 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneCrafter: Controllable Multi-View Driving Scene Editing
Jun 24, 2025Simulation is crucial for developing and evaluating autonomous vehicle (AV) systems. Recent literature builds on a new generation of generative models to synthesize highly realistic images for full-stack simulation. However, purely synthetically generated scenes are not grounded in reality and have difficulty in inspiring confidence in the relevance of its outcomes. Editing models, on the other hand, leverage source scenes from real driving logs, and enable the simulation of different traffic layouts, behaviors, and operating conditions such as weather and time of day. While image editing is an established topic in computer vision, it presents fresh sets of challenges in driving simulation: (1) the need for cross-camera 3D consistency, (2) learning ``empty street" priors from driving data with foreground occlusions, and (3) obtaining paired image tuples of varied editing conditions while preserving consistent layout and geometry. To address these challenges, we propose SceneCrafter, a versatile editor for realistic 3D-consistent manipulation of driving scenes captured from multiple cameras. We build on recent advancements in multi-view diffusion models, using a fully controllable framework that scales seamlessly to multi-modality conditions like weather, time of day, agent boxes and high-definition maps. To generate paired data for supervising the editing model, we propose a novel framework on top of Prompt-to-Prompt to generate geometrically consistent synthetic paired data with global edits. We also introduce an alpha-blending framework to synthesize data with local edits, leveraging a model trained on empty street priors through novel masked training and multi-view repaint paradigm. SceneCrafter demonstrates powerful editing capabilities and achieves state-of-the-art realism, controllability, 3D consistency, and scene editing quality compared to existing baselines.
MoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024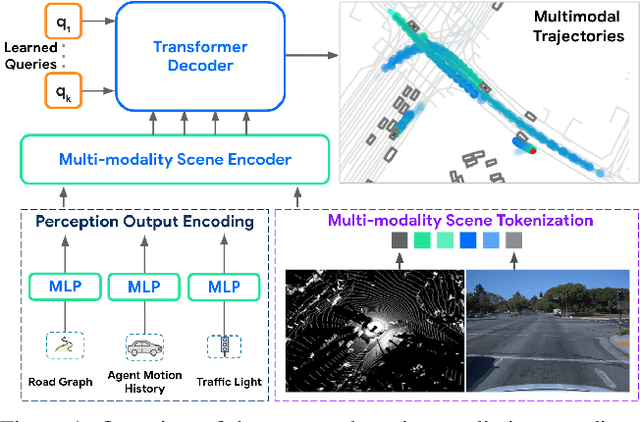

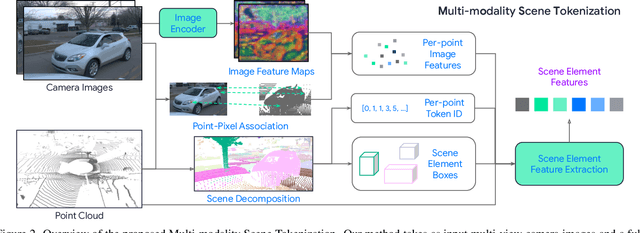
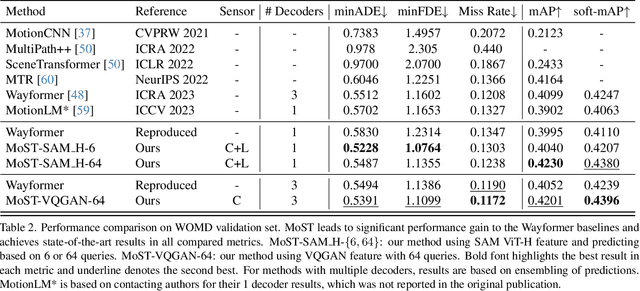
Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
HM3D-ABO: A Photo-realistic Dataset for Object-centric Multi-view 3D Reconstruction
Jun 24, 2022



