 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Intersectional Bias in Large Language Models using Confidence Disparities in Coreference Resolution
Aug 09, 2025



Large language models (LLMs) have achieved impressive performance, leading to their widespread adoption as decision-support tools in resource-constrained contexts like hiring and admissions. There is, however, scientific consensus that AI systems can reflect and exacerbate societal biases, raising concerns about identity-based harm when used in critical social contexts. Prior work has laid a solid foundation for assessing bias in LLMs by evaluating demographic disparities in different language reasoning tasks. In this work, we extend single-axis fairness evaluations to examine intersectional bias, recognizing that when multiple axes of discrimination intersect, they create distinct patterns of disadvantage. We create a new benchmark called WinoIdentity by augmenting the WinoBias dataset with 25 demographic markers across 10 attributes, including age, nationality, and race, intersected with binary gender, yielding 245,700 prompts to evaluate 50 distinct bias patterns. Focusing on harms of omission due to underrepresentation, we investigate bias through the lens of uncertainty and propose a group (un)fairness metric called Coreference Confidence Disparity which measures whether models are more or less confident for some intersectional identities than others. We evaluate five recently published LLMs and find confidence disparities as high as 40% along various demographic attributes including body type, sexual orientation and socio-economic status, with models being most uncertain about doubly-disadvantaged identities in anti-stereotypical settings. Surprisingly, coreference confidence decreases even for hegemonic or privileged markers, indicating that the recent impressive performance of LLMs is more likely due to memorization than logical reasoning. Notably, these are two independent failures in value alignment and validity that can compound to cause social harm.
Aligning LLMs by Predicting Preferences from User Writing Samples
May 27, 2025Accommodating human preferences is essential for creating aligned LLM agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs acting as writing agents to infer a description of user preferences. Agent alignment then comes from conditioning on the inferred preference description. However, existing methods often produce generic preference descriptions that fail to capture the unique and individualized nature of human preferences. This paper introduces PROSE, a method designed to enhance the precision of preference descriptions inferred from user writing samples. PROSE incorporates two key elements: (1) iterative refinement of inferred preferences, and (2) verification of inferred preferences across multiple user writing samples. We evaluate PROSE with several LLMs (i.e., Qwen2.5 7B and 72B Instruct, GPT-mini, and GPT-4o) on a summarization and an email writing task. We find that PROSE more accurately infers nuanced human preferences, improving the quality of the writing agent's generations over CIPHER (a state-of-the-art method for inferring preferences) by 33\%. Lastly, we demonstrate that ICL and PROSE are complementary methods, and combining them provides up to a 9\% improvement over ICL alone.
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Feb 21, 2025Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions -- a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in mLLMs. We identify the neurons to manipulate for a given language and introspect the embedding space of mLLMs pre- and post-manipulation. We show that modifying the mLLM's activations changes its embedding space such that cross-lingual alignment is enhanced. Further, we show that the changes to the embedding space translate into improved downstream performance on retrieval tasks, with up to 2x improvements in top-1 accuracy on cross-lingual retrieval.
Analyze the Neurons, not the Embeddings: Understanding When and Where LLM Representations Align with Humans
Feb 20, 2025Modern large language models (LLMs) achieve impressive performance on some tasks, while exhibiting distinctly non-human-like behaviors on others. This raises the question of how well the LLM's learned representations align with human representations. In this work, we introduce a novel approach to the study of representation alignment: we adopt a method from research on activation steering to identify neurons responsible for specific concepts (e.g., 'cat') and then analyze the corresponding activation patterns. Our findings reveal that LLM representations closely align with human representations inferred from behavioral data. Notably, this alignment surpasses that of word embeddings, which have been center stage in prior work on human and model alignment. Additionally, our approach enables a more granular view of how LLMs represent concepts. Specifically, we show that LLMs organize concepts in a way that reflects hierarchical relationships interpretable to humans (e.g., 'animal'-'dog').
On the Way to LLM Personalization: Learning to Remember User Conversations
Nov 20, 2024



Large Language Models (LLMs) have quickly become an invaluable assistant for a variety of tasks. However, their effectiveness is constrained by their ability to tailor responses to human preferences and behaviors via personalization. Prior work in LLM personalization has largely focused on style transfer or incorporating small factoids about the user, as knowledge injection remains an open challenge. In this paper, we explore injecting knowledge of prior conversations into LLMs to enable future work on less redundant, personalized conversations. We identify two real-world constraints: (1) conversations are sequential in time and must be treated as such during training, and (2) per-user personalization is only viable in parameter-efficient settings. To this aim, we propose PLUM, a pipeline performing data augmentation for up-sampling conversations as question-answer pairs, that are then used to finetune a low-rank adaptation adapter with a weighted cross entropy loss. Even in this first exploration of the problem, we perform competitively with baselines such as RAG, attaining an accuracy of 81.5% across 100 conversations.
PREDICT: Preference Reasoning by Evaluating Decomposed preferences Inferred from Candidate Trajectories
Oct 08, 2024



Accommodating human preferences is essential for creating AI agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs to infer preferences from user interactions, but they often produce broad and generic preferences, failing to capture the unique and individualized nature of human preferences. This paper introduces PREDICT, a method designed to enhance the precision and adaptability of inferring preferences. PREDICT incorporates three key elements: (1) iterative refinement of inferred preferences, (2) decomposition of preferences into constituent components, and (3) validation of preferences across multiple trajectories. We evaluate PREDICT on two distinct environments: a gridworld setting and a new text-domain environment (PLUME). PREDICT more accurately infers nuanced human preferences improving over existing baselines by 66.2\% (gridworld environment) and 41.0\% (PLUME).
On the Limited Generalization Capability of the Implicit Reward Model Induced by Direct Preference Optimization
Sep 05, 2024



