 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePREDICT: Preference Reasoning by Evaluating Decomposed preferences Inferred from Candidate Trajectories
Oct 08, 2024



Accommodating human preferences is essential for creating AI agents that deliver personalized and effective interactions. Recent work has shown the potential for LLMs to infer preferences from user interactions, but they often produce broad and generic preferences, failing to capture the unique and individualized nature of human preferences. This paper introduces PREDICT, a method designed to enhance the precision and adaptability of inferring preferences. PREDICT incorporates three key elements: (1) iterative refinement of inferred preferences, (2) decomposition of preferences into constituent components, and (3) validation of preferences across multiple trajectories. We evaluate PREDICT on two distinct environments: a gridworld setting and a new text-domain environment (PLUME). PREDICT more accurately infers nuanced human preferences improving over existing baselines by 66.2\% (gridworld environment) and 41.0\% (PLUME).
BENDR: using transformers and a contrastive self-supervised learning task to learn from massive amounts of EEG data
Jan 28, 2021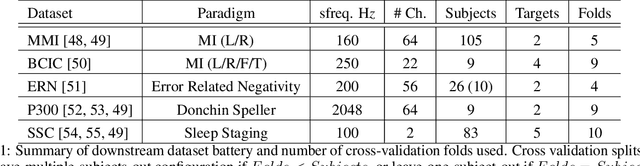
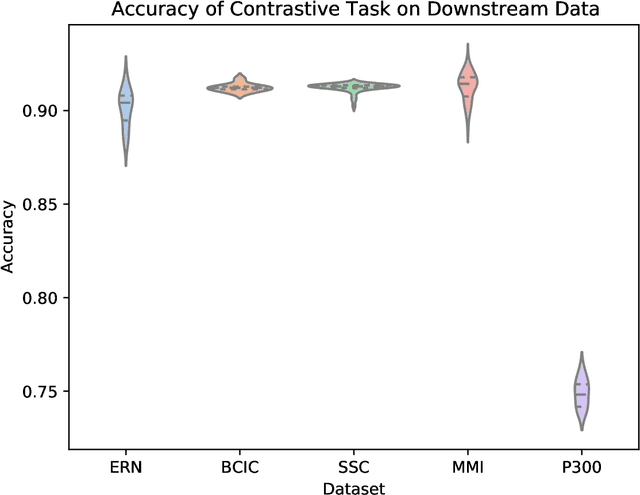
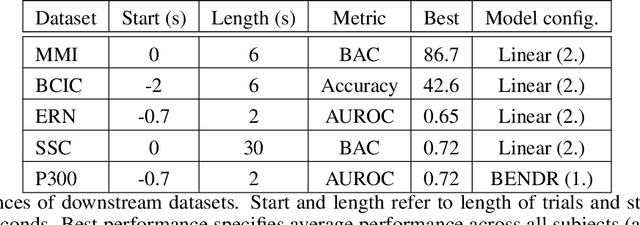
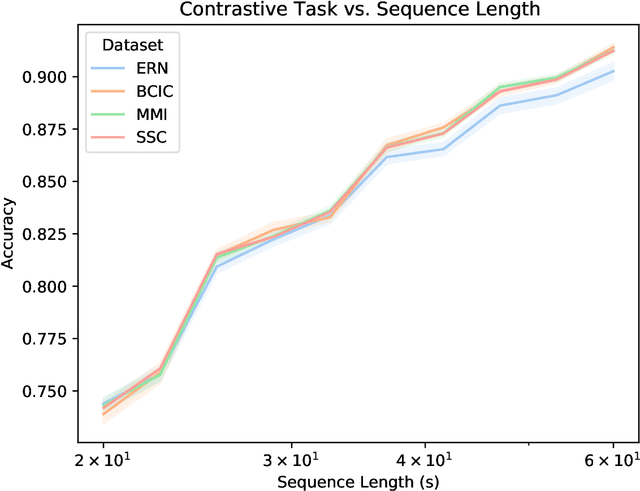
Deep neural networks (DNNs) used for brain-computer-interface (BCI) classification are commonly expected to learn general features when trained across a variety of contexts, such that these features could be fine-tuned to specific contexts. While some success is found in such an approach, we suggest that this interpretation is limited and an alternative would better leverage the newly (publicly) available massive EEG datasets. We consider how to adapt techniques and architectures used for language modelling (LM), that appear capable of ingesting awesome amounts of data, towards the development of encephalography modelling (EM) with DNNs in the same vein. We specifically adapt an approach effectively used for automatic speech recognition, which similarly (to LMs) uses a self-supervised training objective to learn compressed representations of raw data signals. After adaptation to EEG, we find that a single pre-trained model is capable of modelling completely novel raw EEG sequences recorded with differing hardware, and different subjects performing different tasks. Furthermore, both the internal representations of this model and the entire architecture can be fine-tuned to a variety of downstream BCI and EEG classification tasks, outperforming prior work in more task-specific (sleep stage classification) self-supervision.
On Losses for Modern Language Models
Oct 04, 2020
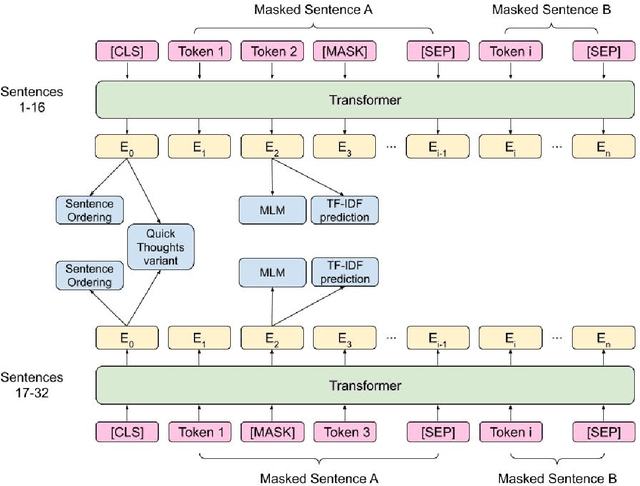


BERT set many state-of-the-art results over varied NLU benchmarks by pre-training over two tasks: masked language modelling (MLM) and next sentence prediction (NSP), the latter of which has been highly criticized. In this paper, we 1) clarify NSP's effect on BERT pre-training, 2) explore fourteen possible auxiliary pre-training tasks, of which seven are novel to modern language models, and 3) investigate different ways to include multiple tasks into pre-training. We show that NSP is detrimental to training due to its context splitting and shallow semantic signal. We also identify six auxiliary pre-training tasks -- sentence ordering, adjacent sentence prediction, TF prediction, TF-IDF prediction, a FastSent variant, and a Quick Thoughts variant -- that outperform a pure MLM baseline. Finally, we demonstrate that using multiple tasks in a multi-task pre-training framework provides better results than using any single auxiliary task. Using these methods, we outperform BERT Base on the GLUE benchmark using fewer than a quarter of the training tokens.