Reconstructing 3D objects is an important computer vision task that has wide application in AR/VR. Deep learning algorithm developed for this task usually relies on an unrealistic synthetic dataset, such as ShapeNet and Things3D. On the other hand, existing real-captured object-centric datasets usually do not have enough annotation to enable supervised training or reliable evaluation. In this technical report, we present a photo-realistic object-centric dataset HM3D-ABO. It is constructed by composing realistic indoor scene and realistic object. For each configuration, we provide multi-view RGB observations, a water-tight mesh model for the object, ground truth depth map and object mask. The proposed dataset could also be useful for tasks such as camera pose estimation and novel-view synthesis. The dataset generation code is released at https://github.com/zhenpeiyang/HM3D-ABO.
FvOR: Robust Joint Shape and Pose Optimization for Few-view Object Reconstruction
May 16, 2022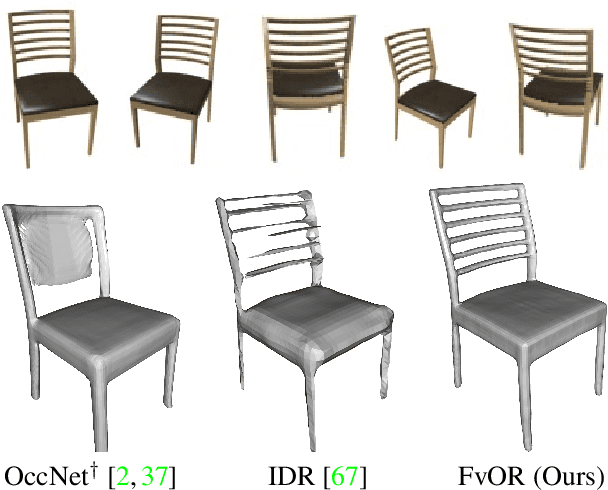

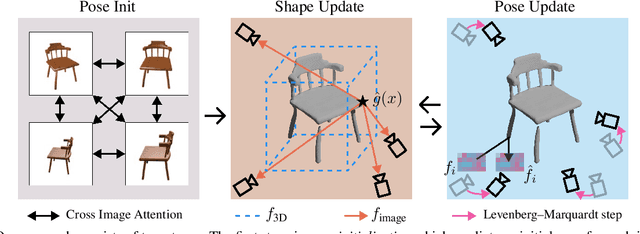

Reconstructing an accurate 3D object model from a few image observations remains a challenging problem in computer vision. State-of-the-art approaches typically assume accurate camera poses as input, which could be difficult to obtain in realistic settings. In this paper, we present FvOR, a learning-based object reconstruction method that predicts accurate 3D models given a few images with noisy input poses. The core of our approach is a fast and robust multi-view reconstruction algorithm to jointly refine 3D geometry and camera pose estimation using learnable neural network modules. We provide a thorough benchmark of state-of-the-art approaches for this problem on ShapeNet. Our approach achieves best-in-class results. It is also two orders of magnitude faster than the recent optimization-based approach IDR. Our code is released at \url{https://github.com/zhenpeiyang/FvOR/}
Implicit Autoencoder for Point Cloud Self-supervised Representation Learning
Jan 03, 2022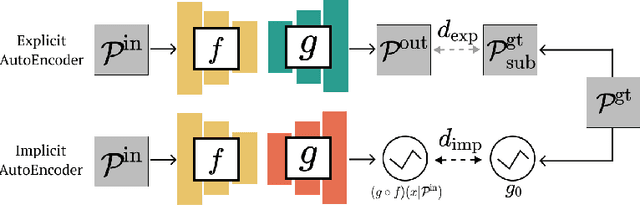
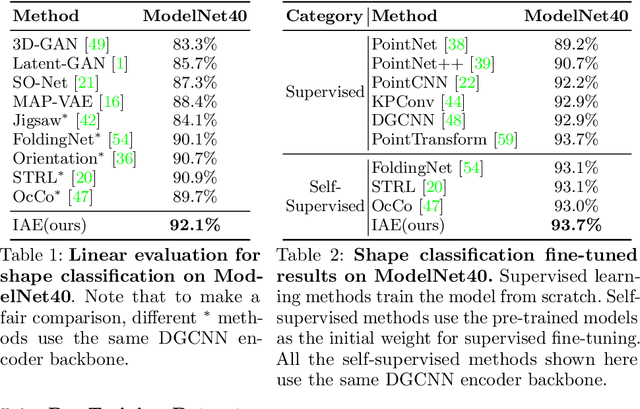
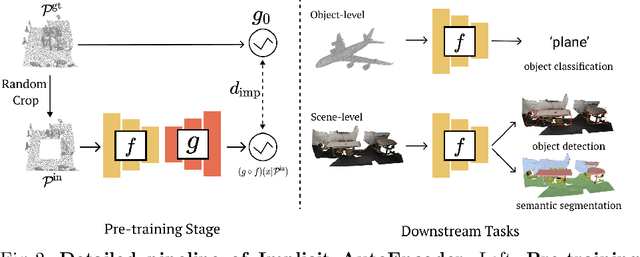

