 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Oriented Edge-Assisted Cross-System Design for Real-Time Human-Robot Interaction in Industrial Metaverse
Aug 28, 2025Real-time human-device interaction in industrial Metaverse faces challenges such as high computational load, limited bandwidth, and strict latency. This paper proposes a task-oriented edge-assisted cross-system framework using digital twins (DTs) to enable responsive interactions. By predicting operator motions, the system supports: 1) proactive Metaverse rendering for visual feedback, and 2) preemptive control of remote devices. The DTs are decoupled into two virtual functions-visual display and robotic control-optimizing both performance and adaptability. To enhance generalizability, we introduce the Human-In-The-Loop Model-Agnostic Meta-Learning (HITL-MAML) algorithm, which dynamically adjusts prediction horizons. Evaluation on two tasks demonstrates the framework's effectiveness: in a Trajectory-Based Drawing Control task, it reduces weighted RMSE from 0.0712 m to 0.0101 m; in a real-time 3D scene representation task for nuclear decommissioning, it achieves a PSNR of 22.11, SSIM of 0.8729, and LPIPS of 0.1298. These results show the framework's capability to ensure spatial precision and visual fidelity in real-time, high-risk industrial environments.
Haptic-Based User Authentication for Tele-robotic System
Jun 17, 2025Tele-operated robots rely on real-time user behavior mapping for remote tasks, but ensuring secure authentication remains a challenge. Traditional methods, such as passwords and static biometrics, are vulnerable to spoofing and replay attacks, particularly in high-stakes, continuous interactions. This paper presents a novel anti-spoofing and anti-replay authentication approach that leverages distinctive user behavioral features extracted from haptic feedback during human-robot interactions. To evaluate our authentication approach, we collected a time-series force feedback dataset from 15 participants performing seven distinct tasks. We then developed a transformer-based deep learning model to extract temporal features from the haptic signals. By analyzing user-specific force dynamics, our method achieves over 90 percent accuracy in both user identification and task classification, demonstrating its potential for enhancing access control and identity assurance in tele-robotic systems.
Vine Copulas as Differentiable Computational Graphs
Jun 16, 2025Vine copulas are sophisticated models for multivariate distributions and are increasingly used in machine learning. To facilitate their integration into modern ML pipelines, we introduce the vine computational graph, a DAG that abstracts the multilevel vine structure and associated computations. On this foundation, we devise new algorithms for conditional sampling, efficient sampling-order scheduling, and constructing vine structures for customized conditioning variables. We implement these ideas in torchvinecopulib, a GPU-accelerated Python library built upon PyTorch, delivering improved scalability for fitting, sampling, and density evaluation. Our experiments illustrate how gradient flowing through the vine can improve Vine Copula Autoencoders and that incorporating vines for uncertainty quantification in deep learning can outperform MC-dropout, deep ensembles, and Bayesian Neural Networks in sharpness, calibration, and runtime. By recasting vine copula models as computational graphs, our work connects classical dependence modeling with modern deep-learning toolchains and facilitates the integration of state-of-the-art copula methods in modern machine learning pipelines.
