 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPSCALE: Unconstrained Channel Pruning
Jul 17, 2023As neural networks grow in size and complexity, inference speeds decline. To combat this, one of the most effective compression techniques -- channel pruning -- removes channels from weights. However, for multi-branch segments of a model, channel removal can introduce inference-time memory copies. In turn, these copies increase inference latency -- so much so that the pruned model can be slower than the unpruned model. As a workaround, pruners conventionally constrain certain channels to be pruned together. This fully eliminates memory copies but, as we show, significantly impairs accuracy. We now have a dilemma: Remove constraints but increase latency, or add constraints and impair accuracy. In response, our insight is to reorder channels at export time, (1) reducing latency by reducing memory copies and (2) improving accuracy by removing constraints. Using this insight, we design a generic algorithm UPSCALE to prune models with any pruning pattern. By removing constraints from existing pruners, we improve ImageNet accuracy for post-training pruned models by 2.1 points on average -- benefiting DenseNet (+16.9), EfficientNetV2 (+7.9), and ResNet (+6.2). Furthermore, by reordering channels, UPSCALE improves inference speeds by up to 2x over a baseline export.
Improving Building Segmentation for Off-Nadir Satellite Imagery
Sep 08, 2021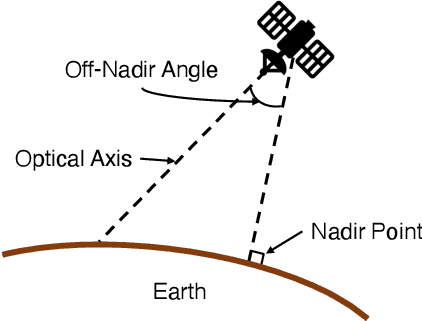
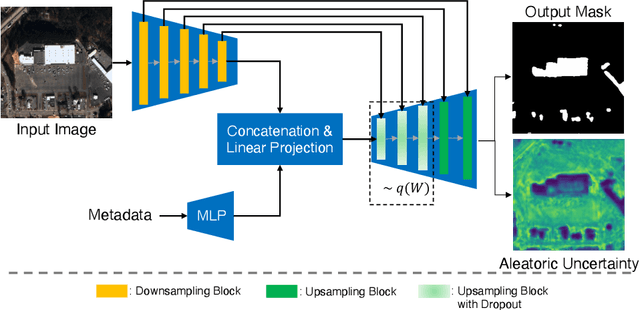
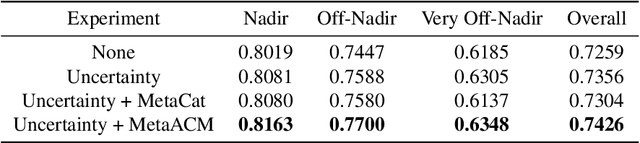
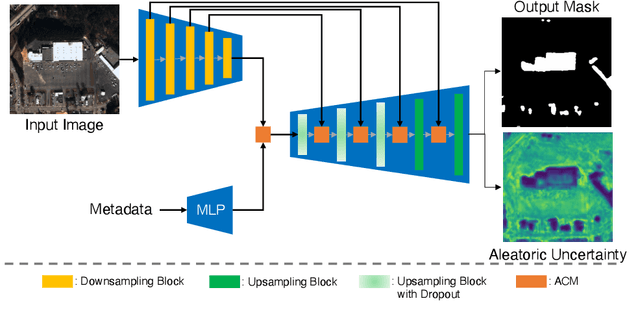
Automatic building segmentation is an important task for satellite imagery analysis and scene understanding. Most existing segmentation methods focus on the case where the images are taken from directly overhead (i.e., low off-nadir/viewing angle). These methods often fail to provide accurate results on satellite images with larger off-nadir angles due to the higher noise level and lower spatial resolution. In this paper, we propose a method that is able to provide accurate building segmentation for satellite imagery captured from a large range of off-nadir angles. Based on Bayesian deep learning, we explicitly design our method to learn the data noise via aleatoric and epistemic uncertainty modeling. Satellite image metadata (e.g., off-nadir angle and ground sample distance) is also used in our model to further improve the result. We show that with uncertainty modeling and metadata injection, our method achieves better performance than the baseline method, especially for noisy images taken from large off-nadir angles.
Manipulation Detection in Satellite Images Using Vision Transformer
May 13, 2021
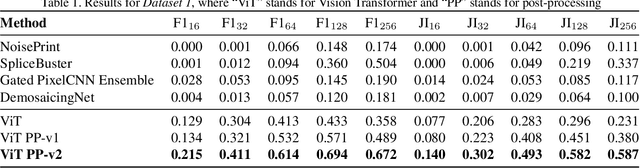
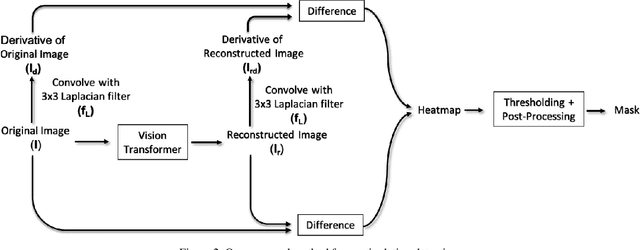