Many 3D representations (e.g., point clouds) are discrete samples of the underlying continuous 3D surface. This process inevitably introduces sampling variations on the underlying 3D shapes. In learning 3D representation, the variations should be disregarded while transferable knowledge of the underlying 3D shape should be captured. This becomes a grand challenge in existing representation learning paradigms. This paper studies autoencoding on point clouds. The standard autoencoding paradigm forces the encoder to capture such sampling variations as the decoder has to reconstruct the original point cloud that has sampling variations. We introduce Implicit Autoencoder(IAE), a simple yet effective method that addresses this challenge by replacing the point cloud decoder with an implicit decoder. The implicit decoder outputs a continuous representation that is shared among different point cloud sampling of the same model. Reconstructing under the implicit representation can prioritize that the encoder discards sampling variations, introducing more space to learn useful features. We theoretically justify this claim under a simple linear autoencoder. Moreover, the implicit decoder offers a rich space to design suitable implicit representations for different tasks. We demonstrate the usefulness of IAE across various self-supervised learning tasks for both 3D objects and 3D scenes. Experimental results show that IAE consistently outperforms the state-of-the-art in each task.
HPNet: Deep Primitive Segmentation Using Hybrid Representations
May 22, 2021

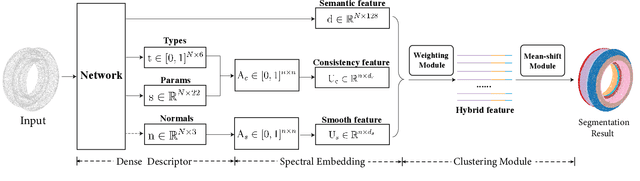
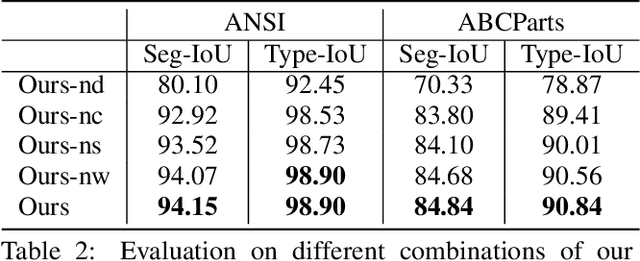
This paper introduces HPNet, a novel deep-learning approach for segmenting a 3D shape represented as a point cloud into primitive patches. The key to deep primitive segmentation is learning a feature representation that can separate points of different primitives. Unlike utilizing a single feature representation, HPNet leverages hybrid representations that combine one learned semantic descriptor, two spectral descriptors derived from predicted geometric parameters, as well as an adjacency matrix that encodes sharp edges. Moreover, instead of merely concatenating the descriptors, HPNet optimally combines hybrid representations by learning combination weights. This weighting module builds on the entropy of input features. The output primitive segmentation is obtained from a mean-shift clustering module. Experimental results on benchmark datasets ANSI and ABCParts show that HPNet leads to significant performance gains from baseline approaches.
MVS2D: Efficient Multi-view Stereo via Attention-Driven 2D Convolutions
Apr 27, 2021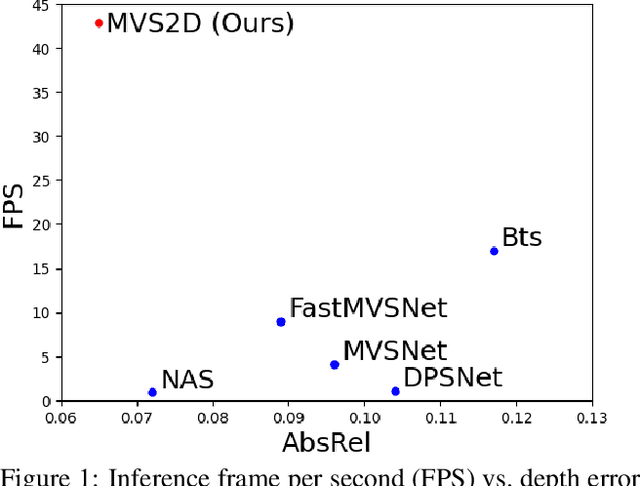

