 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStableDreamer: Taming Noisy Score Distillation Sampling for Text-to-3D
Dec 02, 2023



In the realm of text-to-3D generation, utilizing 2D diffusion models through score distillation sampling (SDS) frequently leads to issues such as blurred appearances and multi-faced geometry, primarily due to the intrinsically noisy nature of the SDS loss. Our analysis identifies the core of these challenges as the interaction among noise levels in the 2D diffusion process, the architecture of the diffusion network, and the 3D model representation. To overcome these limitations, we present StableDreamer, a methodology incorporating three advances. First, inspired by InstructNeRF2NeRF, we formalize the equivalence of the SDS generative prior and a simple supervised L2 reconstruction loss. This finding provides a novel tool to debug SDS, which we use to show the impact of time-annealing noise levels on reducing multi-faced geometries. Second, our analysis shows that while image-space diffusion contributes to geometric precision, latent-space diffusion is crucial for vivid color rendition. Based on this observation, StableDreamer introduces a two-stage training strategy that effectively combines these aspects, resulting in high-fidelity 3D models. Third, we adopt an anisotropic 3D Gaussians representation, replacing Neural Radiance Fields (NeRFs), to enhance the overall quality, reduce memory usage during training, and accelerate rendering speeds, and better capture semi-transparent objects. StableDreamer reduces multi-face geometries, generates fine details, and converges stably.
Is Generalized Dynamic Novel View Synthesis from Monocular Videos Possible Today?
Oct 12, 2023



Rendering scenes observed in a monocular video from novel viewpoints is a challenging problem. For static scenes the community has studied both scene-specific optimization techniques, which optimize on every test scene, and generalized techniques, which only run a deep net forward pass on a test scene. In contrast, for dynamic scenes, scene-specific optimization techniques exist, but, to our best knowledge, there is currently no generalized method for dynamic novel view synthesis from a given monocular video. To answer whether generalized dynamic novel view synthesis from monocular videos is possible today, we establish an analysis framework based on existing techniques and work toward the generalized approach. We find a pseudo-generalized process without scene-specific appearance optimization is possible, but geometrically and temporally consistent depth estimates are needed. Despite no scene-specific appearance optimization, the pseudo-generalized approach improves upon some scene-specific methods.
FineRecon: Depth-aware Feed-forward Network for Detailed 3D Reconstruction
Apr 04, 2023



Recent works on 3D reconstruction from posed images have demonstrated that direct inference of scene-level 3D geometry without iterative optimization is feasible using a deep neural network, showing remarkable promise and high efficiency. However, the reconstructed geometries, typically represented as a 3D truncated signed distance function (TSDF), are often coarse without fine geometric details. To address this problem, we propose three effective solutions for improving the fidelity of inference-based 3D reconstructions. We first present a resolution-agnostic TSDF supervision strategy to provide the network with a more accurate learning signal during training, avoiding the pitfalls of TSDF interpolation seen in previous work. We then introduce a depth guidance strategy using multi-view depth estimates to enhance the scene representation and recover more accurate surfaces. Finally, we develop a novel architecture for the final layers of the network, conditioning the output TSDF prediction on high-resolution image features in addition to coarse voxel features, enabling sharper reconstruction of fine details. Our method produces smooth and highly accurate reconstructions, showing significant improvements across multiple depth and 3D reconstruction metrics.
HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion
Mar 29, 2023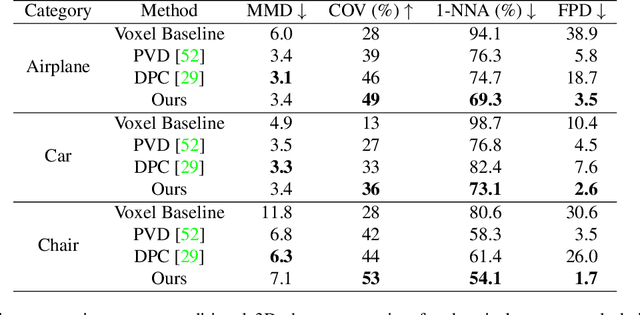

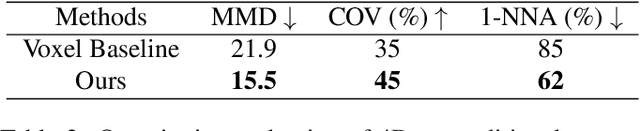
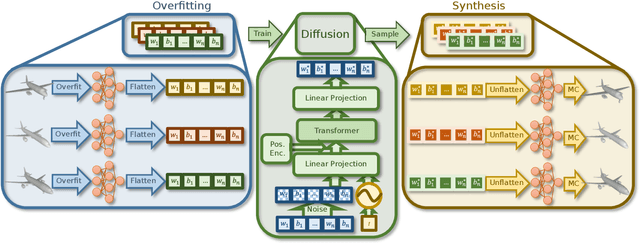
Implicit neural fields, typically encoded by a multilayer perceptron (MLP) that maps from coordinates (e.g., xyz) to signals (e.g., signed distances), have shown remarkable promise as a high-fidelity and compact representation. However, the lack of a regular and explicit grid structure also makes it challenging to apply generative modeling directly on implicit neural fields in order to synthesize new data. To this end, we propose HyperDiffusion, a novel approach for unconditional generative modeling of implicit neural fields. HyperDiffusion operates directly on MLP weights and generates new neural implicit fields encoded by synthesized MLP parameters. Specifically, a collection of MLPs is first optimized to faithfully represent individual data samples. Subsequently, a diffusion process is trained in this MLP weight space to model the underlying distribution of neural implicit fields. HyperDiffusion enables diffusion modeling over a implicit, compact, and yet high-fidelity representation of complex signals across 3D shapes and 4D mesh animations within one single unified framework.
Generative Multiplane Images: Making a 2D GAN 3D-Aware
Jul 21, 2022
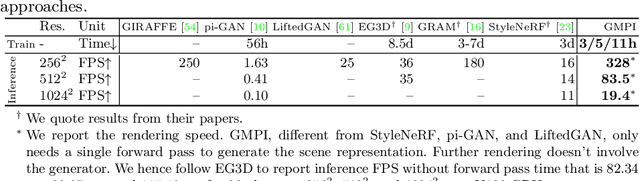
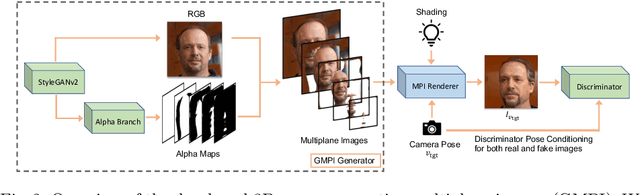
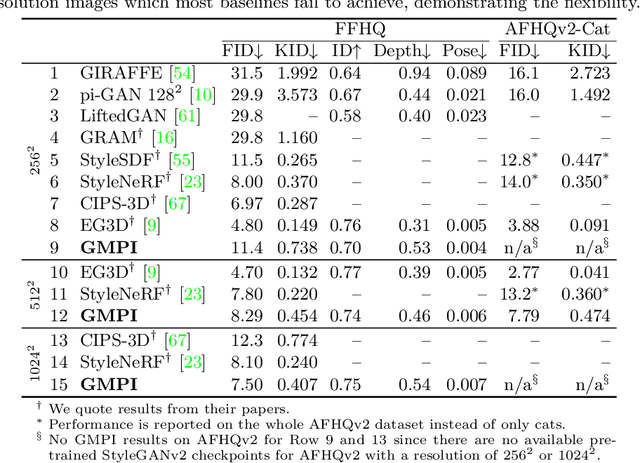
What is really needed to make an existing 2D GAN 3D-aware? To answer this question, we modify a classical GAN, i.e., StyleGANv2, as little as possible. We find that only two modifications are absolutely necessary: 1) a multiplane image style generator branch which produces a set of alpha maps conditioned on their depth; 2) a pose-conditioned discriminator. We refer to the generated output as a 'generative multiplane image' (GMPI) and emphasize that its renderings are not only high-quality but also guaranteed to be view-consistent, which makes GMPIs different from many prior works. Importantly, the number of alpha maps can be dynamically adjusted and can differ between training and inference, alleviating memory concerns and enabling fast training of GMPIs in less than half a day at a resolution of $1024^2$. Our findings are consistent across three challenging and common high-resolution datasets, including FFHQ, AFHQv2, and MetFaces.
