 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Prompt Learning for Pre-trained Language Models
Paper and Code
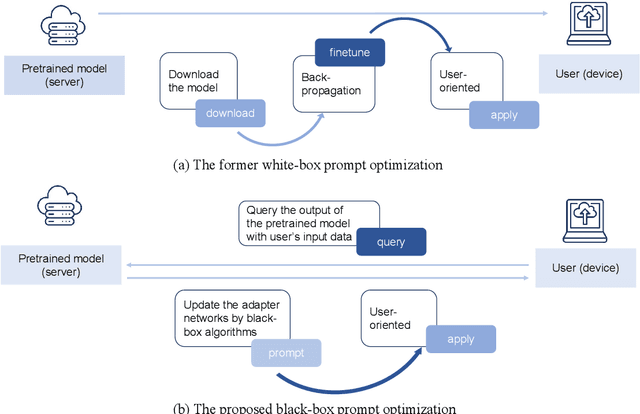
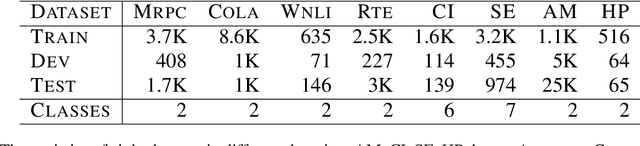
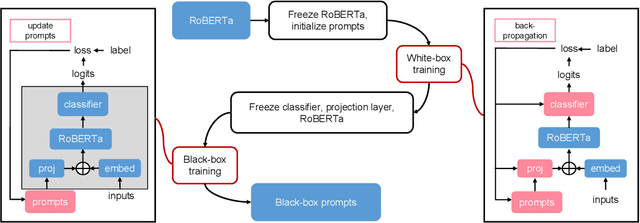
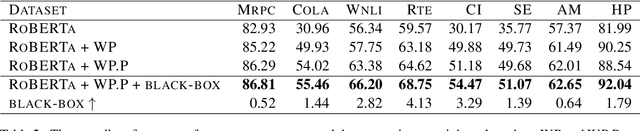
Domain-specific fine-tuning strategies for large pre-trained models received vast attention in recent years. In previously studied settings, the model architectures and parameters are tunable or at least visible, which we refer to as white-box settings. This work considers a new scenario, where we do not have access to a pre-trained model, except for its outputs given inputs, and we call this problem black-box fine-tuning. To illustrate our approach, we first introduce the black-box setting formally on text classification, where the pre-trained model is not only frozen but also invisible. We then propose our solution black-box prompt, a new technique in the prompt-learning family, which can leverage the knowledge learned by pre-trained models from the pre-training corpus. Our experiments demonstrate that the proposed method achieved the state-of-the-art performance on eight datasets. Further analyses on different human-designed objectives, prompt lengths, and intuitive explanations demonstrate the robustness and flexibility of our method.