Reinforcement Learning from Human Feedback (RLHF) is an effective approach for aligning language models to human preferences. Central to RLHF is learning a reward function for scoring human preferences. Two main approaches for learning a reward model are 1) training an EXplicit Reward Model (EXRM) as in RLHF, and 2) using an implicit reward learned from preference data through methods such as Direct Preference Optimization (DPO). Prior work has shown that the implicit reward model of DPO (denoted as DPORM) can approximate an EXRM in the limit. DPORM's effectiveness directly implies the optimality of the learned policy, and also has practical implication for LLM alignment methods including iterative DPO. However, it is unclear how well DPORM empirically matches the performance of EXRM. This work studies the accuracy at distinguishing preferred and rejected answers for both DPORM and EXRM. Our findings indicate that even though DPORM fits the training dataset comparably, it generalizes less effectively than EXRM, especially when the validation datasets contain distribution shifts. Across five out-of-distribution settings, DPORM has a mean drop in accuracy of 3% and a maximum drop of 7%. These findings highlight that DPORM has limited generalization ability and substantiates the integration of an explicit reward model in iterative DPO approaches.
Hindsight PRIORs for Reward Learning from Human Preferences
Apr 12, 2024Preference based Reinforcement Learning (PbRL) removes the need to hand specify a reward function by learning a reward from preference feedback over policy behaviors. Current approaches to PbRL do not address the credit assignment problem inherent in determining which parts of a behavior most contributed to a preference, which result in data intensive approaches and subpar reward functions. We address such limitations by introducing a credit assignment strategy (Hindsight PRIOR) that uses a world model to approximate state importance within a trajectory and then guides rewards to be proportional to state importance through an auxiliary predicted return redistribution objective. Incorporating state importance into reward learning improves the speed of policy learning, overall policy performance, and reward recovery on both locomotion and manipulation tasks. For example, Hindsight PRIOR recovers on average significantly (p<0.05) more reward on MetaWorld (20%) and DMC (15%). The performance gains and our ablations demonstrate the benefits even a simple credit assignment strategy can have on reward learning and that state importance in forward dynamics prediction is a strong proxy for a state's contribution to a preference decision. Code repository can be found at https://github.com/apple/ml-rlhf-hindsight-prior.
Sample-Efficient Preference-based Reinforcement Learning with Dynamics Aware Rewards
Feb 28, 2024Preference-based reinforcement learning (PbRL) aligns a robot behavior with human preferences via a reward function learned from binary feedback over agent behaviors. We show that dynamics-aware reward functions improve the sample efficiency of PbRL by an order of magnitude. In our experiments we iterate between: (1) learning a dynamics-aware state-action representation (z^{sa}) via a self-supervised temporal consistency task, and (2) bootstrapping the preference-based reward function from (z^{sa}), which results in faster policy learning and better final policy performance. For example, on quadruped-walk, walker-walk, and cheetah-run, with 50 preference labels we achieve the same performance as existing approaches with 500 preference labels, and we recover 83\% and 66\% of ground truth reward policy performance versus only 38\% and 21\%. The performance gains demonstrate the benefits of explicitly learning a dynamics-aware reward model. Repo: \texttt{https://github.com/apple/ml-reed}.
Large Language Models as Generalizable Policies for Embodied Tasks
Oct 26, 2023
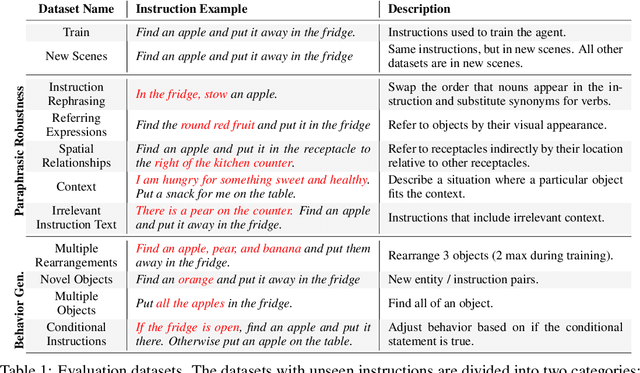
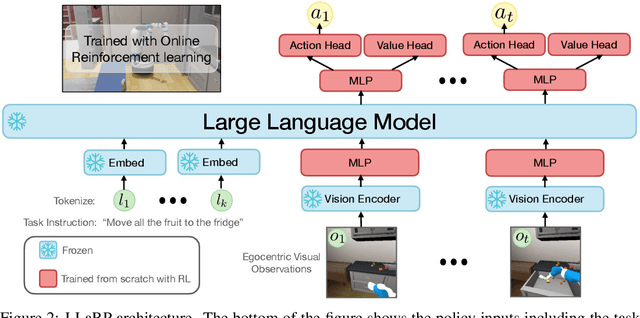
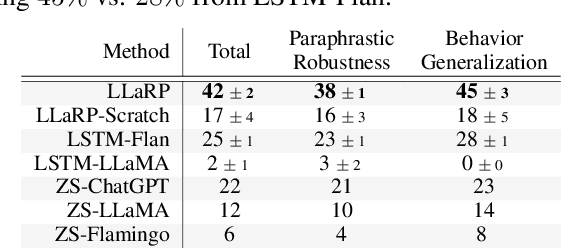
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.