rapid post-hurricane building damage detection from InSAR imagery. This approach encoded complex causal dependencies among wind, flood, building damage, and InSAR imagery using a holistic causal Bayesian network. Based on the causal Bayesian network, we further jointly inferred the large-scale unobserved building damage by fusing the information from InSAR imagery with prior physical models of flood and wind, without the need for ground truth labels. Furthermore, we validated our estimation results in a real-world devastating hurricane -- the 2022 Hurricane Ian. We gathered and annotated building damage ground truth data in Lee County, Florida, and compared the introduced method's estimation results with the ground truth and benchmarked it against state-of-the-art models to assess the effectiveness of our proposed method. Results show that our method achieves rapid and accurate detection of building damage, with significantly reduced processing time compared to traditional manual inspection methods.
Black-box Prompt Learning for Pre-trained Language Models
Jan 21, 2022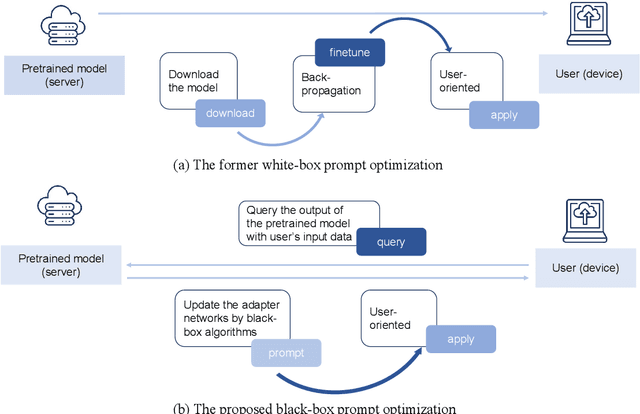
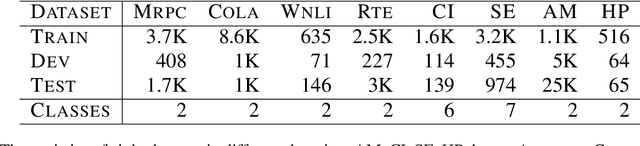
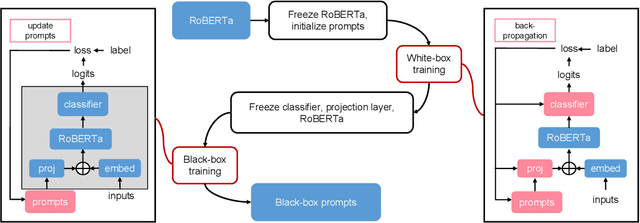
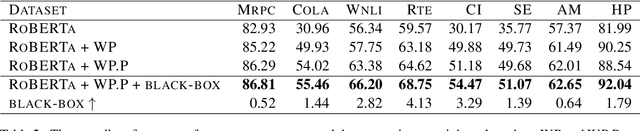
Domain-specific fine-tuning strategies for large pre-trained models received vast attention in recent years. In previously studied settings, the model architectures and parameters are tunable or at least visible, which we refer to as white-box settings. This work considers a new scenario, where we do not have access to a pre-trained model, except for its outputs given inputs, and we call this problem black-box fine-tuning. To illustrate our approach, we first introduce the black-box setting formally on text classification, where the pre-trained model is not only frozen but also invisible. We then propose our solution black-box prompt, a new technique in the prompt-learning family, which can leverage the knowledge learned by pre-trained models from the pre-training corpus. Our experiments demonstrate that the proposed method achieved the state-of-the-art performance on eight datasets. Further analyses on different human-designed objectives, prompt lengths, and intuitive explanations demonstrate the robustness and flexibility of our method.
Explainable Sentence-Level Sentiment Analysis for Amazon Product Reviews
Nov 11, 2021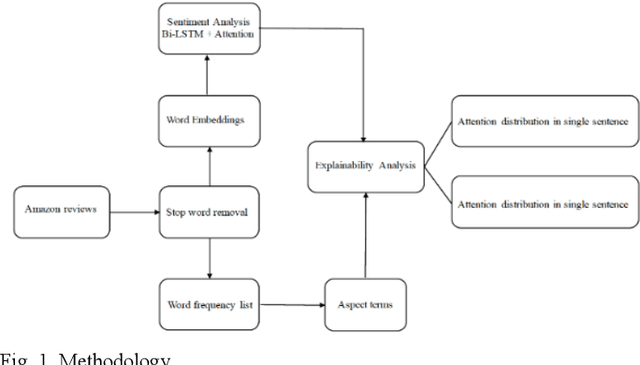
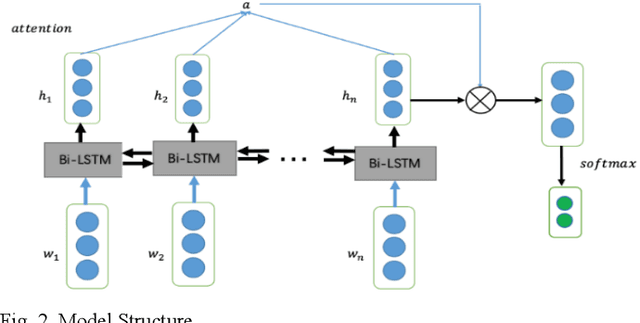
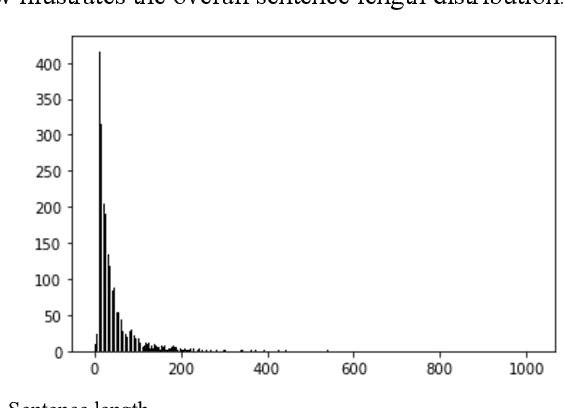
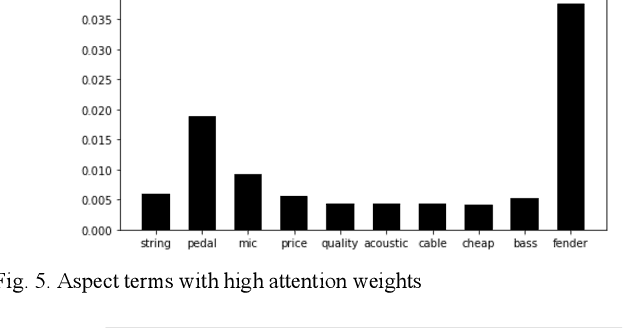
In this paper, we conduct a sentence level sentiment analysis on the product reviews from Amazon and thorough analysis on the model interpretability. For the sentiment analysis task, we use the BiLSTM model with attention mechanism. For the study of interpretability, we consider the attention weights distribution of single sentence and the attention weights of main aspect terms. The model has an accuracy of up to 0.96. And we find that the aspect terms have the same or even more attention weights than the sentimental words in sentences.