 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy is Your Language Model a Poor Implicit Reward Model?
Jul 10, 2025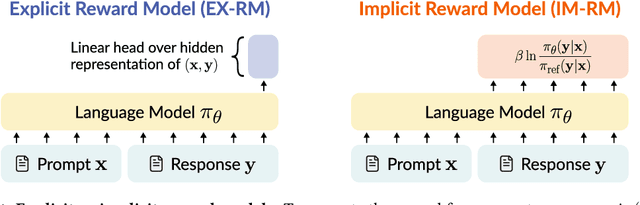
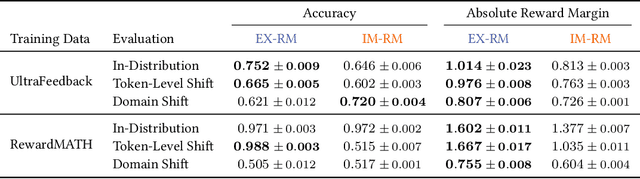
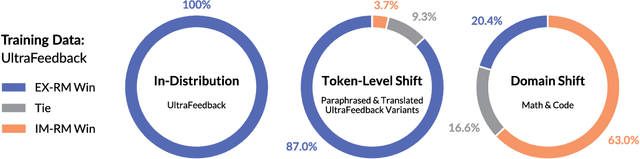
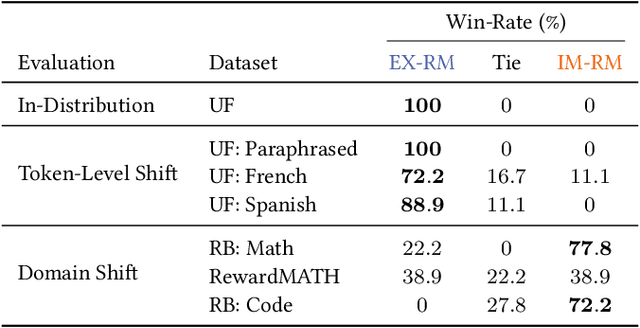
Reward models are key to language model post-training and inference pipelines. Conveniently, recent work showed that every language model defines an implicit reward model (IM-RM), without requiring any architectural changes. However, such IM-RMs tend to generalize worse, especially out-of-distribution, compared to explicit reward models (EX-RMs) that apply a dedicated linear head over the hidden representations of a language model. The existence of a generalization gap is puzzling, as EX-RMs and IM-RMs are nearly identical. They can be trained using the same data, loss function, and language model, and differ only in how the reward is computed. Towards a fundamental understanding of the implicit biases underlying different reward model types, we investigate the root cause of this gap. Our main finding, backed by theory and experiments, is that IM-RMs rely more heavily on superficial token-level cues. Consequently, they often generalize worse than EX-RMs under token-level distribution shifts, as well as in-distribution. Furthermore, we provide evidence against alternative hypotheses for the generalization gap. Most notably, we challenge the intuitive claim that IM-RMs struggle in tasks where generation is harder than verification because they can operate both as a verifier and a generator. Taken together, our results highlight that seemingly minor design choices can substantially impact the generalization behavior of reward models.
Ineq-Comp: Benchmarking Human-Intuitive Compositional Reasoning in Automated Theorem Proving on Inequalities
May 19, 2025LLM-based formal proof assistants (e.g., in Lean) hold great promise for automating mathematical discovery. But beyond syntactic correctness, do these systems truly understand mathematical structure as humans do? We investigate this question through the lens of mathematical inequalities -- a fundamental tool across many domains. While modern provers can solve basic inequalities, we probe their ability to handle human-intuitive compositionality. We introduce Ineq-Comp, a benchmark built from elementary inequalities through systematic transformations, including variable duplication, algebraic rewriting, and multi-step composition. Although these problems remain easy for humans, we find that most provers -- including Goedel, STP, and Kimina-7B -- struggle significantly. DeepSeek-Prover-V2-7B shows relative robustness -- possibly because it is trained to decompose the problems into sub-problems -- but still suffers a 20\% performance drop (pass@32). Strikingly, performance remains poor for all models even when formal proofs of the constituent parts are provided in context, revealing that the source of weakness is indeed in compositional reasoning. Our results expose a persisting gap between the generalization behavior of current AI provers and human mathematical intuition.
AdaptMI: Adaptive Skill-based In-context Math Instruction for Small Language Models
Apr 30, 2025In-context learning (ICL) allows a language model to improve its problem-solving capability when provided with suitable information in context. Since the choice of in-context information can be determined based on the problem itself, in-context learning is analogous to human learning from teachers in a classroom. Recent works (Didolkar et al., 2024a; 2024b) show that ICL performance can be improved by leveraging a frontier large language model's (LLM) ability to predict required skills to solve a problem, popularly referred to as an LLM's metacognition, and using the recommended skills to construct necessary in-context examples. While this skill-based strategy boosts ICL performance in larger models, its gains on small language models (SLMs) have been minimal, highlighting a performance gap in ICL capabilities. We investigate this gap and show that skill-based prompting can hurt SLM performance on easy questions by introducing unnecessary information, akin to cognitive overload. To address this, we introduce AdaptMI, an adaptive approach to selecting skill-based in-context Math Instructions for SLMs. Inspired by cognitive load theory from human pedagogy, our method only introduces skill-based examples when the model performs poorly. We further propose AdaptMI+, which adds examples targeted to the specific skills missing from the model's responses. On 5-shot evaluations across popular math benchmarks and five SLMs (1B--7B; Qwen, Llama), AdaptMI+ improves accuracy by up to 6% over naive skill-based strategies.
