 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPSCALE: Unconstrained Channel Pruning
Jul 17, 2023As neural networks grow in size and complexity, inference speeds decline. To combat this, one of the most effective compression techniques -- channel pruning -- removes channels from weights. However, for multi-branch segments of a model, channel removal can introduce inference-time memory copies. In turn, these copies increase inference latency -- so much so that the pruned model can be slower than the unpruned model. As a workaround, pruners conventionally constrain certain channels to be pruned together. This fully eliminates memory copies but, as we show, significantly impairs accuracy. We now have a dilemma: Remove constraints but increase latency, or add constraints and impair accuracy. In response, our insight is to reorder channels at export time, (1) reducing latency by reducing memory copies and (2) improving accuracy by removing constraints. Using this insight, we design a generic algorithm UPSCALE to prune models with any pruning pattern. By removing constraints from existing pruners, we improve ImageNet accuracy for post-training pruned models by 2.1 points on average -- benefiting DenseNet (+16.9), EfficientNetV2 (+7.9), and ResNet (+6.2). Furthermore, by reordering channels, UPSCALE improves inference speeds by up to 2x over a baseline export.
Generative Multiplane Images: Making a 2D GAN 3D-Aware
Jul 21, 2022
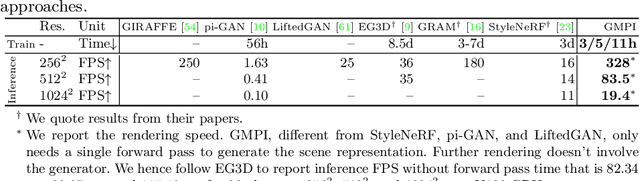
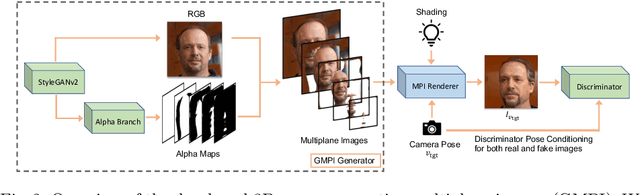
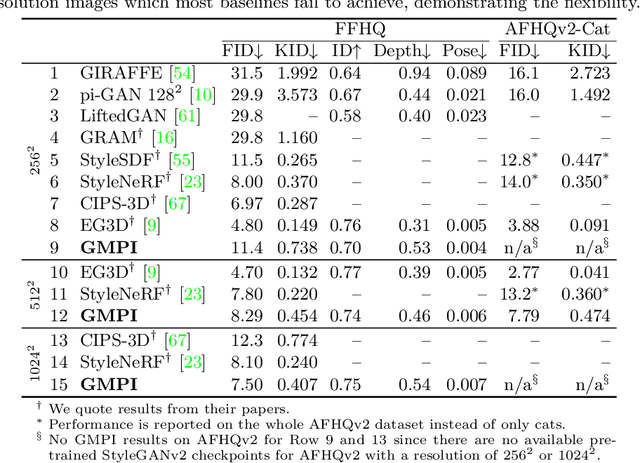
What is really needed to make an existing 2D GAN 3D-aware? To answer this question, we modify a classical GAN, i.e., StyleGANv2, as little as possible. We find that only two modifications are absolutely necessary: 1) a multiplane image style generator branch which produces a set of alpha maps conditioned on their depth; 2) a pose-conditioned discriminator. We refer to the generated output as a 'generative multiplane image' (GMPI) and emphasize that its renderings are not only high-quality but also guaranteed to be view-consistent, which makes GMPIs different from many prior works. Importantly, the number of alpha maps can be dynamically adjusted and can differ between training and inference, alleviating memory concerns and enabling fast training of GMPIs in less than half a day at a resolution of $1024^2$. Our findings are consistent across three challenging and common high-resolution datasets, including FFHQ, AFHQv2, and MetFaces.
Splicing Detection and Localization In Satellite Imagery Using Conditional GANs
May 03, 2022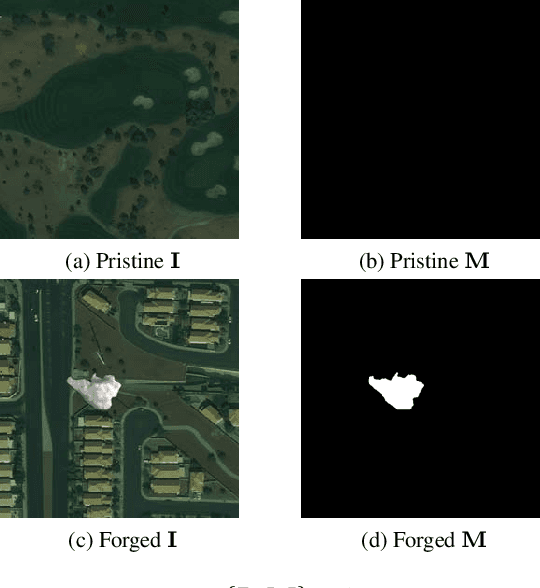


