 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLEx: Language Modeling with Few-shot Language Explanations
Jan 07, 2026Language models have become effective at a wide range of tasks, from math problem solving to open-domain question answering. However, they still make mistakes, and these mistakes are often repeated across related queries. Natural language explanations can help correct these errors, but collecting them at scale may be infeasible, particularly in domains where expert annotators are required. To address this issue, we introduce FLEx ($\textbf{F}$ew-shot $\textbf{L}$anguage $\textbf{Ex}$planations), a method for improving model behavior using a small number of explanatory examples. FLEx selects representative model errors using embedding-based clustering, verifies that the associated explanations correct those errors, and summarizes them into a prompt prefix that is prepended at inference-time. This summary guides the model to avoid similar errors on new inputs, without modifying model weights. We evaluate FLEx on CounterBench, GSM8K, and ReasonIF. We find that FLEx consistently outperforms chain-of-thought (CoT) prompting across all three datasets and reduces up to 83\% of CoT's remaining errors.
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Feb 21, 2025Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions -- a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in mLLMs. We identify the neurons to manipulate for a given language and introspect the embedding space of mLLMs pre- and post-manipulation. We show that modifying the mLLM's activations changes its embedding space such that cross-lingual alignment is enhanced. Further, we show that the changes to the embedding space translate into improved downstream performance on retrieval tasks, with up to 2x improvements in top-1 accuracy on cross-lingual retrieval.
Schema Augmentation for Zero-Shot Domain Adaptation in Dialogue State Tracking
Oct 31, 2024
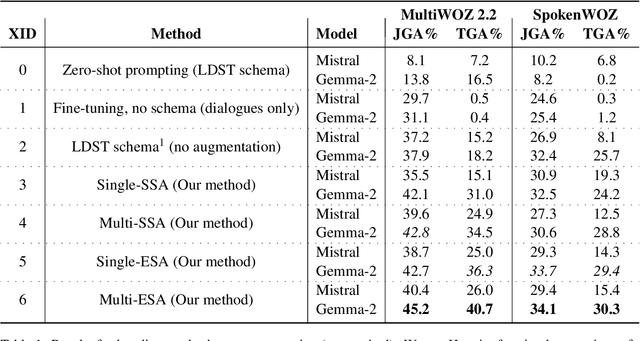
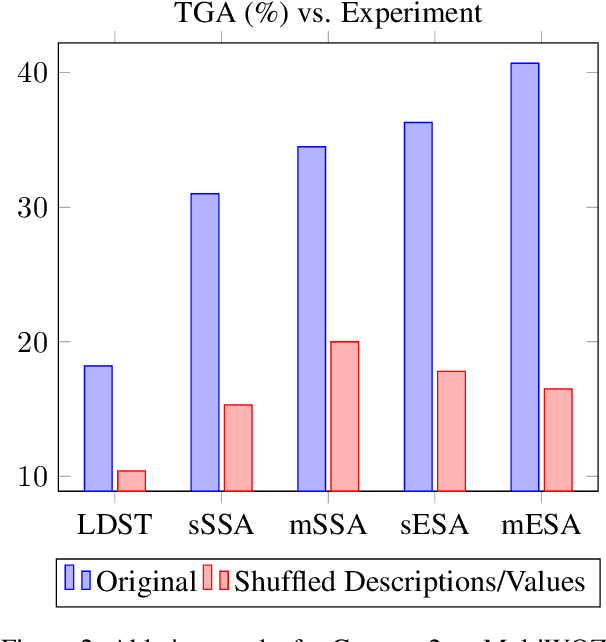
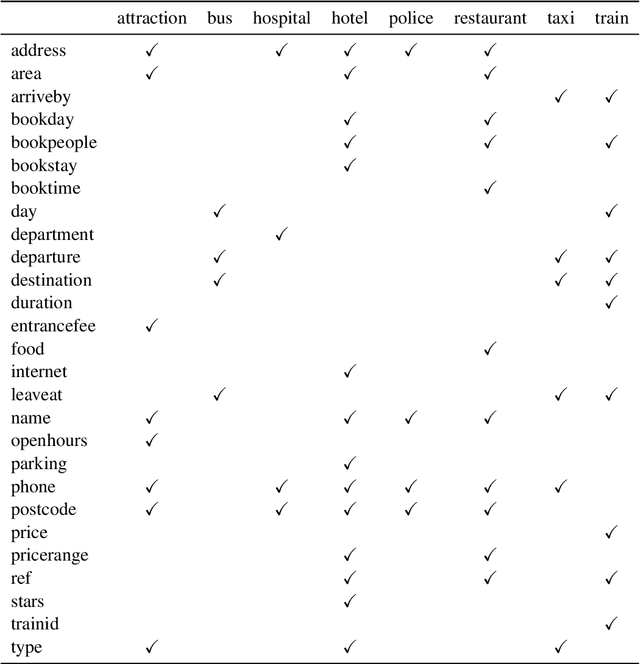
Zero-shot domain adaptation for dialogue state tracking (DST) remains a challenging problem in task-oriented dialogue (TOD) systems, where models must generalize to target domains unseen at training time. Current large language model approaches for zero-shot domain adaptation rely on prompting to introduce knowledge pertaining to the target domains. However, their efficacy strongly depends on prompt engineering, as well as the zero-shot ability of the underlying language model. In this work, we devise a novel data augmentation approach, Schema Augmentation, that improves the zero-shot domain adaptation of language models through fine-tuning. Schema Augmentation is a simple but effective technique that enhances generalization by introducing variations of slot names within the schema provided in the prompt. Experiments on MultiWOZ and SpokenWOZ showed that the proposed approach resulted in a substantial improvement over the baseline, in some experiments achieving over a twofold accuracy gain over unseen domains while maintaining equal or superior performance over all domains.
