 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommVQ: Commutative Vector Quantization for KV Cache Compression
Jun 23, 2025Large Language Models (LLMs) are increasingly used in applications requiring long context lengths, but the key-value (KV) cache often becomes a memory bottleneck on GPUs as context grows. To address this, we propose Commutative Vector Quantization (CommVQ) to significantly reduce memory usage for long-context LLM inference. We first introduce additive quantization with a lightweight encoder and codebook to compress the KV cache, which can be decoded via simple matrix multiplication. To further reduce computational costs during decoding, we design the codebook to be commutative with Rotary Position Embedding (RoPE) and train it using an Expectation-Maximization (EM) algorithm. This enables efficient integration of decoding into the self-attention mechanism. Our approach achieves high accuracy with additive quantization and low overhead via the RoPE-commutative codebook. Experiments on long-context benchmarks and GSM8K show that our method reduces FP16 KV cache size by 87.5% with 2-bit quantization, while outperforming state-of-the-art KV cache quantization methods. Notably, it enables 1-bit KV cache quantization with minimal accuracy loss, allowing a LLaMA-3.1 8B model to run with a 128K context length on a single RTX 4090 GPU. The source code is available at: https://github.com/UMass-Embodied-AGI/CommVQ.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
Talaria: Interactively Optimizing Machine Learning Models for Efficient Inference
Apr 03, 2024
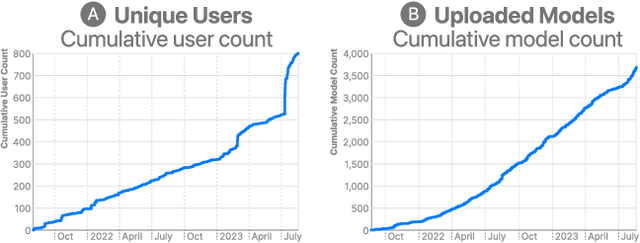
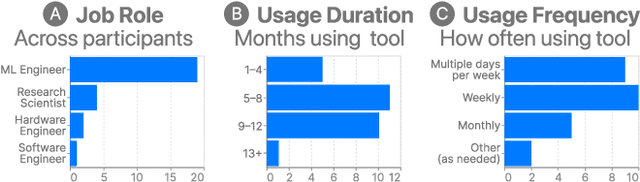
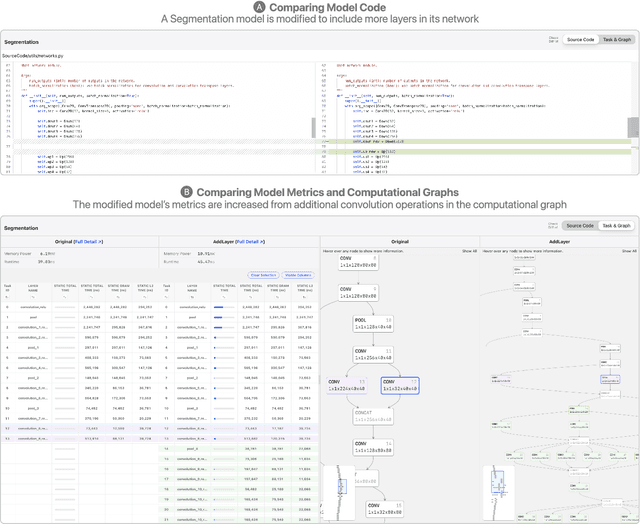
On-device machine learning (ML) moves computation from the cloud to personal devices, protecting user privacy and enabling intelligent user experiences. However, fitting models on devices with limited resources presents a major technical challenge: practitioners need to optimize models and balance hardware metrics such as model size, latency, and power. To help practitioners create efficient ML models, we designed and developed Talaria: a model visualization and optimization system. Talaria enables practitioners to compile models to hardware, interactively visualize model statistics, and simulate optimizations to test the impact on inference metrics. Since its internal deployment two years ago, we have evaluated Talaria using three methodologies: (1) a log analysis highlighting its growth of 800+ practitioners submitting 3,600+ models; (2) a usability survey with 26 users assessing the utility of 20 Talaria features; and (3) a qualitative interview with the 7 most active users about their experience using Talaria.