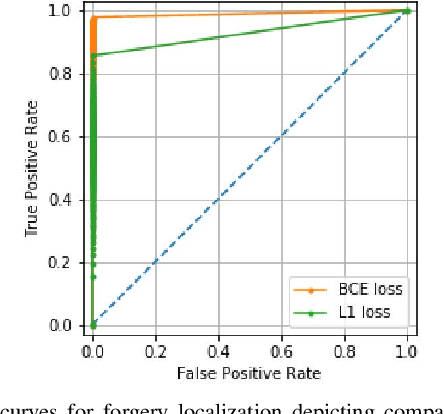
The widespread availability of image editing tools and improvements in image processing techniques allow image manipulation to be very easy. Oftentimes, easy-to-use yet sophisticated image manipulation tools yields distortions/changes imperceptible to the human observer. Distribution of forged images can have drastic ramifications, especially when coupled with the speed and vastness of the Internet. Therefore, verifying image integrity poses an immense and important challenge to the digital forensic community. Satellite images specifically can be modified in a number of ways, including the insertion of objects to hide existing scenes and structures. In this paper, we describe the use of a Conditional Generative Adversarial Network (cGAN) to identify the presence of such spliced forgeries within satellite images. Additionally, we identify their locations and shapes. Trained on pristine and falsified images, our method achieves high success on these detection and localization objectives.
* Accepted to the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR)
Deepfakes Detection with Automatic Face Weighting
May 04, 2020

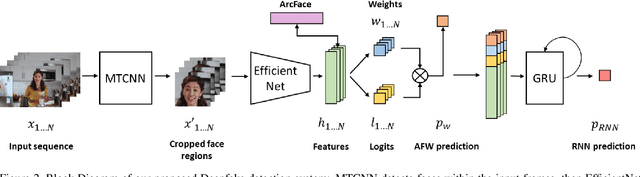

Altered and manipulated multimedia is increasingly present and widely distributed via social media platforms. Advanced video manipulation tools enable the generation of highly realistic-looking altered multimedia. While many methods have been presented to detect manipulations, most of them fail when evaluated with data outside of the datasets used in research environments. In order to address this problem, the Deepfake Detection Challenge (DFDC) provides a large dataset of videos containing realistic manipulations and an evaluation system that ensures that methods work quickly and accurately, even when faced with challenging data. In this paper, we introduce a method based on convolutional neural networks (CNNs) and recurrent neural networks (RNNs) that extracts visual and temporal features from faces present in videos to accurately detect manipulations. The method is evaluated with the DFDC dataset, providing competitive results compared to other techniques.
Learning eating environments through scene clustering
Nov 10, 2019
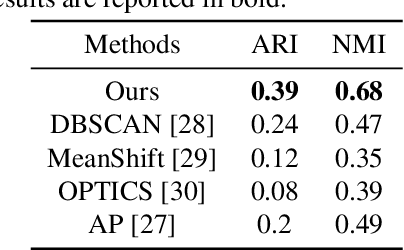