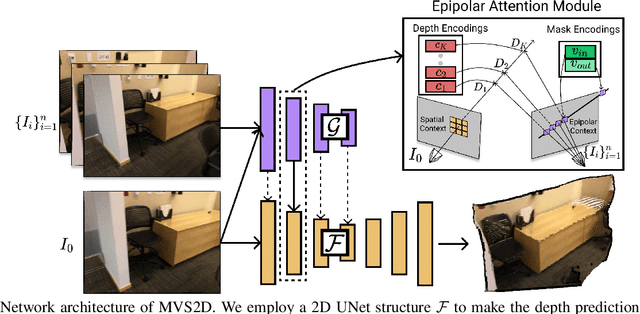

Deep learning has made significant impacts on multi-view stereo systems. State-of-the-art approaches typically involve building a cost volume, followed by multiple 3D convolution operations to recover the input image's pixel-wise depth. While such end-to-end learning of plane-sweeping stereo advances public benchmarks' accuracy, they are typically very slow to compute. We present MVS2D, a highly efficient multi-view stereo algorithm that seamlessly integrates multi-view constraints into single-view networks via an attention mechanism. Since MVS2D only builds on 2D convolutions, it is at least 4x faster than all the notable counterparts. Moreover, our algorithm produces precise depth estimations, achieving state-of-the-art results on challenging benchmarks ScanNet, SUN3D, and RGBD. Even under inexact camera poses, our algorithm still out-performs all other algorithms. Supplementary materials and code will be available at the project page: https://zhenpeiyang.github.io/MVS2D
SurfelGAN: Synthesizing Realistic Sensor Data for Autonomous Driving
May 08, 2020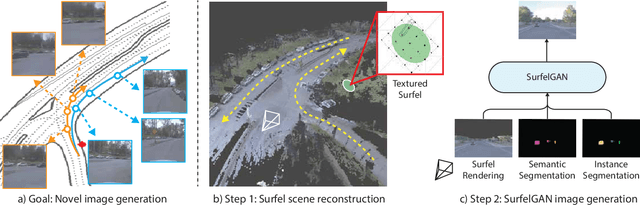



Autonomous driving system development is critically dependent on the ability to replay complex and diverse traffic scenarios in simulation. In such scenarios, the ability to accurately simulate the vehicle sensors such as cameras, lidar or radar is essential. However, current sensor simulators leverage gaming engines such as Unreal or Unity, requiring manual creation of environments, objects and material properties. Such approaches have limited scalability and fail to produce realistic approximations of camera, lidar, and radar data without significant additional work. In this paper, we present a simple yet effective approach to generate realistic scenario sensor data, based only on a limited amount of lidar and camera data collected by an autonomous vehicle. Our approach uses texture-mapped surfels to efficiently reconstruct the scene from an initial vehicle pass or set of passes, preserving rich information about object 3D geometry and appearance, as well as the scene conditions. We then leverage a SurfelGAN network to reconstruct realistic camera images for novel positions and orientations of the self-driving vehicle and moving objects in the scene. We demonstrate our approach on the Waymo Open Dataset and show that it can synthesize realistic camera data for simulated scenarios. We also create a novel dataset that contains cases in which two self-driving vehicles observe the same scene at the same time. We use this dataset to provide additional evaluation and demonstrate the usefulness of our SurfelGAN model.
Extreme Relative Pose Network under Hybrid Representations
Dec 25, 2019
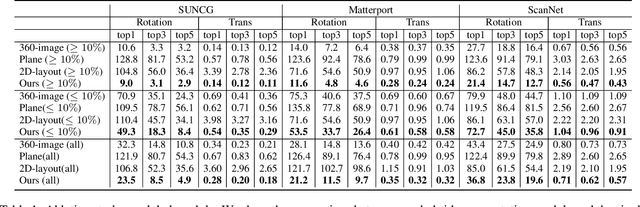
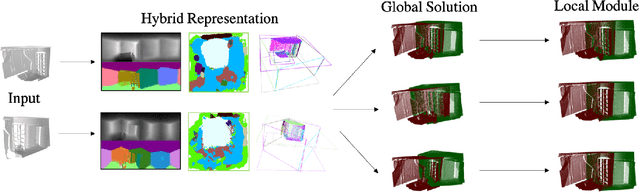

