 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoordinate In and Value Out: Training Flow Transformers in Ambient Space
Dec 05, 2024



Flow matching models have emerged as a powerful method for generative modeling on domains like images or videos, and even on unstructured data like 3D point clouds. These models are commonly trained in two stages: first, a data compressor (i.e., a variational auto-encoder) is trained, and in a subsequent training stage a flow matching generative model is trained in the low-dimensional latent space of the data compressor. This two stage paradigm adds complexity to the overall training recipe and sets obstacles for unifying models across data domains, as specific data compressors are used for different data modalities. To this end, we introduce Ambient Space Flow Transformers (ASFT), a domain-agnostic approach to learn flow matching transformers in ambient space, sidestepping the requirement of training compressors and simplifying the training process. We introduce a conditionally independent point-wise training objective that enables ASFT to make predictions continuously in coordinate space. Our empirical results demonstrate that using general purpose transformer blocks, ASFT effectively handles different data modalities such as images and 3D point clouds, achieving strong performance in both domains and outperforming comparable approaches. ASFT is a promising step towards domain-agnostic flow matching generative models that can be trivially adopted in different data domains.
FastSR-NeRF: Improving NeRF Efficiency on Consumer Devices with A Simple Super-Resolution Pipeline
Dec 20, 2023



Super-resolution (SR) techniques have recently been proposed to upscale the outputs of neural radiance fields (NeRF) and generate high-quality images with enhanced inference speeds. However, existing NeRF+SR methods increase training overhead by using extra input features, loss functions, and/or expensive training procedures such as knowledge distillation. In this paper, we aim to leverage SR for efficiency gains without costly training or architectural changes. Specifically, we build a simple NeRF+SR pipeline that directly combines existing modules, and we propose a lightweight augmentation technique, random patch sampling, for training. Compared to existing NeRF+SR methods, our pipeline mitigates the SR computing overhead and can be trained up to 23x faster, making it feasible to run on consumer devices such as the Apple MacBook. Experiments show our pipeline can upscale NeRF outputs by 2-4x while maintaining high quality, increasing inference speeds by up to 18x on an NVIDIA V100 GPU and 12.8x on an M1 Pro chip. We conclude that SR can be a simple but effective technique for improving the efficiency of NeRF models for consumer devices.
Probabilistic Speech-Driven 3D Facial Motion Synthesis: New Benchmarks, Methods, and Applications
Nov 30, 2023