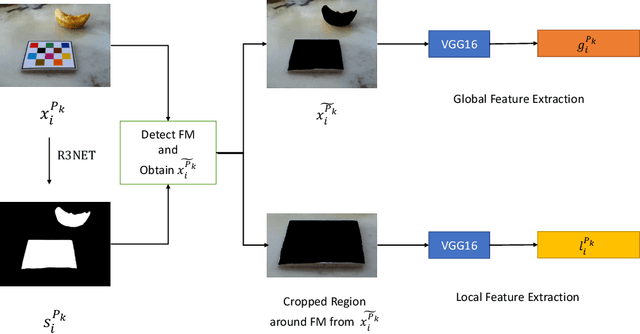
It is well known that dietary habits have a significant influence on health. While many studies have been conducted to understand this relationship, little is known about the relationship between eating environments and health. Yet researchers and health agencies around the world have recognized the eating environment as a promising context for improving diet and health. In this paper, we propose an image clustering method to automatically extract the eating environments from eating occasion images captured during a community dwelling dietary study. Specifically, we are interested in learning how many different environments an individual consumes food in. Our method clusters images by extracting features at both global and local scales using a deep neural network. The variation in the number of clusters and images captured by different individual makes this a very challenging problem. Experimental results show that our method performs significantly better compared to several existing clustering approaches.
A Utility-Preserving GAN for Face Obscuration
Jun 27, 2019
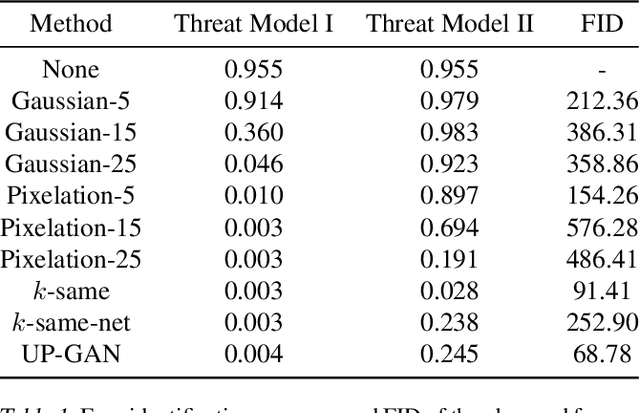
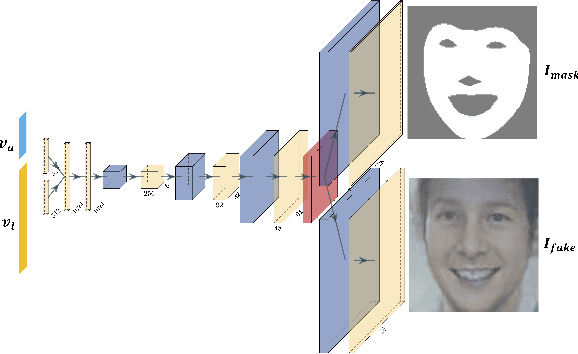

From TV news to Google StreetView, face obscuration has been used for privacy protection. Due to recent advances in the field of deep learning, obscuration methods such as Gaussian blurring and pixelation are not guaranteed to conceal identity. In this paper, we propose a utility-preserving generative model, UP-GAN, that is able to provide an effective face obscuration, while preserving facial utility. By utility-preserving we mean preserving facial features that do not reveal identity, such as age, gender, skin tone, pose, and expression. We show that the proposed method achieves the best performance in terms of obscuration and utility preservation.
We Need No Pixels: Video Manipulation Detection Using Stream Descriptors
Jun 20, 2019


Manipulating video content is easier than ever. Due to the misuse potential of manipulated content, multiple detection techniques that analyze the pixel data from the videos have been proposed. However, clever manipulators should also carefully forge the metadata and auxiliary header information, which is harder to do for videos than images. In this paper, we propose to identify forged videos by analyzing their multimedia stream descriptors with simple binary classifiers, completely avoiding the pixel space. Using well-known datasets, our results show that this scalable approach can achieve a high manipulation detection score if the manipulators have not done a careful data sanitization of the multimedia stream descriptors.
Robustness Analysis of Face Obscuration
May 13, 2019



Face obscuration is often needed by law enforcement or mass media outlets to provide privacy protection. Sharing sensitive content where the obscuration or redaction technique may have failed to completely remove all identifiable traces can lead to life-threatening consequences. Hence, it is critical to be able to systematically measure the face obscuration performance of a given technique. In this paper we propose to measure the effectiveness of three obscuration techniques: Gaussian blurring, median blurring, and pixelation. We do so by identifying the redacted faces under two scenarios: classifying an obscured face into a group of identities and comparing the similarity of an obscured face with a clear face. Threat modeling is also considered to provide a vulnerability analysis for each studied obscuration technique. Based on our evaluation, we show that pixelation-based face obscuration approaches are the most effective.
Weighted Hausdorff Distance: A Loss Function For Object Localization
Jun 20, 2018
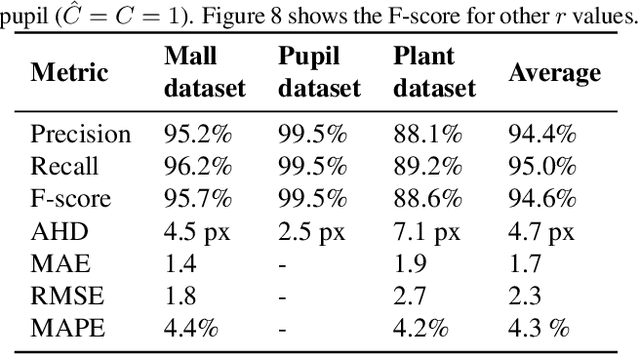

