 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Knowledge Transfer under Data Constraints via Lexical Interventions
May 22, 2026Cross-lingual knowledge transfer is critical for building high-performing multilingual language models for languages with insufficient training data. When target language data is scarce, the knowledge required for many downstream tasks involving scientific reasoning, commonsense inference, and world knowledge must be acquired primarily from the high-resource language, making effective knowledge transfer essential. Existing methods for improving such cross-lingual knowledge transfer require large amounts of parallel data, translation systems, auxiliary models, or additional training stages that are largely unavailable for many languages. We propose LINK - a data-level intervention method that improves knowledge transfer during model pretraining through lexical substitutions in high-resource part of pretraining data using bilingual vocabularies. For a given replacement ratio, randomly selected words in a portion of the high-resource (English) training corpus are swapped with their word-level translations, requiring no additional model training and only a bilingual vocabulary, which can be obtained at near-zero cost for virtually any language. Evaluation on eight languages across five model sizes shows notable improvements on downstream tasks in the target language, with up to a 2x speedup in training to reach equivalent performance.
Mix, Don't Tune: Bilingual Pre-Training Outperforms Hyperparameter Search in Data-Constrained Settings
May 13, 2026For most languages of the world, language model pre-training operates in a data-constrained regime where models must repeat their training data many times, degrading generalization. Two remedies exist: aggressive hyperparameter tuning such as high weight decay, and mixing in data from a high-resource auxiliary language to directly aid the low-resource target. While hyperparameter tuning regularizes the model by shrinking weights to restrict network capacity, auxiliary data mixing uses a tunable mixing ratio to expand the training distribution and diversify the training signal with new knowledge. Both offer a principled way to improve training in a data-constrained domain. We compare these levers systematically across four model scales from 150M to 1.43B parameters, using Arabic as the low-resource target and English as the auxiliary, over approximately 1000 pre-training runs. Three findings emerge. First, mixing yields larger improvements than hyperparameter tuning on both validation loss and downstream task accuracy, and the gap grows with model size. Second, we quantify how much mixing helps: it boosts performance by an amount equivalent to 2--3$\times$ the unique target data on validation loss and 2--13$\times$ on downstream task accuracy, with the gain scaling steeply with model size. Third, this divergence reveals that target-language validation loss systematically underestimates mixing's value. Mixing regularizes by diversifying the training signal and contributes knowledge the repeated target corpus cannot supply; validation loss captures only the first effect. Our practical recommendations are: mix in a high-resource language, prioritize the mixing ratio over hyperparameter tuning, and transfer hyperparameters from a small proxy model via $μ$P.
Scaling Laws for Mixture Pretraining Under Data Constraints
May 12, 2026As language models scale, the amount of data they require grows -- yet many target data sources, such as low-resource languages or specialized domains, are inherently limited in size. A common strategy is to mix this scarce but valuable target data with abundant generic data, which presents a fundamental trade-off: too little target data in the mixture underexposes the model to the target domain, while too much target data repeats the same examples excessively, yielding diminishing returns and eventual overfitting. We study this trade-off across more than 2,000 language-model training runs spanning multiple model and target dataset sizes, as well as several data types, including multilingual, domain-specific, and quality-filtered mixtures. Across all settings, we find that repetition is a central driver of target-domain performance, and that mixture training tolerates much higher repetition than single-source training: scarce target corpora can be reused 15-20 times, with the optimal number of repetitions depending on the target data size, compute budget, and model scale. Next, we introduce a repetition-aware mixture scaling law that accounts for the decreasing value of repeated target tokens and the regularizing role of generic data. Optimizing the scaling law provides a principled way to compute effective mixture configurations, yielding practical mixture recommendations for pretraining under data constraints.
Optimal Splitting of Language Models from Mixtures to Specialized Domains
Mar 19, 2026Language models achieve impressive performance on a variety of knowledge, language, and reasoning tasks due to the scale and diversity of pretraining data available. The standard training recipe is a two-stage paradigm: pretraining first on the full corpus of data followed by specialization on a subset of high quality, specialized data from the full corpus. In the multi-domain setting, this involves continued pretraining of multiple models on each specialized domain, referred to as split model training. We propose a method for pretraining multiple models independently over a general pretraining corpus, and determining the optimal compute allocation between pretraining and continued pretraining using scaling laws. Our approach accurately predicts the loss of a model of size N with D pretraining and D' specialization tokens, and extrapolates to larger model sizes and number of tokens. Applied to language model training, our approach improves performance consistently across common sense knowledge and reasoning benchmarks across different model sizes and compute budgets.