Texturify: Generating Textures on 3D Shape Surfaces
Apr 05, 2022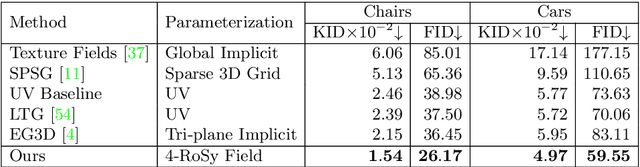
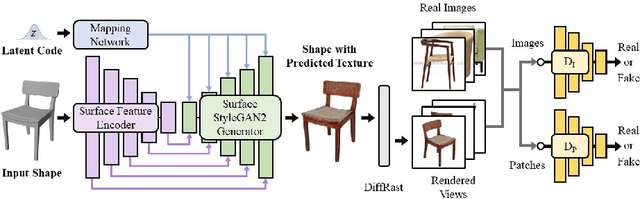
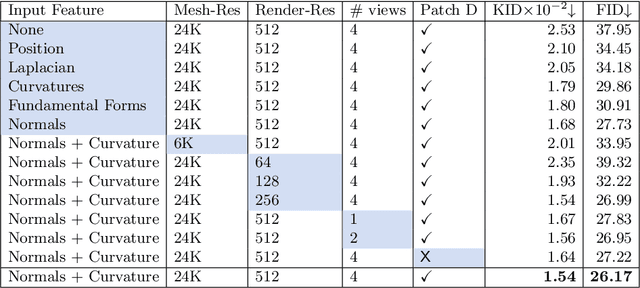
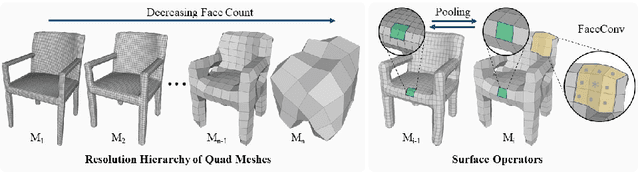
Texture cues on 3D objects are key to compelling visual representations, with the possibility to create high visual fidelity with inherent spatial consistency across different views. Since the availability of textured 3D shapes remains very limited, learning a 3D-supervised data-driven method that predicts a texture based on the 3D input is very challenging. We thus propose Texturify, a GAN-based method that leverages a 3D shape dataset of an object class and learns to reproduce the distribution of appearances observed in real images by generating high-quality textures. In particular, our method does not require any 3D color supervision or correspondence between shape geometry and images to learn the texturing of 3D objects. Texturify operates directly on the surface of the 3D objects by introducing face convolutional operators on a hierarchical 4-RoSy parametrization to generate plausible object-specific textures. Employing differentiable rendering and adversarial losses that critique individual views and consistency across views, we effectively learn the high-quality surface texturing distribution from real-world images. Experiments on car and chair shape collections show that our approach outperforms state of the art by an average of 22% in FID score.
RetrievalFuse: Neural 3D Scene Reconstruction with a Database
Mar 31, 2021
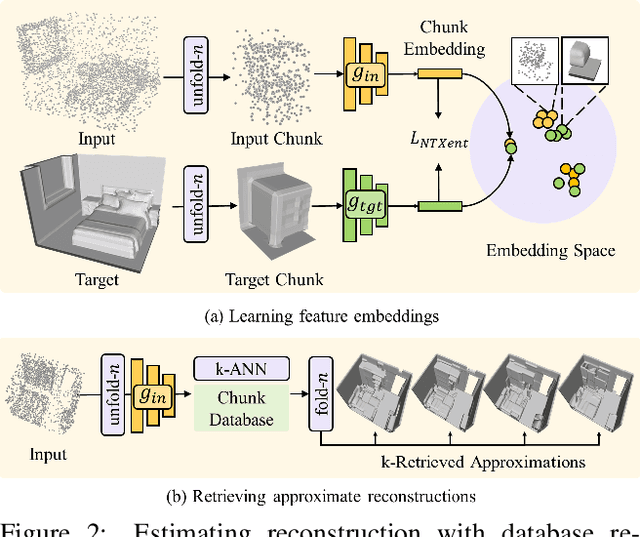
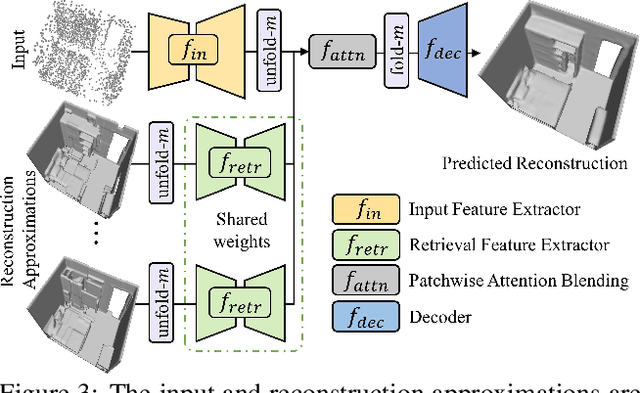
3D reconstruction of large scenes is a challenging problem due to the high-complexity nature of the solution space, in particular for generative neural networks. In contrast to traditional generative learned models which encode the full generative process into a neural network and can struggle with maintaining local details at the scene level, we introduce a new method that directly leverages scene geometry from the training database. First, we learn to synthesize an initial estimate for a 3D scene, constructed by retrieving a top-k set of volumetric chunks from the scene database. These