 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscriminating Form and Meaning in Multilingual Models with Minimal-Pair ABX Tasks
May 23, 2025We introduce a set of training-free ABX-style discrimination tasks to evaluate how multilingual language models represent language identity (form) and semantic content (meaning). Inspired from speech processing, these zero-shot tasks measure whether minimal differences in representation can be reliably detected. This offers a flexible and interpretable alternative to probing. Applied to XLM-R (Conneau et al, 2020) across pretraining checkpoints and layers, we find that language discrimination declines over training and becomes concentrated in lower layers, while meaning discrimination strengthens over time and stabilizes in deeper layers. We then explore probing tasks, showing some alignment between our metrics and linguistic learning performance. Our results position ABX tasks as a lightweight framework for analyzing the structure of multilingual representations.
Steering into New Embedding Spaces: Analyzing Cross-Lingual Alignment Induced by Model Interventions in Multilingual Language Models
Feb 21, 2025Aligned representations across languages is a desired property in multilingual large language models (mLLMs), as alignment can improve performance in cross-lingual tasks. Typically alignment requires fine-tuning a model, which is computationally expensive, and sizable language data, which often may not be available. A data-efficient alternative to fine-tuning is model interventions -- a method for manipulating model activations to steer generation into the desired direction. We analyze the effect of a popular intervention (finding experts) on the alignment of cross-lingual representations in mLLMs. We identify the neurons to manipulate for a given language and introspect the embedding space of mLLMs pre- and post-manipulation. We show that modifying the mLLM's activations changes its embedding space such that cross-lingual alignment is enhanced. Further, we show that the changes to the embedding space translate into improved downstream performance on retrieval tasks, with up to 2x improvements in top-1 accuracy on cross-lingual retrieval.
Analyze the Neurons, not the Embeddings: Understanding When and Where LLM Representations Align with Humans
Feb 20, 2025Modern large language models (LLMs) achieve impressive performance on some tasks, while exhibiting distinctly non-human-like behaviors on others. This raises the question of how well the LLM's learned representations align with human representations. In this work, we introduce a novel approach to the study of representation alignment: we adopt a method from research on activation steering to identify neurons responsible for specific concepts (e.g., 'cat') and then analyze the corresponding activation patterns. Our findings reveal that LLM representations closely align with human representations inferred from behavioral data. Notably, this alignment surpasses that of word embeddings, which have been center stage in prior work on human and model alignment. Additionally, our approach enables a more granular view of how LLMs represent concepts. Specifically, we show that LLMs organize concepts in a way that reflects hierarchical relationships interpretable to humans (e.g., 'animal'-'dog').
Analyzing the Effect of Linguistic Similarity on Cross-Lingual Transfer: Tasks and Experimental Setups Matter
Jan 24, 2025Cross-lingual transfer is a popular approach to increase the amount of training data for NLP tasks in a low-resource context. However, the best strategy to decide which cross-lingual data to include is unclear. Prior research often focuses on a small set of languages from a few language families and/or a single task. It is still an open question how these findings extend to a wider variety of languages and tasks. In this work, we analyze cross-lingual transfer for 266 languages from a wide variety of language families. Moreover, we include three popular NLP tasks: POS tagging, dependency parsing, and topic classification. Our findings indicate that the effect of linguistic similarity on transfer performance depends on a range of factors: the NLP task, the (mono- or multilingual) input representations, and the definition of linguistic similarity.
Naturalistic Head Motion Generation from Speech
Oct 26, 2022



Synthesizing natural head motion to accompany speech for an embodied conversational agent is necessary for providing a rich interactive experience. Most prior works assess the quality of generated head motion by comparing them against a single ground-truth using an objective metric. Yet there are many plausible head motion sequences to accompany a speech utterance. In this work, we study the variation in the perceptual quality of head motions sampled from a generative model. We show that, despite providing more diverse head motions, the generative model produces motions with varying degrees of perceptual quality. We finally show that objective metrics commonly used in previous research do not accurately reflect the perceptual quality of generated head motions. These results open an interesting avenue for future work to investigate better objective metrics that correlate with human perception of quality.
Towards a Perceptual Model for Estimating the Quality of Visual Speech
Mar 24, 2022

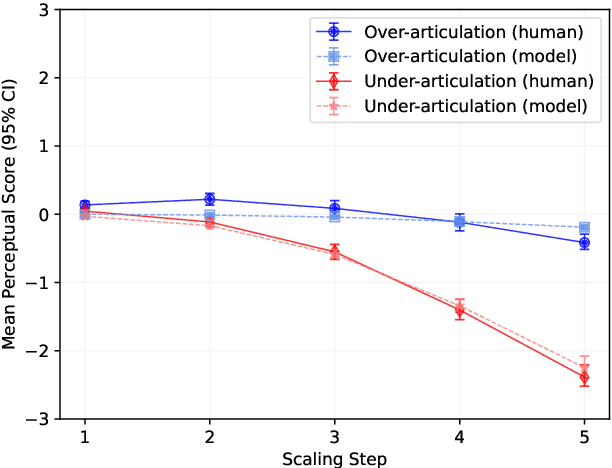
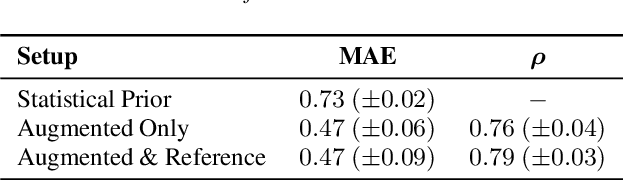
Generating realistic lip motions to simulate speech production is key for driving natural character animations from audio. Previous research has shown that traditional metrics used to optimize and assess models for generating lip motions from speech are not a good indicator of subjective opinion of animation quality. Yet, running repetitive subjective studies for assessing the quality of animations can be time-consuming and difficult to replicate. In this work, we seek to understand the relationship between perturbed lip motion and subjective opinion of lip motion quality. Specifically, we adjust the degree of articulation for lip motion sequences and run a user-study to examine how this adjustment impacts the perceived quality of lip motion. We then train a model using the scores collected from our user-study to automatically predict the subjective quality of an animated sequence. Our results show that (1) users score lip motions with slight over-articulation the highest in terms of perceptual quality; (2) under-articulation had a more detrimental effect on perceived quality of lip motion compared to the effect of over-articulation; and (3) we can automatically estimate the subjective perceptual score for a given lip motion sequences with low error rates.