Assessing the Role of Data Quality in Training Bilingual Language Models
Jun 15, 2025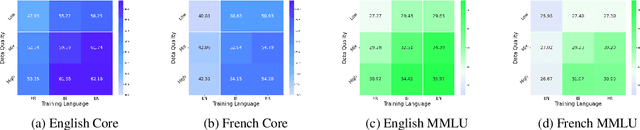
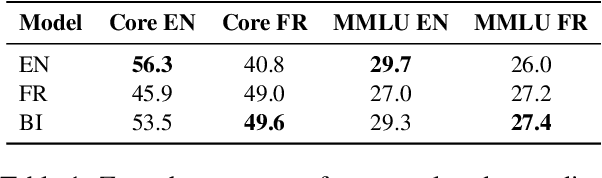
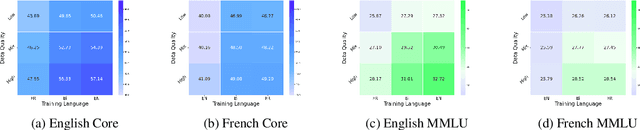
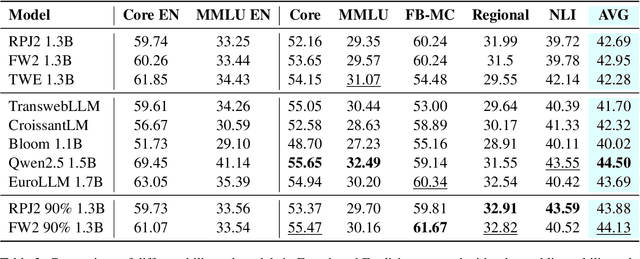
Bilingual and multilingual language models offer a promising path toward scaling NLP systems across diverse languages and users. However, their performance often varies wildly between languages as prior works show that adding more languages can degrade performance for some languages (such as English), while improving others (typically more data constrained languages). In this work, we investigate causes of these inconsistencies by comparing bilingual and monolingual language models. Our analysis reveals that unequal data quality, not just data quantity, is a major driver of performance degradation in bilingual settings. We propose a simple yet effective data filtering strategy to select higher-quality bilingual training data with only high quality English data. Applied to French, German, and Chinese, our approach improves monolingual performance by 2-4% and reduces bilingual model performance gaps to 1%. These results highlight the overlooked importance of data quality in multilingual pretraining and offer a practical recipe for balancing performance.
Proxy-FDA: Proxy-based Feature Distribution Alignment for Fine-tuning Vision Foundation Models without Forgetting
May 30, 2025



Vision foundation models pre-trained on massive data encode rich representations of real-world concepts, which can be adapted to downstream tasks by fine-tuning. However, fine-tuning foundation models on one task often leads to the issue of concept forgetting on other tasks. Recent methods of robust fine-tuning aim to mitigate forgetting of prior knowledge without affecting the fine-tuning performance. Knowledge is often preserved by matching the original and fine-tuned model weights or feature pairs. However, such point-wise matching can be too strong, without explicit awareness of the feature neighborhood structures that encode rich knowledge as well. We propose a novel regularization method Proxy-FDA that explicitly preserves the structural knowledge in feature space. Proxy-FDA performs Feature Distribution Alignment (using nearest neighbor graphs) between the pre-trained and fine-tuned feature spaces, and the alignment is further improved by informative proxies that are generated dynamically to increase data diversity. Experiments show that Proxy-FDA significantly reduces concept forgetting during fine-tuning, and we find a strong correlation between forgetting and a distributional distance metric (in comparison to L2 distance). We further demonstrate Proxy-FDA's benefits in various fine-tuning settings (end-to-end, few-shot and continual tuning) and across different tasks like image classification, captioning and VQA.
Discriminating Form and Meaning in Multilingual Models with Minimal-Pair ABX Tasks
May 23, 2025We introduce a set of training-free ABX-style discrimination tasks to evaluate how multilingual language models represent language identity (form) and semantic content (meaning). Inspired from speech processing, these zero-shot tasks measure whether minimal differences in representation can be reliably detected. This offers a flexible and interpretable alternative to probing. Applied to XLM-R (Conneau et al, 2020) across pretraining checkpoints and layers, we find that language discrimination declines over training and becomes concentrated in lower layers, while meaning discrimination strengthens over time and stabilizes in deeper layers. We then explore probing tasks, showing some alignment between our metrics and linguistic learning performance. Our results position ABX tasks as a lightweight framework for analyzing the structure of multilingual representations.
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Feb 21, 2025Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions -- a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in mLLMs. We identify the neurons to manipulate for a given language and introspect the embedding space of mLLMs pre- and post-manipulation. We show that modifying the mLLM's activations changes its embedding space such that cross-lingual alignment is enhanced. Further, we show that the changes to the embedding space translate into improved downstream performance on retrieval tasks, with up to 2x improvements in top-1 accuracy on cross-lingual retrieval.
Analyze the Neurons, not the Embeddings: Understanding When and Where LLM Representations Align with Humans
Feb 20, 2025Modern large language models (LLMs) achieve impressive performance on some tasks, while exhibiting distinctly non-human-like behaviors on others. This raises the question of how well the LLM's learned representations align with human representations. In this work, we introduce a novel approach to the study of representation alignment: we adopt a method from research on activation steering to identify neurons responsible for specific concepts (e.g., 'cat') and then analyze the corresponding activation patterns. Our findings reveal that LLM representations closely align with human representations inferred from behavioral data. Notably, this alignment surpasses that of word embeddings, which have been center stage in prior work on human and model alignment. Additionally, our approach enables a more granular view of how LLMs represent concepts. Specifically, we show that LLMs organize concepts in a way that reflects hierarchical relationships interpretable to humans (e.g., 'animal'-'dog').
Soup-of-Experts: Pretraining Specialist Models via Parameters Averaging
Feb 03, 2025Machine learning models are routinely trained on a mixture of different data domains. Different domain weights yield very different downstream performances. We propose the Soup-of-Experts, a novel architecture that can instantiate a model at test time for any domain weights with minimal computational cost and without re-training the model. Our architecture consists of a bank of expert parameters, which are linearly combined to instantiate one model. We learn the linear combination coefficients as a function of the input domain weights. To train this architecture, we sample random domain weights, instantiate the corresponding model, and backprop through one batch of data sampled with these domain weights. We demonstrate how our approach obtains small specialized models on several language modeling tasks quickly. Soup-of-Experts are particularly appealing when one needs to ship many different specialist models quickly under a model size constraint.