A growing number of commercial satellite companies provide easily accessible satellite imagery. Overhead imagery is used by numerous industries including agriculture, forestry, natural disaster analysis, and meteorology. Satellite images, just as any other images, can be tampered with image manipulation tools. Manipulation detection methods created for images captured by "consumer cameras" tend to fail when used on satellite images due to the differences in image sensors, image acquisition, and processing. In this paper we propose an unsupervised technique that uses a Vision Transformer to detect spliced areas within satellite images. We introduce a new dataset which includes manipulated satellite images that contain spliced objects. We show that our proposed approach performs better than existing unsupervised splicing detection techniques.
FaR-GAN for One-Shot Face Reenactment
May 13, 2020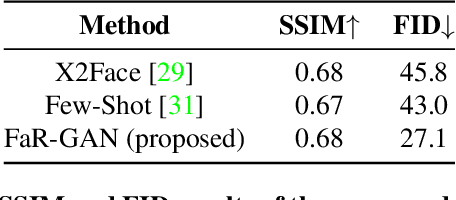
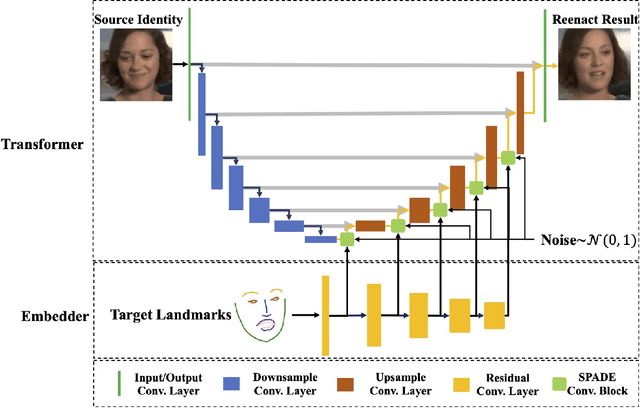


Animating a static face image with target facial expressions and movements is important in the area of image editing and movie production. This face reenactment process is challenging due to the complex geometry and movement of human faces. Previous work usually requires a large set of images from the same person to model the appearance. In this paper, we present a one-shot face reenactment model, FaR-GAN, that takes only one face image of any given source identity and a target expression as input, and then produces a face image of the same source identity but with the target expression. The proposed method makes no assumptions about the source identity, facial expression, head pose, or even image background. We evaluate our method on the VoxCeleb1 dataset and show that our method is able to generate a higher quality face image than the compared methods.
Deepfakes Detection with Automatic Face Weighting
May 04, 2020

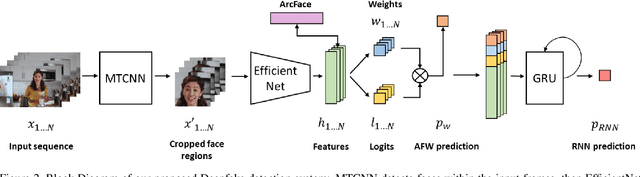

Altered and manipulated multimedia is increasingly present and widely distributed via social media platforms. Advanced video manipulation tools enable the generation of highly realistic-looking altered multimedia. While many methods have been presented to detect manipulations, most of them fail when evaluated with data outside of the datasets used in research environments. In order to address this problem, the Deepfake Detection Challenge (DFDC) provides a large dataset of videos containing realistic manipulations and an evaluation system that ensures that methods work quickly and accurately, even when faced with challenging data. In this paper, we introduce a method based on convolutional neural networks (CNNs) and recurrent neural networks (RNNs) that extracts visual and temporal features from faces present in videos to accurately detect manipulations. The method is evaluated with the DFDC dataset, providing competitive results compared to other techniques.
An Attention-Based System for Damage Assessment Using Satellite Imagery
Apr 14, 2020