We consider the task of animating 3D facial geometry from speech signal. Existing works are primarily deterministic, focusing on learning a one-to-one mapping from speech signal to 3D face meshes on small datasets with limited speakers. While these models can achieve high-quality lip articulation for speakers in the training set, they are unable to capture the full and diverse distribution of 3D facial motions that accompany speech in the real world. Importantly, the relationship between speech and facial motion is one-to-many, containing both inter-speaker and intra-speaker variations and necessitating a probabilistic approach. In this paper, we identify and address key challenges that have so far limited the development of probabilistic models: lack of datasets and metrics that are suitable for training and evaluating them, as well as the difficulty of designing a model that generates diverse results while remaining faithful to a strong conditioning signal as speech. We first propose large-scale benchmark datasets and metrics suitable for probabilistic modeling. Then, we demonstrate a probabilistic model that achieves both diversity and fidelity to speech, outperforming other methods across the proposed benchmarks. Finally, we showcase useful applications of probabilistic models trained on these large-scale datasets: we can generate diverse speech-driven 3D facial motion that matches unseen speaker styles extracted from reference clips; and our synthetic meshes can be used to improve the performance of downstream audio-visual models.
HUGS: Human Gaussian Splats
Nov 29, 2023Recent advances in neural rendering have improved both training and rendering times by orders of magnitude. While these methods demonstrate state-of-the-art quality and speed, they are designed for photogrammetry of static scenes and do not generalize well to freely moving humans in the environment. In this work, we introduce Human Gaussian Splats (HUGS) that represents an animatable human together with the scene using 3D Gaussian Splatting (3DGS). Our method takes only a monocular video with a small number of (50-100) frames, and it automatically learns to disentangle the static scene and a fully animatable human avatar within 30 minutes. We utilize the SMPL body model to initialize the human Gaussians. To capture details that are not modeled by SMPL (e.g. cloth, hairs), we allow the 3D Gaussians to deviate from the human body model. Utilizing 3D Gaussians for animated humans brings new challenges, including the artifacts created when articulating the Gaussians. We propose to jointly optimize the linear blend skinning weights to coordinate the movements of individual Gaussians during animation. Our approach enables novel-pose synthesis of human and novel view synthesis of both the human and the scene. We achieve state-of-the-art rendering quality with a rendering speed of 60 FPS while being ~100x faster to train over previous work. Our code will be announced here: https://github.com/apple/ml-hugs
Novel-View Acoustic Synthesis from 3D Reconstructed Rooms
Oct 23, 2023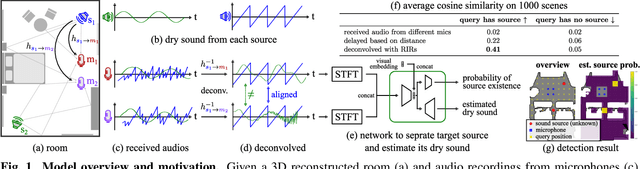
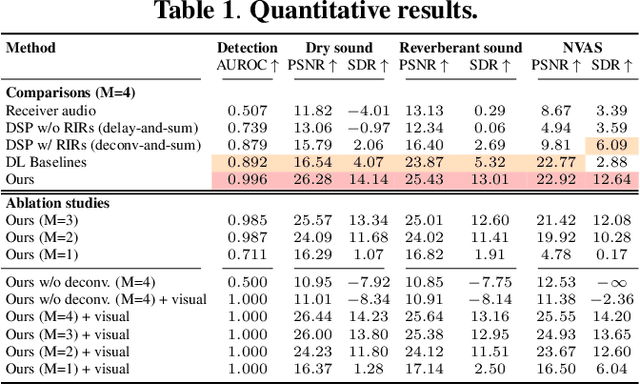
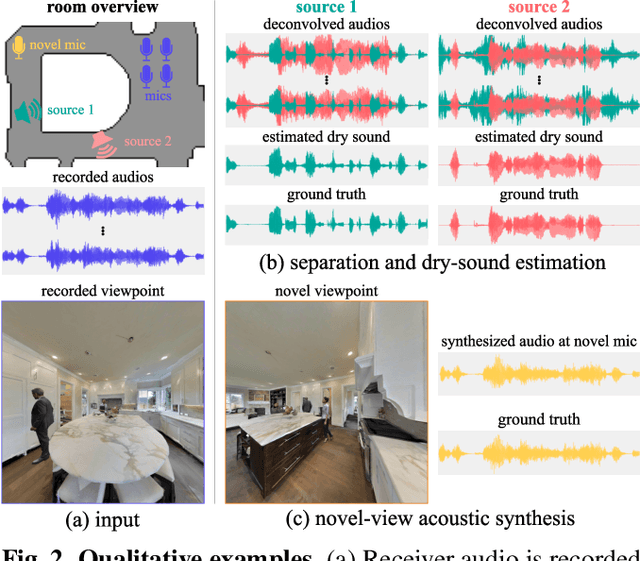
We investigate the benefit of combining blind audio recordings with 3D scene information for novel-view acoustic synthesis. Given audio recordings from 2-4 microphones and the 3D geometry and material of a scene containing multiple unknown sound sources, we estimate the sound anywhere in the scene. We identify the main challenges of novel-view acoustic synthesis as sound source localization, separation, and dereverberation. While naively training an end-to-end network fails to produce high-quality results, we show that incorporating room impulse responses (RIRs) derived from 3D reconstructed rooms enables the same network to jointly tackle these tasks. Our method outperforms existing methods designed for the individual tasks, demonstrating its effectiveness at utilizing 3D visual information. In a simulated study on the Matterport3D-NVAS dataset, our model achieves near-perfect accuracy on source localization, a PSNR of 26.44 dB and a SDR of 14.23 dB for source separation and dereverberation, resulting in a PSNR of 25.55 dB and a SDR of 14.20 dB on novel-view acoustic synthesis. Code, pretrained model, and video results are available on the project webpage (https://github.com/apple/ml-nvas3d).
Pointersect: Neural Rendering with Cloud-Ray Intersection
Apr 24, 2023