Preference-Driven Active 3D Scene Representation for Robotic Inspection in Nuclear Decommissioning
Apr 02, 2025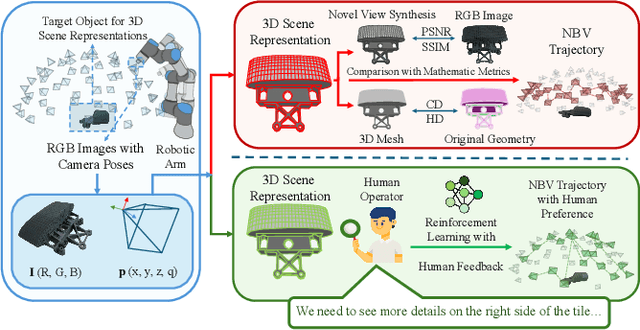
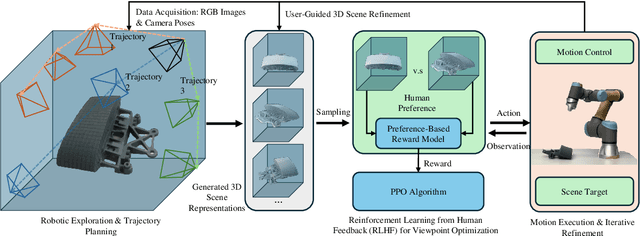
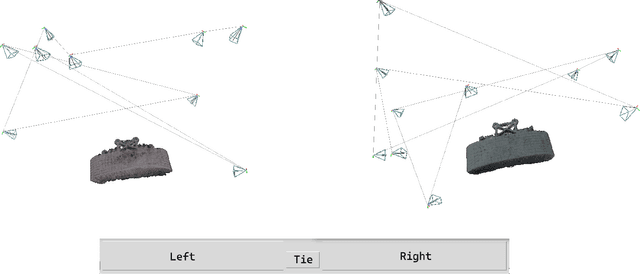
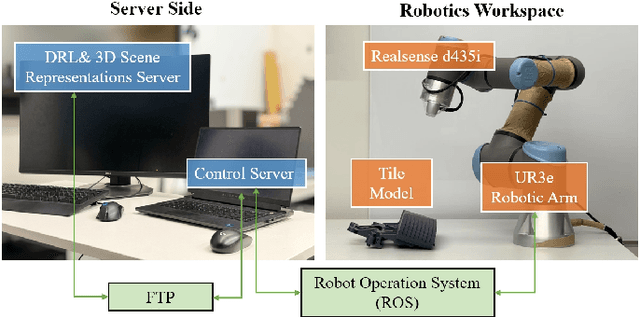
Active 3D scene representation is pivotal in modern robotics applications, including remote inspection, manipulation, and telepresence. Traditional methods primarily optimize geometric fidelity or rendering accuracy, but often overlook operator-specific objectives, such as safety-critical coverage or task-driven viewpoints. This limitation leads to suboptimal viewpoint selection, particularly in constrained environments such as nuclear decommissioning. To bridge this gap, we introduce a novel framework that integrates expert operator preferences into the active 3D scene representation pipeline. Specifically, we employ Reinforcement Learning from Human Feedback (RLHF) to guide robotic path planning, reshaping the reward function based on expert input. To capture operator-specific priorities, we conduct interactive choice experiments that evaluate user preferences in 3D scene representation. We validate our framework using a UR3e robotic arm for reactor tile inspection in a nuclear decommissioning scenario. Compared to baseline methods, our approach enhances scene representation while optimizing trajectory efficiency. The RLHF-based policy consistently outperforms random selection, prioritizing task-critical details. By unifying explicit 3D geometric modeling with implicit human-in-the-loop optimization, this work establishes a foundation for adaptive, safety-critical robotic perception systems, paving the way for enhanced automation in nuclear decommissioning, remote maintenance, and other high-risk environments.
Task-Oriented Edge-Assisted Cooperative Data Compression, Communications and Computing for UGV-Enhanced Warehouse Logistics
Oct 02, 2024



Only the chairs can edit This paper explores the growing need for task-oriented communications in warehouse logistics, where traditional communication Key Performance Indicators (KPIs)-such as latency, reliability, and throughput-often do not fully meet task requirements. As the complexity of data flow management in large-scale device networks increases, there is also a pressing need for innovative cross-system designs that balance data compression, communication, and computation. To address these challenges, we propose a task-oriented, edge-assisted framework for cooperative data compression, communication, and computing in Unmanned Ground Vehicle (UGV)-enhanced warehouse logistics. In this framework, two UGVs collaborate to transport cargo, with control functions-navigation for the front UGV and following/conveyance for the rear UGV-offloaded to the edge server to accommodate their limited on-board computing resources. We develop a Deep Reinforcement Learning (DRL)-based two-stage point cloud data compression algorithm that dynamically and collaboratively adjusts compression ratios according to task requirements, significantly reducing communication overhead. System-level simulations of our UGV logistics prototype demonstrate the framework's effectiveness and its potential for swift real-world implementation.