UPSCALE: Unconstrained Channel Pruning
Jul 17, 2023As neural networks grow in size and complexity, inference speeds decline. To combat this, one of the most effective compression techniques -- channel pruning -- removes channels from weights. However, for multi-branch segments of a model, channel removal can introduce inference-time memory copies. In turn, these copies increase inference latency -- so much so that the pruned model can be slower than the unpruned model. As a workaround, pruners conventionally constrain certain channels to be pruned together. This fully eliminates memory copies but, as we show, significantly impairs accuracy. We now have a dilemma: Remove constraints but increase latency, or add constraints and impair accuracy. In response, our insight is to reorder channels at export time, (1) reducing latency by reducing memory copies and (2) improving accuracy by removing constraints. Using this insight, we design a generic algorithm UPSCALE to prune models with any pruning pattern. By removing constraints from existing pruners, we improve ImageNet accuracy for post-training pruned models by 2.1 points on average -- benefiting DenseNet (+16.9), EfficientNetV2 (+7.9), and ResNet (+6.2). Furthermore, by reordering channels, UPSCALE improves inference speeds by up to 2x over a baseline export.
AutoFocusFormer: Image Segmentation off the Grid
Apr 24, 2023Real world images often have highly imbalanced content density. Some areas are very uniform, e.g., large patches of blue sky, while other areas are scattered with many small objects. Yet, the commonly used successive grid downsampling strategy in convolutional deep networks treats all areas equally. Hence, small objects are represented in very few spatial locations, leading to worse results in tasks such as segmentation. Intuitively, retaining more pixels representing small objects during downsampling helps to preserve important information. To achieve this, we propose AutoFocusFormer (AFF), a local-attention transformer image recognition backbone, which performs adaptive downsampling by learning to retain the most important pixels for the task. Since adaptive downsampling generates a set of pixels irregularly distributed on the image plane, we abandon the classic grid structure. Instead, we develop a novel point-based local attention block, facilitated by a balanced clustering module and a learnable neighborhood merging module, which yields representations for our point-based versions of state-of-the-art segmentation heads. Experiments show that our AutoFocusFormer (AFF) improves significantly over baseline models of similar sizes.
Generative Multiplane Images: Making a 2D GAN 3D-Aware
Jul 21, 2022
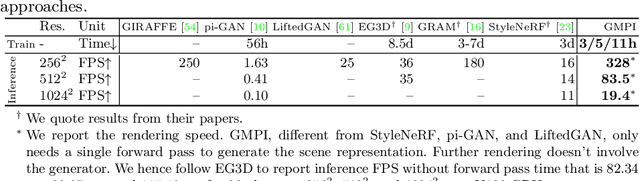
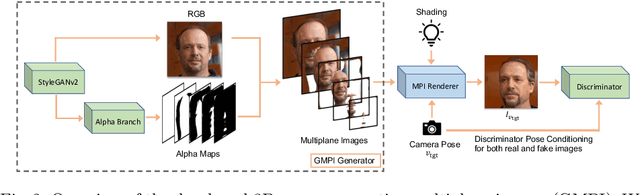
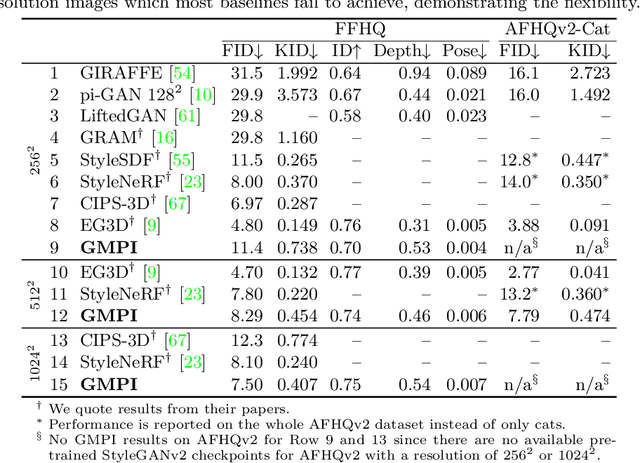
What is really needed to make an existing 2D GAN 3D-aware? To answer this question, we modify a classical GAN, i.e., StyleGANv2, as little as possible. We find that only two modifications are absolutely necessary: 1) a multiplane image style generator branch which produces a set of alpha maps conditioned on their depth; 2) a pose-conditioned discriminator. We refer to the generated output as a 'generative multiplane image' (GMPI) and emphasize that its renderings are not only high-quality but also guaranteed to be view-consistent, which makes GMPIs different from many prior works. Importantly, the number of alpha maps can be dynamically adjusted and can differ between training and inference, alleviating memory concerns and enabling fast training of GMPIs in less than half a day at a resolution of $1024^2$. Our findings are consistent across three challenging and common high-resolution datasets, including FFHQ, AFHQv2, and MetFaces.