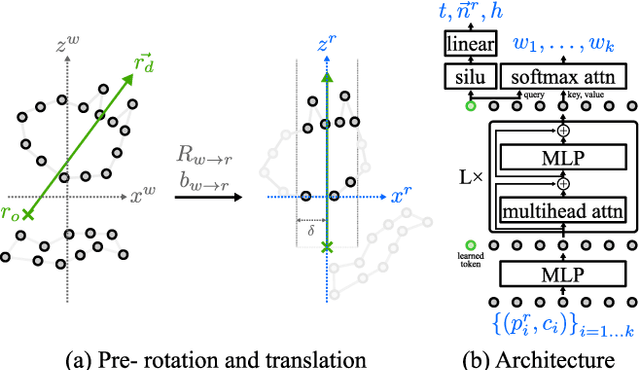

We propose a novel method that renders point clouds as if they are surfaces. The proposed method is differentiable and requires no scene-specific optimization. This unique capability enables, out-of-the-box, surface normal estimation, rendering room-scale point clouds, inverse rendering, and ray tracing with global illumination. Unlike existing work that focuses on converting point clouds to other representations--e.g., surfaces or implicit functions--our key idea is to directly infer the intersection of a light ray with the underlying surface represented by the given point cloud. Specifically, we train a set transformer that, given a small number of local neighbor points along a light ray, provides the intersection point, the surface normal, and the material blending weights, which are used to render the outcome of this light ray. Localizing the problem into small neighborhoods enables us to train a model with only 48 meshes and apply it to unseen point clouds. Our model achieves higher estimation accuracy than state-of-the-art surface reconstruction and point-cloud rendering methods on three test sets. When applied to room-scale point clouds, without any scene-specific optimization, the model achieves competitive quality with the state-of-the-art novel-view rendering methods. Moreover, we demonstrate ability to render and manipulate Lidar-scanned point clouds such as lighting control and object insertion.
FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction
Apr 04, 2023



Recent works on 3D reconstruction from posed images have demonstrated that direct inference of scene-level 3D geometry without iterative optimization is feasible using a deep neural network, showing remarkable promise and high efficiency. However, the reconstructed geometries, typically represented as a 3D truncated signed distance function (TSDF), are often coarse without fine geometric details. To address this problem, we propose three effective solutions for improving the fidelity of inference-based 3D reconstructions. We first present a resolution-agnostic TSDF supervision strategy to provide the network with a more accurate learning signal during training, avoiding the pitfalls of TSDF interpolation seen in previous work. We then introduce a depth guidance strategy using multi-view depth estimates to enhance the scene representation and recover more accurate surfaces. Finally, we develop a novel architecture for the final layers of the network, conditioning the output TSDF prediction on high-resolution image features in addition to coarse voxel features, enabling sharper reconstruction of fine details. Our method produces smooth and highly accurate reconstructions, showing significant improvements across multiple depth and 3D reconstruction metrics.
FaceLit: Neural 3D Relightable Faces
Mar 27, 2023We propose a generative framework, FaceLit, capable of generating a 3D face that can be rendered at various user-defined lighting conditions and views, learned purely from 2D images in-the-wild without any manual annotation. Unlike existing works that require careful capture setup or human labor, we rely on off-the-shelf pose and illumination estimators. With these estimates, we incorporate the Phong reflectance model in the neural volume rendering framework. Our model learns to generate shape and material properties of a face such that, when rendered according to the natural statistics of pose and illumination, produces photorealistic face images with multiview 3D and illumination consistency. Our method enables photorealistic generation of faces with explicit illumination and view controls on multiple datasets - FFHQ, MetFaces and CelebA-HQ. We show state-of-the-art photorealism among 3D aware GANs on FFHQ dataset achieving an FID score of 3.5.
FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization
Mar 24, 2023



The recent amalgamation of transformer and convolutional designs has led to steady improvements in accuracy and efficiency of the models. In this work, we introduce FastViT, a hybrid vision transformer architecture that obtains the state-of-the-art latency-accuracy trade-off. To this end, we introduce a novel token mixing operator, RepMixer, a building block of FastViT, that uses structural reparameterization to lower the memory access cost by removing skip-connections in the network. We further apply train-time overparametrization and large kernel convolutions to boost accuracy and empirically show that these choices have minimal effect on latency. We show that - our model is 3.5x faster than CMT, a recent state-of-the-art hybrid transformer architecture, 4.9x faster than EfficientNet, and 1.9x faster than ConvNeXt on a mobile device for the same accuracy on the ImageNet dataset. At similar latency, our model obtains 4.2% better Top-1 accuracy on ImageNet than MobileOne. Our model consistently outperforms competing architectures across several tasks -- image classification, detection, segmentation and 3D mesh regression with significant improvement in latency on both a mobile device and a desktop GPU. Furthermore, our model is highly robust to out-of-distribution samples and corruptions, improving over competing robust models.
Naturalistic Head Motion Generation from Speech
Oct 26, 2022



Synthesizing natural head motion to accompany speech for an embodied conversational agent is necessary for providing a rich interactive experience. Most prior works assess the quality of generated head motion by comparing them against a single ground-truth using an objective metric. Yet there are many plausible head motion sequences to accompany a speech utterance. In this work, we study the variation in the perceptual quality of head motions sampled from a generative model. We show that, despite providing more diverse head motions, the generative model produces motions with varying degrees of perceptual quality. We finally show that objective metrics commonly used in previous research do not accurately reflect the perceptual quality of generated head motions. These results open an interesting avenue for future work to investigate better objective metrics that correlate with human perception of quality.