Real-Time Interactions Between Human Controllers and Remote Devices in Metaverse
Jul 23, 2024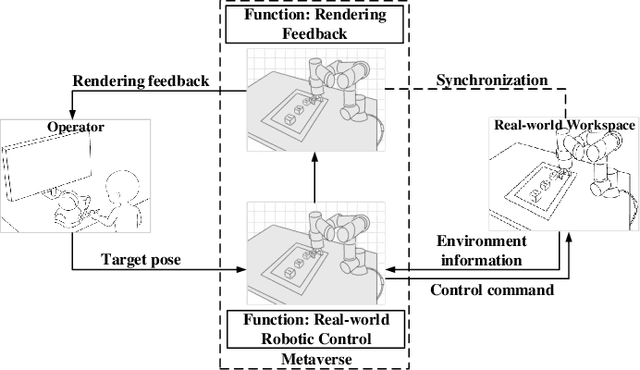
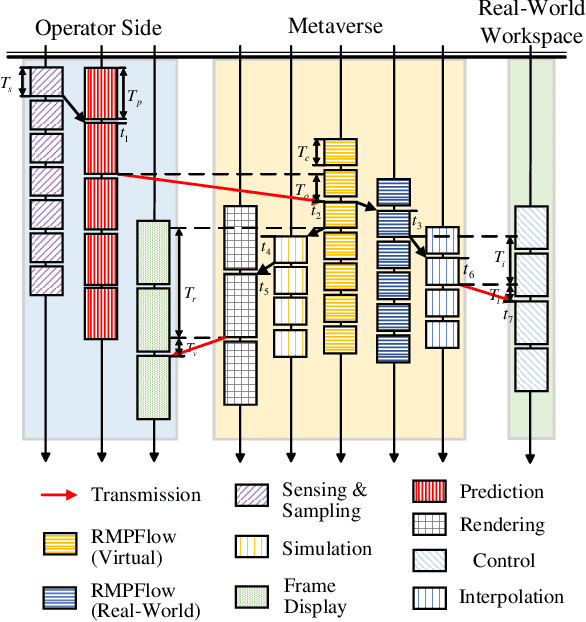
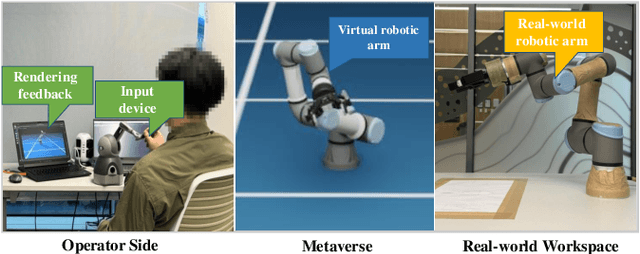
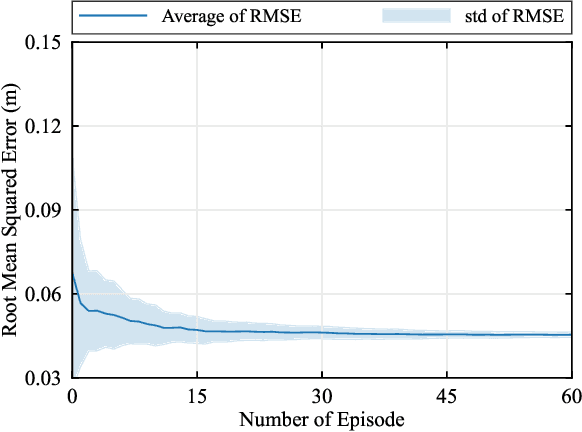
Supporting real-time interactions between human controllers and remote devices remains a challenging goal in the Metaverse due to the stringent requirements on computing workload, communication throughput, and round-trip latency. In this paper, we establish a novel framework for real-time interactions through the virtual models in the Metaverse. Specifically, we jointly predict the motion of the human controller for 1) proactive rendering in the Metaverse and 2) generating control commands to the real-world remote device in advance. The virtual model is decoupled into two components for rendering and control, respectively. To dynamically adjust the prediction horizons for rendering and control, we develop a two-step human-in-the-loop continuous reinforcement learning approach and use an expert policy to improve the training efficiency. An experimental prototype is built to verify our algorithm with different communication latencies. Compared with the baseline policy without prediction, our proposed method can reduce 1) the Motion-To-Photon (MTP) latency between human motion and rendering feedback and 2) the root mean squared error (RMSE) between human motion and real-world remote devices significantly.