Goedel-Prover: A Frontier Model for Open-Source Automated Theorem Proving
Feb 11, 2025We introduce Goedel-Prover, an open-source large language model (LLM) that achieves the state-of-the-art (SOTA) performance in automated formal proof generation for mathematical problems. The key challenge in this field is the scarcity of formalized math statements and proofs, which we tackle in the following ways. We train statement formalizers to translate the natural language math problems from Numina into formal language (Lean 4), creating a dataset of 1.64 million formal statements. LLMs are used to check that the formal statements accurately preserve the content of the original natural language problems. We then iteratively build a large dataset of formal proofs by training a series of provers. Each prover succeeds in proving many statements that the previous ones could not, and these new proofs are added to the training set for the next prover. The final prover outperforms all existing open-source models in whole-proof generation. On the miniF2F benchmark, it achieves a 57.6% success rate (Pass@32), exceeding the previous best open-source model by 7.6%. On PutnamBench, Goedel-Prover successfully solves 7 problems (Pass@512), ranking first on the leaderboard. Furthermore, it generates 29.7K formal proofs for Lean Workbook problems, nearly doubling the 15.7K produced by earlier works.
Entropy-Regularized Process Reward Model
Dec 15, 2024



Large language models (LLMs) have shown promise in performing complex multi-step reasoning, yet they continue to struggle with mathematical reasoning, often making systematic errors. A promising solution is reinforcement learning (RL) guided by reward models, particularly those focusing on process rewards, which score each intermediate step rather than solely evaluating the final outcome. This approach is more effective at guiding policy models towards correct reasoning trajectories. In this work, we propose an entropy-regularized process reward model (ER-PRM) that integrates KL-regularized Markov Decision Processes (MDP) to balance policy optimization with the need to prevent the policy from shifting too far from its initial distribution. We derive a novel reward construction method based on the theoretical results. Our theoretical analysis shows that we could derive the optimal reward model from the initial policy sampling. Our empirical experiments on the MATH and GSM8K benchmarks demonstrate that ER-PRM consistently outperforms existing process reward models, achieving 1% improvement on GSM8K and 2-3% improvement on MATH under best-of-N evaluation, and more than 1% improvement under RLHF. These results highlight the efficacy of entropy-regularization in enhancing LLMs' reasoning capabilities.
On the Limited Generalization Capability of the Implicit Reward Model Induced by Direct Preference Optimization
Sep 05, 2024



Reinforcement Learning from Human Feedback (RLHF) is an effective approach for aligning language models to human preferences. Central to RLHF is learning a reward function for scoring human preferences. Two main approaches for learning a reward model are 1) training an EXplicit Reward Model (EXRM) as in RLHF, and 2) using an implicit reward learned from preference data through methods such as Direct Preference Optimization (DPO). Prior work has shown that the implicit reward model of DPO (denoted as DPORM) can approximate an EXRM in the limit. DPORM's effectiveness directly implies the optimality of the learned policy, and also has practical implication for LLM alignment methods including iterative DPO. However, it is unclear how well DPORM empirically matches the performance of EXRM. This work studies the accuracy at distinguishing preferred and rejected answers for both DPORM and EXRM. Our findings indicate that even though DPORM fits the training dataset comparably, it generalizes less effectively than EXRM, especially when the validation datasets contain distribution shifts. Across five out-of-distribution settings, DPORM has a mean drop in accuracy of 3% and a maximum drop of 7%. These findings highlight that DPORM has limited generalization ability and substantiates the integration of an explicit reward model in iterative DPO approaches.
Localize-and-Stitch: Efficient Model Merging via Sparse Task Arithmetic
Aug 24, 2024Model merging offers an effective strategy to combine the strengths of multiple finetuned models into a unified model that preserves the specialized capabilities of each. Existing methods merge models in a global manner, performing arithmetic operations across all model parameters. However, such global merging often leads to task interference, degrading the performance of the merged model. In this work, we introduce Localize-and-Stitch, a novel approach that merges models in a localized way. Our algorithm works in two steps: i) Localization: identify tiny ($1\%$ of the total parameters) localized regions in the finetuned models containing essential skills for the downstream tasks, and ii) Stitching: reintegrate only these essential regions back into the pretrained model for task synergy. We demonstrate that our approach effectively locates sparse regions responsible for finetuned performance, and the localized regions could be treated as compact and interpretable representations of the finetuned models (tasks). Empirically, we evaluate our method on various vision and language benchmarks, showing that it outperforms existing model merging methods under different data availability scenarios. Beyond strong empirical performance, our algorithm also facilitates model compression and preserves pretrained knowledge, enabling flexible and continual skill composition from multiple finetuned models with minimal storage and computational overhead. Our code is available at https://github.com/yifei-he/Localize-and-Stitch.
