 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions
Paper and Code
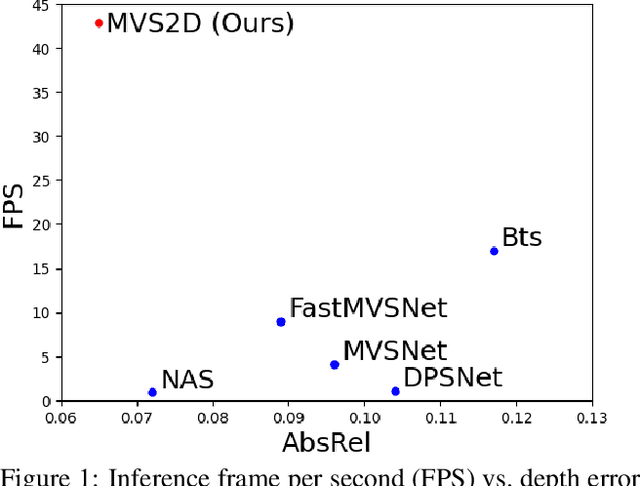

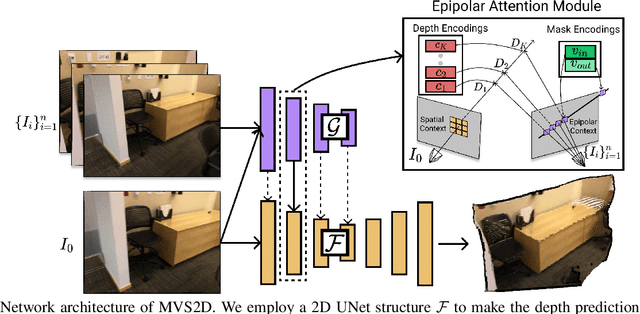

Deep learning has made significant impacts on multi-view stereo systems. State-of-the-art approaches typically involve building a cost volume, followed by multiple 3D convolution operations to recover the input image's pixel-wise depth. While such end-to-end learning of plane-sweeping stereo advances public benchmarks' accuracy, they are typically very slow to compute. We present MVS2D, a highly efficient multi-view stereo algorithm that seamlessly integrates multi-view constraints into single-view networks via an attention mechanism. Since MVS2D only builds on 2D convolutions, it is at least 4x faster than all the notable counterparts. Moreover, our algorithm produces precise depth estimations, achieving state-of-the-art results on challenging benchmarks ScanNet, SUN3D, and RGBD. Even under inexact camera poses, our algorithm still out-performs all other algorithms. Supplementary materials and code will be available at the project page: https://zhenpeiyang.github.io/MVS2D