candidates are then refined to a final scene generation with an attention-based refinement that can effectively select the most consistent set of geometry from the candidates and combine them together to create an output scene, facilitating transfer of coherent structures and local detail from train scene geometry. We demonstrate our neural scene reconstruction with a database for the tasks of 3D super resolution and surface reconstruction from sparse point clouds, showing that our approach enables generation of more coherent, accurate 3D scenes, improving on average by over 8% in IoU over state-of-the-art scene reconstruction.
FastDepth: Fast Monocular Depth Estimation on Embedded Systems
Mar 08, 2019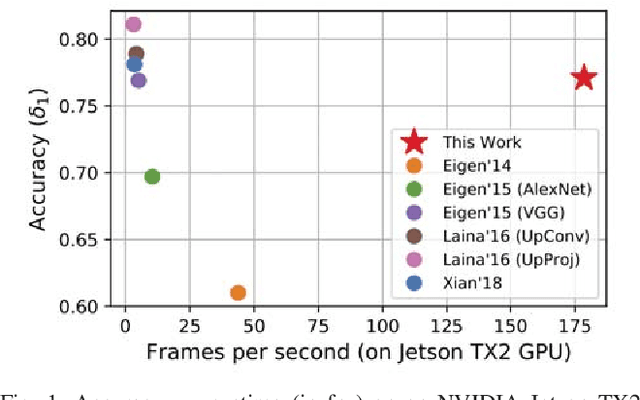

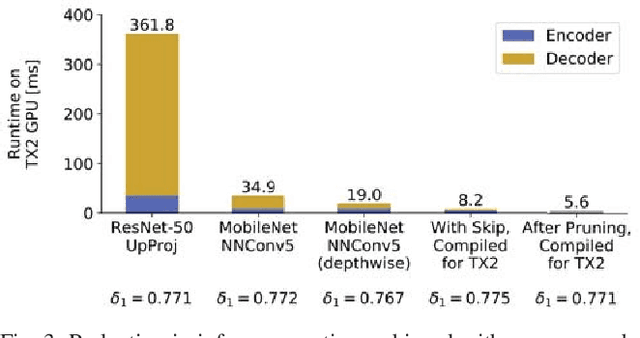

Depth sensing is a critical function for robotic tasks such as localization, mapping and obstacle detection. There has been a significant and growing interest in depth estimation from a single RGB image, due to the relatively low cost and size of monocular cameras. However, state-of-the-art single-view depth estimation algorithms are based on fairly complex deep neural networks that are too slow for real-time inference on an embedded platform, for instance, mounted on a micro aerial vehicle. In this paper, we address the problem of fast depth estimation on embedded systems. We propose an efficient and lightweight encoder-decoder network architecture and apply network pruning to further reduce computational complexity and latency. In particular, we focus on the design of a low-latency decoder. Our methodology demonstrates that it is possible to achieve similar accuracy as prior work on depth estimation, but at inference speeds that are an order of magnitude faster. Our proposed network, FastDepth, runs at 178 fps on an NVIDIA Jetson TX2 GPU and at 27 fps when using only the TX2 CPU, with active power consumption under 10 W. FastDepth achieves close to state-of-the-art accuracy on the NYU Depth v2 dataset. To the best of the authors' knowledge, this paper demonstrates real-time monocular depth estimation using a deep neural network with the lowest latency and highest throughput on an embedded platform that can be carried by a micro aerial vehicle.