When disaster strikes, accurate situational information and a fast, effective response are critical to save lives. Widely available, high resolution satellite images enable emergency responders to estimate locations, causes, and severity of damage. Quickly and accurately analyzing the extensive amount of satellite imagery available, though, requires an automatic approach. In this paper, we present Siam-U-Net-Attn model - a multi-class deep learning model with an attention mechanism - to assess damage levels of buildings given a pair of satellite images depicting a scene before and after a disaster. We evaluate the proposed method on xView2, a large-scale building damage assessment dataset, and demonstrate that the proposed approach achieves accurate damage scale classification and building segmentation results simultaneously.
A Utility-Preserving GAN for Face Obscuration
Jun 27, 2019
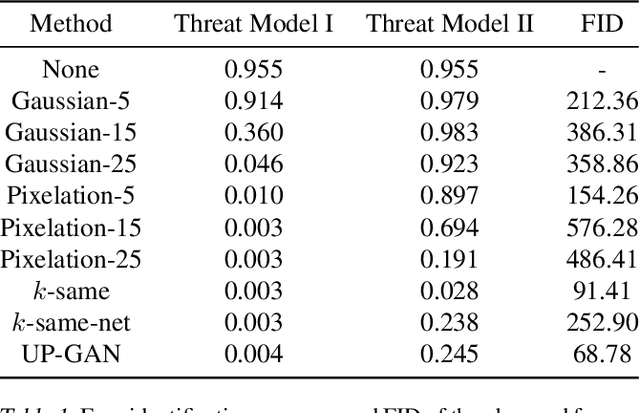
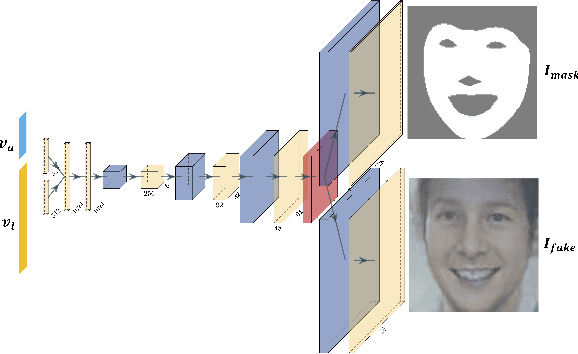

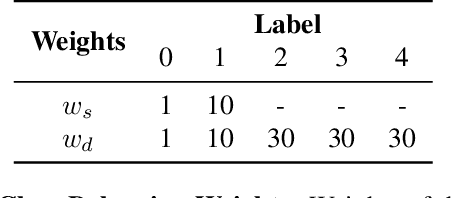
From TV news to Google StreetView, face obscuration has been used for privacy protection. Due to recent advances in the field of deep learning, obscuration methods such as Gaussian blurring and pixelation are not guaranteed to conceal identity. In this paper, we propose a utility-preserving generative model, UP-GAN, that is able to provide an effective face obscuration, while preserving facial utility. By utility-preserving we mean preserving facial features that do not reveal identity, such as age, gender, skin tone, pose, and expression. We show that the proposed method achieves the best performance in terms of obscuration and utility preservation.
Robustness Analysis of Face Obscuration
May 13, 2019



Face obscuration is often needed by law enforcement or mass media outlets to provide privacy protection. Sharing sensitive content where the obscuration or redaction technique may have failed to completely remove all identifiable traces can lead to life-threatening consequences. Hence, it is critical to be able to systematically measure the face obscuration performance of a given technique. In this paper we propose to measure the effectiveness of three obscuration techniques: Gaussian blurring, median blurring, and pixelation. We do so by identifying the redacted faces under two scenarios: classifying an obscured face into a group of identities and comparing the similarity of an obscured face with a clear face. Threat modeling is also considered to provide a vulnerability analysis for each studied obscuration technique. Based on our evaluation, we show that pixelation-based face obscuration approaches are the most effective.