In this paper, we introduce a novel RGB-D based relative pose estimation approach that is suitable for small-overlapping or non-overlapping scans and can output multiple relative poses. Our method performs scene completion and matches the completed scans. However, instead of using a fixed representation for completion, the key idea is to utilize hybrid representations that combine 360-image, 2D image-based layout, and planar patches. This approach offers adaptively feature representations for relative pose estimation. Besides, we introduce a global-2-local matching procedure, which utilizes initial relative poses obtained during the global phase to detect and then integrate geometric relations for pose refinement. Experimental results justify the potential of this approach across a wide range of benchmark datasets. For example, on ScanNet, the rotation translation errors of the top-1/top-5 predictions of our approach are 34.9/0.69m and 19.6/0.57m, respectively. Our approach also considerably boosts the performance of multi-scan reconstruction in few-view reconstruction settings.
Extreme Relative Pose Estimation for RGB-D Scans via Scene Completion
Jan 05, 2019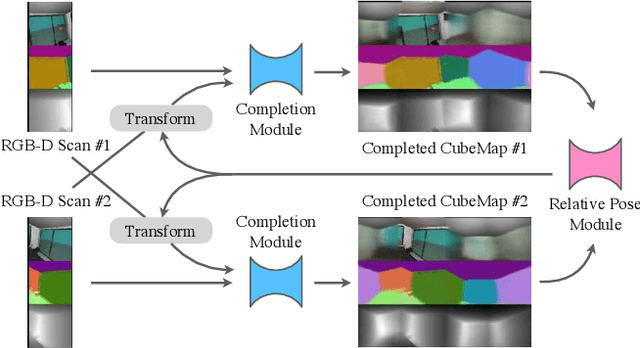
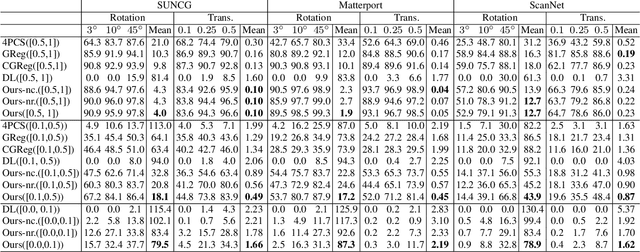

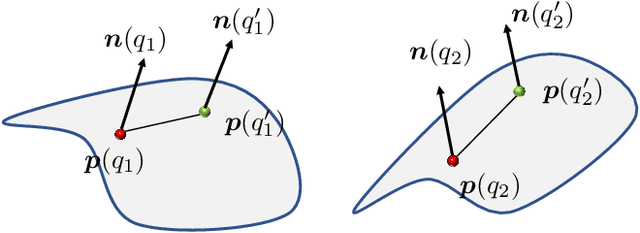
Estimating the relative rigid pose between two RGB-D scans of the same underlying environment is a fundamental problem in computer vision, robotics, and computer graphics. Most existing approaches allow only limited maximum relative pose changes since they require considerable overlap between the input scans. We introduce a novel deep neural network that extends the scope to extreme relative poses, with little or even no overlap between the input scans. The key idea is to infer more complete scene information about the underlying environment and match on the completed scans. In particular, instead of only performing scene completion from each individual scan, our approach alternates between relative pose estimation and scene completion. This allows us to perform scene completion by utilizing information from both input scans at late iterations, resulting in better results for both scene completion and relative pose estimation. Experimental results on benchmark datasets show that our approach leads to considerable improvements over state-of-the-art approaches for relative pose estimation. In particular, our approach provides encouraging relative pose estimates even between non-overlapping scans.