Self-supervised Sparse-to-Dense: Self-supervised Depth Completion from LiDAR and Monocular Camera
Jul 03, 2018
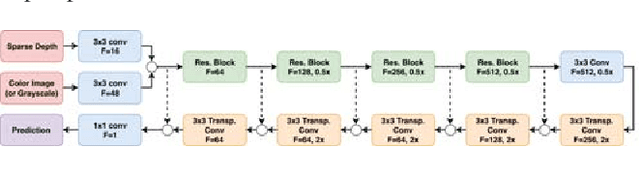
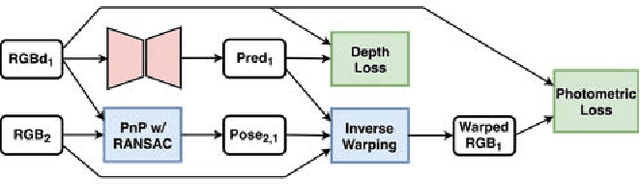
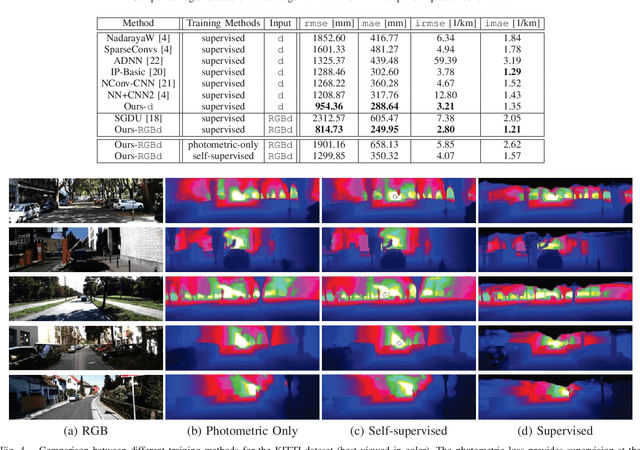
Depth completion, the technique of estimating a dense depth image from sparse depth measurements, has a variety of applications in robotics and autonomous driving. However, depth completion faces 3 main challenges: the irregularly spaced pattern in the sparse depth input, the difficulty in handling multiple sensor modalities (when color images are available), as well as the lack of dense, pixel-level ground truth depth labels. In this work, we address all these challenges. Specifically, we develop a deep regression model to learn a direct mapping from sparse depth (and color images) to dense depth. We also propose a self-supervised training framework that requires only sequences of color and sparse depth images, without the need for dense depth labels. Our experiments demonstrate that our network, when trained with semi-dense annotations, attains state-of-the- art accuracy and is the winning approach on the KITTI depth completion benchmark at the time of submission. Furthermore, the self-supervised framework outperforms a number of existing solutions trained with semi- dense annotations.