Leveraging Invariant Principle for Heterophilic Graph Structure Distribution Shifts
Aug 18, 2024



Heterophilic Graph Neural Networks (HGNNs) have shown promising results for semi-supervised learning tasks on graphs. Notably, most real-world heterophilic graphs are composed of a mixture of nodes with different neighbor patterns, exhibiting local node-level homophilic and heterophilic structures. However, existing works are only devoted to designing better HGNN backbones or architectures for node classification tasks on heterophilic and homophilic graph benchmarks simultaneously, and their analyses of HGNN performance with respect to nodes are only based on the determined data distribution without exploring the effect caused by this structural difference between training and testing nodes. How to learn invariant node representations on heterophilic graphs to handle this structure difference or distribution shifts remains unexplored. In this paper, we first discuss the limitations of previous graph-based invariant learning methods from the perspective of data augmentation. Then, we propose \textbf{HEI}, a framework capable of generating invariant node representations through incorporating heterophily information to infer latent environments without augmentation, which are then used for invariant prediction, under heterophilic graph structure distribution shifts. We theoretically show that our proposed method can achieve guaranteed performance under heterophilic graph structure distribution shifts. Extensive experiments on various benchmarks and backbones can also demonstrate the effectiveness of our method compared with existing state-of-the-art baselines.
Regularizing Hidden States Enables Learning Generalizable Reward Model for LLMs
Jun 14, 2024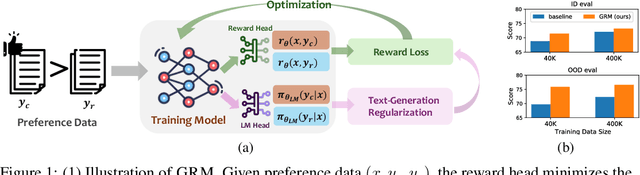
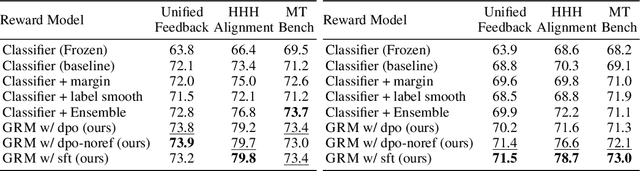


Reward models trained on human preference data have been proven to be effective for aligning Large Language Models (LLMs) with human intent within the reinforcement learning from human feedback (RLHF) framework. However, the generalization capabilities of current reward models to unseen prompts and responses are limited. This limitation can lead to an unexpected phenomenon known as reward over-optimization, where excessive optimization of rewards results in a decline in actual performance. While previous research has advocated for constraining policy optimization, our study proposes a novel approach to enhance the reward model's generalization ability against distribution shifts by regularizing the hidden states. Specifically, we retain the base model's language model head and incorporate a suite of text-generation losses to preserve the hidden states' text generation capabilities, while concurrently learning a reward head behind the same hidden states. Our experimental results demonstrate that the introduced regularization technique markedly improves the accuracy of learned reward models across a variety of out-of-distribution (OOD) tasks and effectively alleviate the over-optimization issue in RLHF, offering a more reliable and robust preference learning paradigm.
On the Benefits of Over-parameterization for Out-of-Distribution Generalization
Mar 26, 2024In recent years, machine learning models have achieved success based on the independently and identically distributed assumption. However, this assumption can be easily violated in real-world applications, leading to the Out-of-Distribution (OOD) problem. Understanding how modern over-parameterized DNNs behave under non-trivial natural distributional shifts is essential, as current theoretical understanding is insufficient. Existing theoretical works often provide meaningless results for over-parameterized models in OOD scenarios or even contradict empirical findings. To this end, we are investigating the performance of the over-parameterized model in terms of OOD generalization under the general benign overfitting conditions. Our analysis focuses on a random feature model and examines non-trivial natural distributional shifts, where the benign overfitting estimators demonstrate a constant excess OOD loss, despite achieving zero excess in-distribution (ID) loss. We demonstrate that in this scenario, further increasing the model's parameterization can significantly reduce the OOD loss. Intuitively, the variance term of ID loss remains low due to orthogonality of long-tail features, meaning overfitting noise during training generally doesn't raise testing loss. However, in OOD cases, distributional shift increases the variance term. Thankfully, the inherent shift is unrelated to individual x, maintaining the orthogonality of long-tail features. Expanding the hidden dimension can additionally improve this orthogonality by mapping the features into higher-dimensional spaces, thereby reducing the variance term. We further show that model ensembles also improve OOD loss, akin to increasing model capacity. These insights explain the empirical phenomenon of enhanced OOD generalization through model ensembles, supported by consistent simulations with theoretical results.