DISCRET: Synthesizing Faithful Explanations For Treatment Effect Estimation
Jun 02, 2024


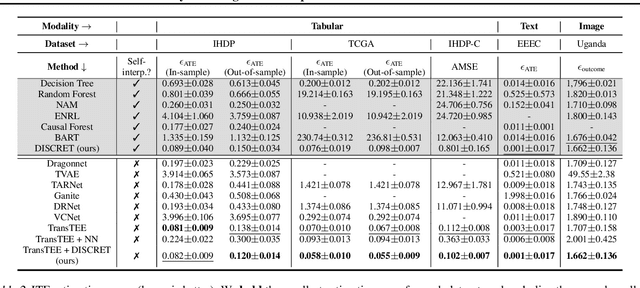
Designing faithful yet accurate AI models is challenging, particularly in the field of individual treatment effect estimation (ITE). ITE prediction models deployed in critical settings such as healthcare should ideally be (i) accurate, and (ii) provide faithful explanations. However, current solutions are inadequate: state-of-the-art black-box models do not supply explanations, post-hoc explainers for black-box models lack faithfulness guarantees, and self-interpretable models greatly compromise accuracy. To address these issues, we propose DISCRET, a self-interpretable ITE framework that synthesizes faithful, rule-based explanations for each sample. A key insight behind DISCRET is that explanations can serve dually as database queries to identify similar subgroups of samples. We provide a novel RL algorithm to efficiently synthesize these explanations from a large search space. We evaluate DISCRET on diverse tasks involving tabular, image, and text data. DISCRET outperforms the best self-interpretable models and has accuracy comparable to the best black-box models while providing faithful explanations. DISCRET is available at https://github.com/wuyinjun-1993/DISCRET-ICML2024.
MoST: Multi-modality Scene Tokenization for Motion Prediction
Apr 30, 2024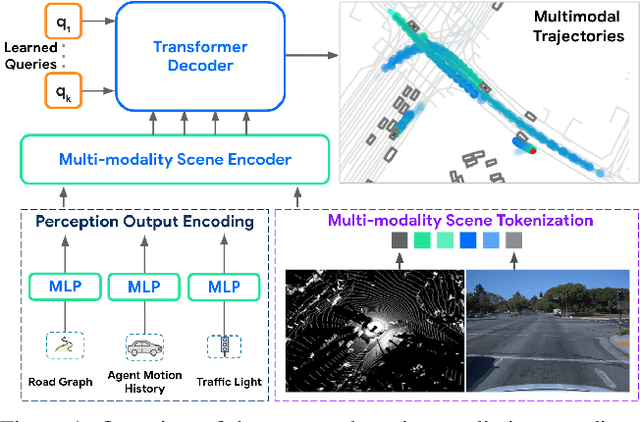

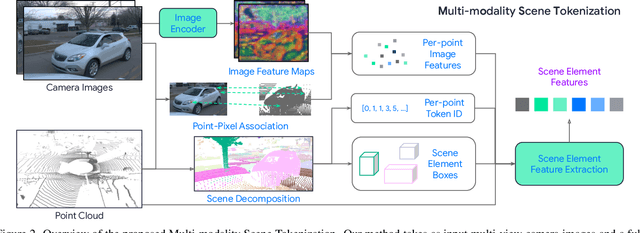
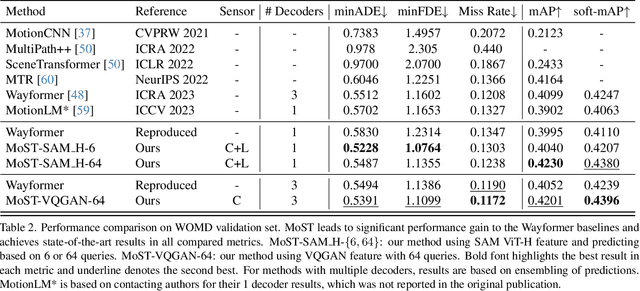
Many existing motion prediction approaches rely on symbolic perception outputs to generate agent trajectories, such as bounding boxes, road graph information and traffic lights. This symbolic representation is a high-level abstraction of the real world, which may render the motion prediction model vulnerable to perception errors (e.g., failures in detecting open-vocabulary obstacles) while missing salient information from the scene context (e.g., poor road conditions). An alternative paradigm is end-to-end learning from raw sensors. However, this