Sparse-to-Dense: Depth Prediction from Sparse Depth Samples and a Single Image
Feb 26, 2018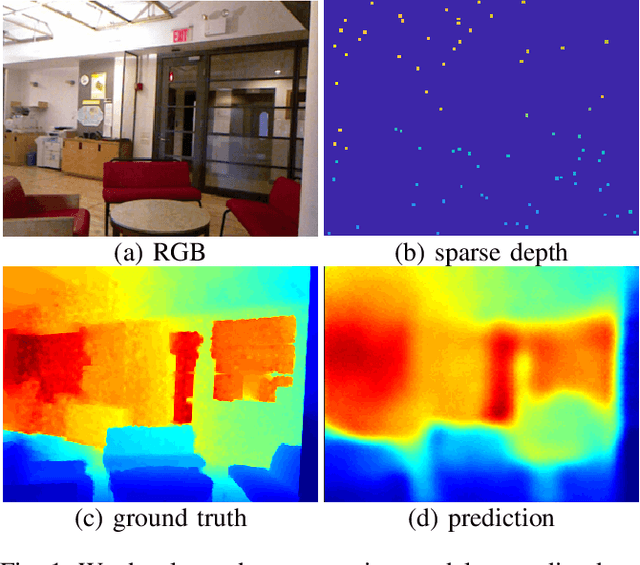
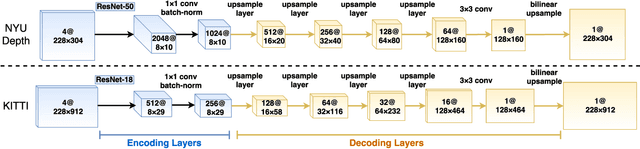
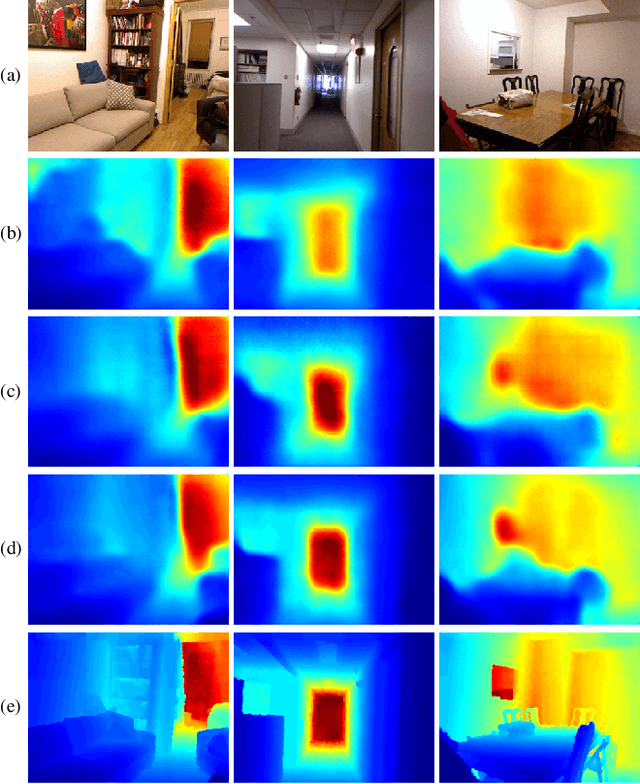
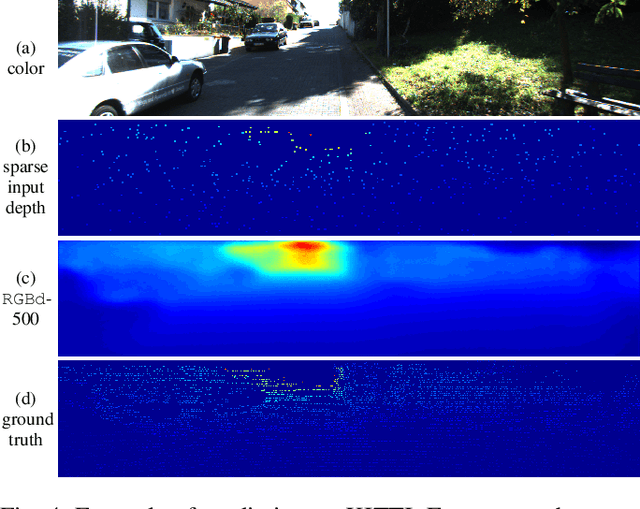
We consider the problem of dense depth prediction from a sparse set of depth measurements and a single RGB image. Since depth estimation from monocular images alone is inherently ambiguous and unreliable, to attain a higher level of robustness and accuracy, we introduce additional sparse depth samples, which are either acquired with a low-resolution depth sensor or computed via visual Simultaneous Localization and Mapping (SLAM) algorithms. We propose the use of a single deep regression network to learn directly from the RGB-D raw data, and explore the impact of number of depth samples on prediction accuracy. Our experiments show that, compared to using only RGB images, the addition of 100 spatially random depth samples reduces the prediction root-mean-square error by 50% on the NYU-Depth-v2 indoor dataset. It also boosts the percentage of reliable prediction from 59% to 92% on the KITTI dataset. We demonstrate two applications of the proposed algorithm: a plug-in module in SLAM to convert sparse maps to dense maps, and super-resolution for LiDARs. Software and video demonstration are publicly available.