FvOR: Robust Joint Shape and Pose Optimization for Few-view Object Reconstruction
May 16, 2022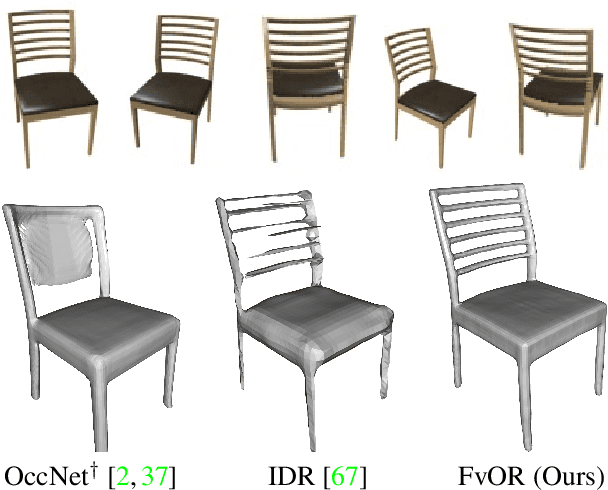

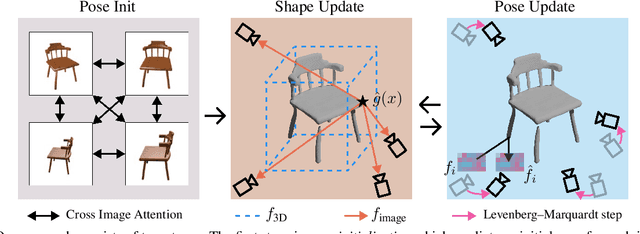

Reconstructing an accurate 3D object model from a few image observations remains a challenging problem in computer vision. State-of-the-art approaches typically assume accurate camera poses as input, which could be difficult to obtain in realistic settings. In this paper, we present FvOR, a learning-based object reconstruction method that predicts accurate 3D models given a few images with noisy input poses. The core of our approach is a fast and robust multi-view reconstruction algorithm to jointly refine 3D geometry and camera pose estimation using learnable neural network modules. We provide a thorough benchmark of state-of-the-art approaches for this problem on ShapeNet. Our approach achieves best-in-class results. It is also two orders of magnitude faster than the recent optimization-based approach IDR. Our code is released at \url{https://github.com/zhenpeiyang/FvOR/}