cPAPERS: A Dataset of Situated and Multimodal Interactive Conversations in Scientific Papers
Jun 12, 2024An emerging area of research in situated and multimodal interactive conversations (SIMMC) includes interactions in scientific papers. Since scientific papers are primarily composed of text, equations, figures, and tables, SIMMC methods must be developed specifically for each component to support the depth of inquiry and interactions required by research scientists. This work introduces Conversational Papers (cPAPERS), a dataset of conversational question-answer pairs from reviews of academic papers grounded in these paper components and their associated references from scientific documents available on arXiv. We present a data collection strategy to collect these question-answer pairs from OpenReview and associate them with contextual information from LaTeX source files. Additionally, we present a series of baseline approaches utilizing Large Language Models (LLMs) in both zero-shot and fine-tuned configurations to address the cPAPERS dataset.
iTBLS: A Dataset of Interactive Conversations Over Tabular Information
Apr 19, 2024



This paper introduces Interactive Tables (iTBLS), a dataset of interactive conversations situated in tables from scientific articles. This dataset is designed to facilitate human-AI collaborative problem-solving through AI-powered multi-task tabular capabilities. In contrast to prior work that models interactions as factoid QA or procedure synthesis, iTBLS broadens the scope of interactions to include mathematical reasoning, natural language manipulation, and expansion of existing tables from natural language conversation by delineating interactions into one of three tasks: interpretation, modification, or generation. Additionally, the paper presents a suite of baseline approaches to iTBLS, utilizing zero-shot prompting and parameter-efficient fine-tuning for different computing situations. We also introduce a novel multi-step approach and show how it can be leveraged in conjunction with parameter-efficient fine-tuning to achieve the state-of-the-art on iTBLS; outperforming standard parameter-efficient fine-tuning by up to 15% on interpretation, 18% on modification, and 38% on generation.
gTBLS: Generating Tables from Text by Conditional Question Answering
Mar 21, 2024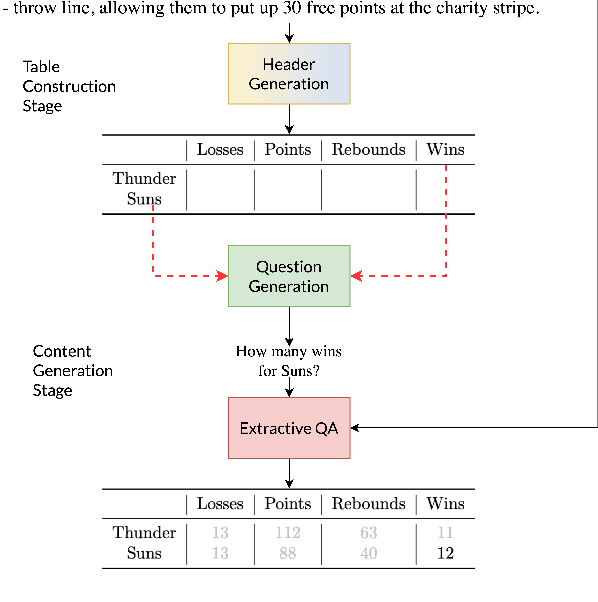
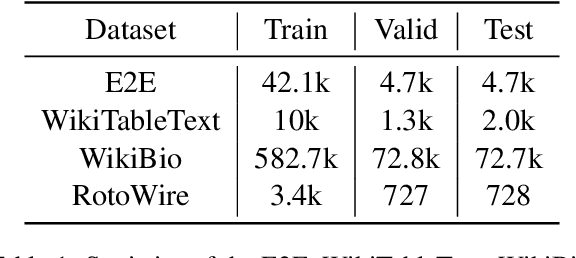

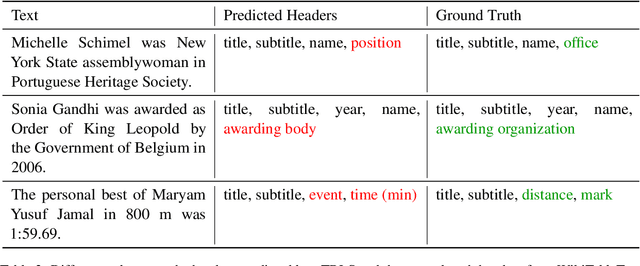
Distilling large, unstructured text into a structured, condensed form such as tables is an open research problem. One of the primary challenges in automatically generating tables is ensuring their syntactic validity. Prior approaches address this challenge by including additional parameters in the Transformer's attention mechanism to attend to specific rows and column headers. In contrast to this single-stage method, this paper presents a two-stage approach called Generative Tables (gTBLS). The first stage infers table structure (row