approach suffers from the lack of interpretability and requires significantly more training resources. In this work, we propose tokenizing the visual world into a compact set of scene elements and then leveraging pre-trained image foundation models and LiDAR neural networks to encode all the scene elements in an open-vocabulary manner. The image foundation model enables our scene tokens to encode the general knowledge of the open world while the LiDAR neural network encodes geometry information. Our proposed representation can efficiently encode the multi-frame multi-modality observations with a few hundred tokens and is compatible with most transformer-based architectures. To evaluate our method, we have augmented Waymo Open Motion Dataset with camera embeddings. Experiments over Waymo Open Motion Dataset show that our approach leads to significant performance improvements over the state-of-the-art.
Task-Oriented Cross-System Design for Timely and Accurate Modeling in the Metaverse
Sep 11, 2023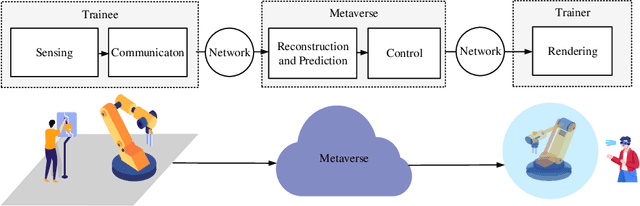
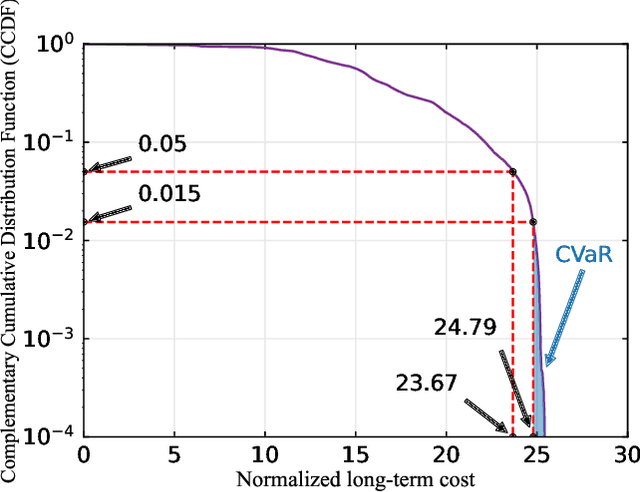
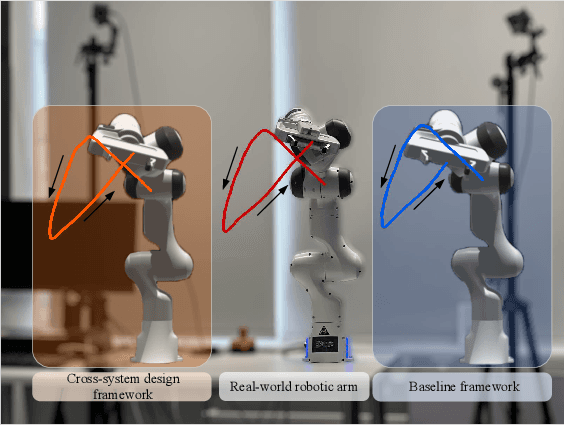
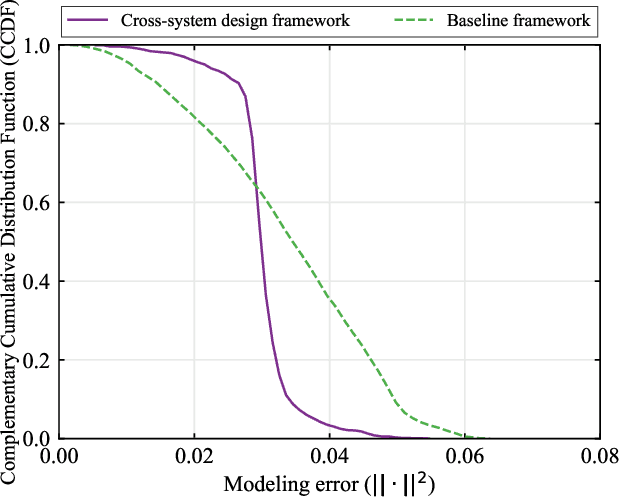
In this paper, we establish a task-oriented cross-system design framework to minimize the required packet rate for timely and accurate modeling of a real-world robotic arm in the Metaverse, where sensing, communication, prediction, control, and rendering are considered. To optimize a scheduling policy and prediction horizons, we design a Constraint Proximal Policy Optimization(C-PPO) algorithm by integrating domain knowledge from relevant systems into the advanced reinforcement learning algorithm, Proximal Policy Optimization(PPO). Specifically, the Jacobian matrix for analyzing the motion of the robotic arm is included in the state of the C-PPO algorithm, and the Conditional Value-at-Risk(CVaR) of the state-value function characterizing the long-term modeling error is adopted in the constraint. Besides, the policy is represented by a two-branch neural network determining the scheduling policy