VideoPose: Estimating 6D object pose from videos
Nov 20, 2021
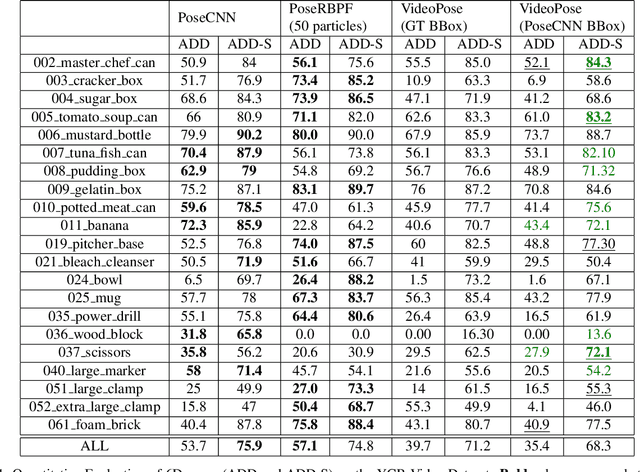
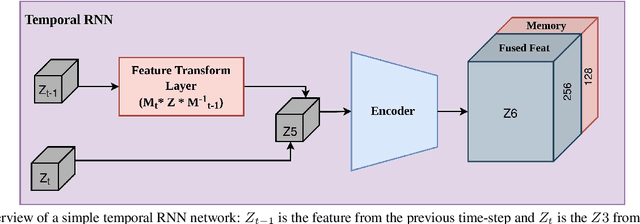
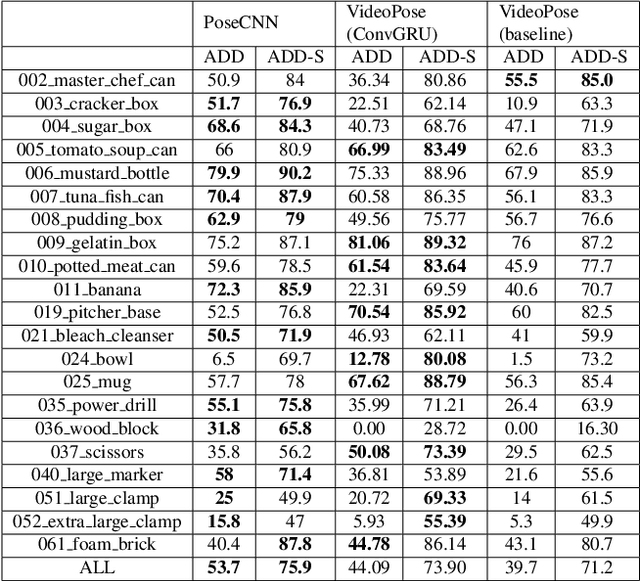
We introduce a simple yet effective algorithm that uses convolutional neural networks to directly estimate object poses from videos. Our approach leverages the temporal information from a video sequence, and is computationally efficient and robust to support robotic and AR domains. Our proposed network takes a pre-trained 2D object detector as input, and aggregates visual features through a recurrent neural network to make predictions at each frame. Experimental evaluation on the YCB-Video dataset show that our approach is on par with the state-of-the-art algorithms. Further, with a speed of 30 fps, it is also more efficient than the state-of-the-art, and therefore applicable to a variety of applications that require real-time object pose estimation.
MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions
Apr 27, 2021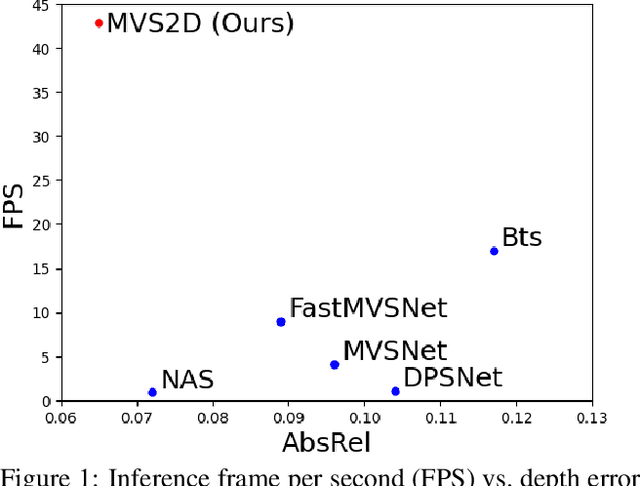

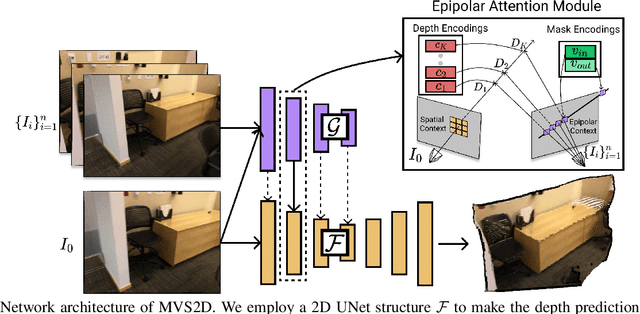

Deep learning has made significant impacts on multi-view stereo systems. State-of-the-art approaches typically involve building a cost volume, followed by multiple 3D convolution operations to recover the input image's pixel-wise depth. While such end-to-end learning of plane-sweeping stereo advances public benchmarks' accuracy, they are typically very slow to compute. We present MVS2D, a highly efficient multi-view stereo algorithm that seamlessly integrates multi-view constraints into single-view networks via an attention mechanism. Since MVS2D only builds on 2D convolutions, it is at least 4x faster than all the notable counterparts. Moreover, our algorithm produces precise depth estimations, achieving state-of-the-art results on challenging benchmarks ScanNet, SUN3D, and RGBD. Even under inexact camera poses, our algorithm still out-performs all other algorithms. Supplementary materials and code will be available at the project page: https://zhenpeiyang.github.io/MVS2D
Semantic MapNet: Building Allocentric SemanticMaps and Representations from Egocentric Views
Oct 02, 2020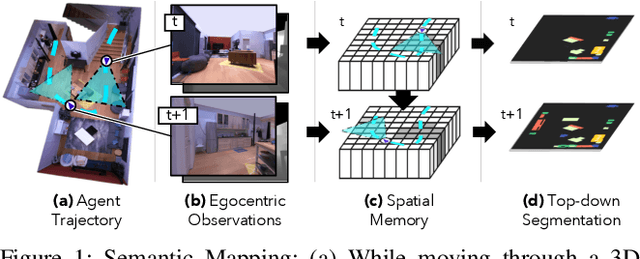

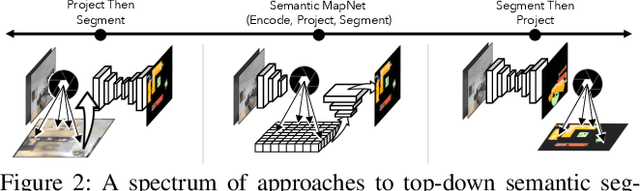

We study the task of semantic mapping - specifically, an embodied agent (a robot or an egocentric AI assistant) is given a tour of a new environment and asked to build an allocentric top-down semantic map ("what is where?") from egocentric observations of an RGB-D camera with known pose (via localization sensors). Towards this goal, we present SemanticMapNet (SMNet), which consists of: (1) an Egocentric Visual Encoder that encodes each egocentric RGB-D frame, (2) a Feature Projector that projects egocentric features to appropriate locations on a floor-plan, (3) a Spatial Memory Tensor of size floor-plan length x width x feature-dims that learns to accumulate projected egocentric features, and (4) a Map Decoder that uses the memory tensor to produce semantic top-down maps. SMNet combines the strengths of (known) projective camera geometry and neural representation learning. On the task of semantic mapping in the Matterport3D dataset, SMNet significantly outperforms competitive baselines by 4.01-16.81% (absolute) on mean-IoU and 3.81-19.69% (absolute) on Boundary-F1 metrics. Moreover, we show how to use the neural episodic memories and spatio-semantic allocentric representations build by SMNet for subsequent tasks in the same space - navigating to objects seen during the tour("Find chair") or answering questions about the space ("How many chairs did you see in the house?").