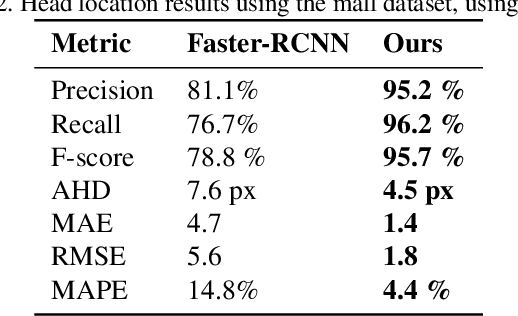
Recent advances in Convolutional Neural Networks (CNN) have achieved remarkable results in localizing objects in images. In these networks, the training procedure usually requires providing bounding boxes or the maximum number of expected objects. In this paper, we address the task of estimating object locations without annotated bounding boxes, which are typically hand-drawn and time consuming to label. We propose a loss function that can be used in any Fully Convolutional Network (FCN) to estimate object locations. This loss function is a modification of the Average Hausdorff Distance between two unordered sets of points. The proposed method does not require one to "guess" the maximum number of objects in the image, and has no notion of bounding boxes, region proposals, or sliding windows. We evaluate our method with three datasets designed to locate people's heads, pupil centers and plant centers. We report an average precision and recall of 94% for the three datasets, and an average location error of 6 pixels in 256x256 images.
A Counter-Forensic Method for CNN-Based Camera Model Identification
May 06, 2018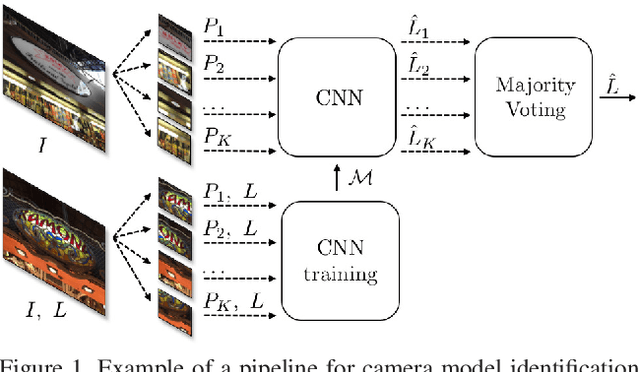
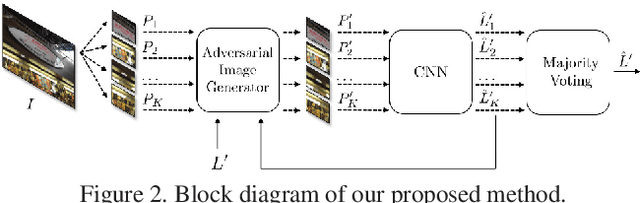

An increasing number of digital images are being shared and accessed through websites, media, and social applications. Many of these images have been modified and are not authentic. Recent advances in the use of deep convolutional neural networks (CNNs) have facilitated the task of analyzing the veracity and authenticity of largely distributed image datasets. We examine in this paper the problem of identifying the camera model or type that was used to take an image and that can be spoofed. Due to the linear nature of CNNs and the high-dimensionality of images, neural networks are vulnerable to attacks with adversarial examples. These examples are imperceptibly different from correctly classified images but are misclassified with high confidence by CNNs. In this paper, we describe a counter-forensic method capable of subtly altering images to change their estimated camera model when they are analyzed by any CNN-based camera model detector. Our method can use both the Fast Gradient Sign Method (FGSM) or the Jacobian-based Saliency Map Attack (JSMA) to craft these adversarial images and does not require direct access to the CNN. Our results show that even advanced deep learning architectures trained to analyze images and obtain camera model information are still vulnerable to our proposed method.