and the prediction horizons, respectively. To evaluate our algorithm, we build a prototype including a real-world robotic arm and its digital model in the Metaverse. The experimental results indicate that domain knowledge helps to reduce the convergence time and the required packet rate by up to 50%, and the cross-system design framework outperforms a baseline framework in terms of the required packet rate and the tail distribution of the modeling error.
WOMD-LiDAR: Raw Sensor Dataset Benchmark for Motion Forecasting
Apr 07, 2023



Widely adopted motion forecasting datasets substitute the observed sensory inputs with higher-level abstractions such as 3D boxes and polylines. These sparse shapes are inferred through annotating the original scenes with perception systems' predictions. Such intermediate representations tie the quality of the motion forecasting models to the performance of computer vision models. Moreover, the human-designed explicit interfaces between perception and motion forecasting typically pass only a subset of the semantic information present in the original sensory input. To study the effect of these modular approaches, design new paradigms that mitigate these limitations, and accelerate the development of end-to-end motion forecasting models, we augment the Waymo Open Motion Dataset (WOMD) with large-scale, high-quality, diverse LiDAR data for the motion forecasting task. The new augmented dataset WOMD-LiDAR consists of over 100,000 scenes that each spans 20 seconds, consisting of well-synchronized and calibrated high quality LiDAR point clouds captured across a range of urban and suburban geographies (https://waymo.com/open/data/motion/). Compared to Waymo Open Dataset (WOD), WOMD-LiDAR dataset contains 100x more scenes. Furthermore, we integrate the LiDAR data into the motion forecasting model training and provide a strong baseline. Experiments show that the LiDAR data brings improvement in the motion forecasting task. We hope that WOMD-LiDAR will provide new opportunities for boosting end-to-end motion forecasting models.