and column headers) from the text. The second stage formulates questions using these headers and fine-tunes a causal language model to answer them. Furthermore, the gTBLS approach is amenable to the utilization of pre-trained Large Language Models in a zero-shot configuration, presenting a solution for table generation in situations where fine-tuning is not feasible. gTBLS improves prior approaches by up to 10% in BERTScore on the table construction task and up to 20% on the table content generation task of the E2E, WikiTableText, WikiBio, and RotoWire datasets.
SYNDICOM: Improving Conversational Commonsense with Error-Injection and Natural Language Feedback
Sep 18, 2023



Commonsense reasoning is a critical aspect of human communication. Despite recent advances in conversational AI driven by large language models, commonsense reasoning remains a challenging task. In this work, we introduce SYNDICOM - a method for improving commonsense in dialogue response generation. SYNDICOM consists of two components. The first component is a dataset composed of commonsense dialogues created from a knowledge graph and synthesized into natural language. This dataset includes both valid and invalid responses to dialogue contexts, along with natural language feedback (NLF) for the invalid responses. The second contribution is a two-step procedure: training a model to predict natural language feedback (NLF) for invalid responses, and then training a response generation model conditioned on the predicted NLF, the invalid response, and the dialogue. SYNDICOM is scalable and does not require reinforcement learning. Empirical results on three tasks are evaluated using a broad range of metrics. SYNDICOM achieves a relative improvement of 53% over ChatGPT on ROUGE1, and human evaluators prefer SYNDICOM over ChatGPT 57% of the time. We will publicly release the code and the full dataset.
Multimodal Conversational AI: A Survey of Datasets and Approaches
May 13, 2022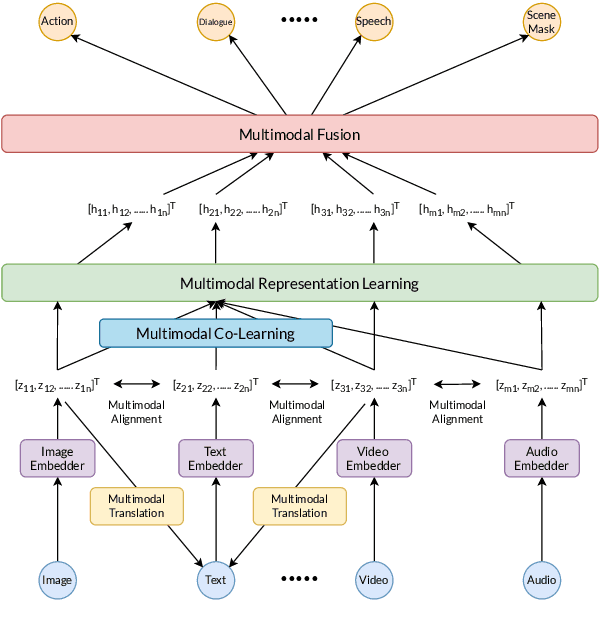


As humans, we experience the world with all our senses or modalities (sound, sight, touch, smell, and taste). We use these modalities, particularly sight and touch, to convey and interpret specific meanings. Multimodal expressions are central to conversations; a rich set of modalities amplify and often compensate for each other. A multimodal conversational AI system answers questions, fulfills tasks, and emulates human conversations by understanding and expressing itself via multiple modalities. This paper motivates, defines, and mathematically formulates the multimodal conversational research objective. We provide a taxonomy of research required to solve the objective: multimodal representation, fusion, alignment, translation, and co-learning. We survey state-of-the-art datasets and approaches for each research area and highlight their limiting assumptions. Finally, we identify multimodal co-learning as a promising direction for multimodal conversational AI research.