 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNarrowing the Coordinate-frame Gap in Behavior Prediction Models: Distillation for Efficient and Accurate Scene-centric Motion Forecasting
Jun 10, 2022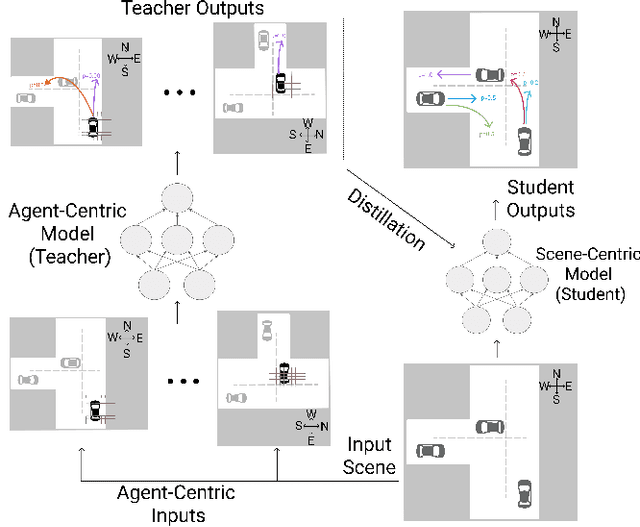
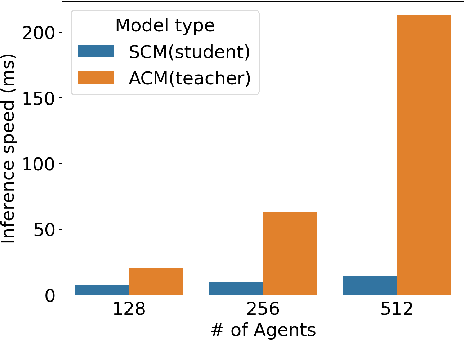
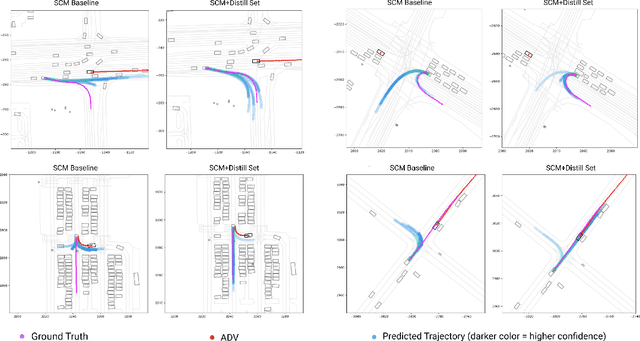
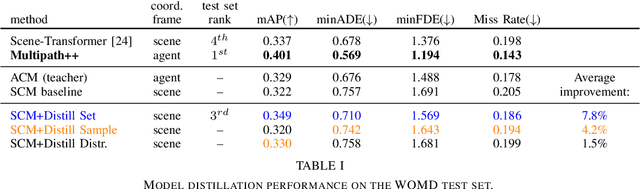
Behavior prediction models have proliferated in recent years, especially in the popular real-world robotics application of autonomous driving, where representing the distribution over possible futures of moving agents is essential for safe and comfortable motion planning. In these models, the choice of coordinate frames to represent inputs and outputs has crucial trade offs which broadly fall into one of two categories. Agent-centric models transform inputs and perform inference in agent-centric coordinates. These models are intrinsically invariant to translation and rotation between scene elements, are best-performing on public leaderboards, but scale quadratically with the number of agents and scene elements. Scene-centric models use a fixed coordinate system to process all agents. This gives them the advantage of sharing representations among all agents, offering efficient amortized inference computation which scales linearly with the number of agents. However, these models have to learn invariance to translation and rotation between scene elements, and typically underperform agent-centric models. In this work, we develop knowledge distillation techniques between probabilistic motion forecasting models, and apply these techniques to close the gap in performance between agent-centric and scene-centric models. This improves scene-centric model performance by 13.2% on the public Argoverse benchmark, 7.8% on Waymo Open Dataset and up to 9.4% on a large In-House dataset. These improved scene-centric models rank highly in public leaderboards and are up to 15 times more efficient than their agent-centric teacher counterparts in busy scenes.
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021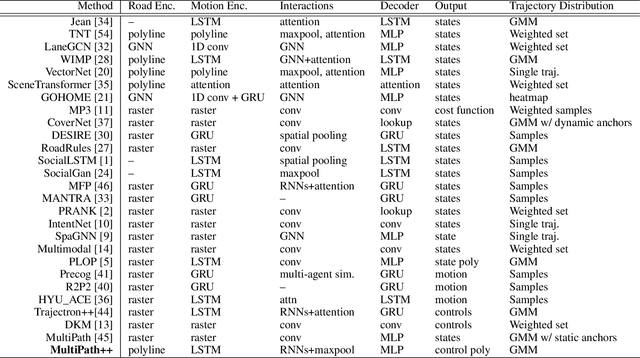
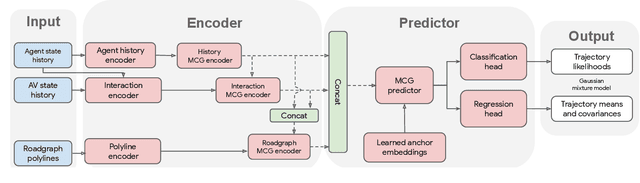
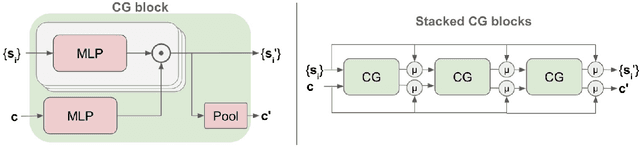
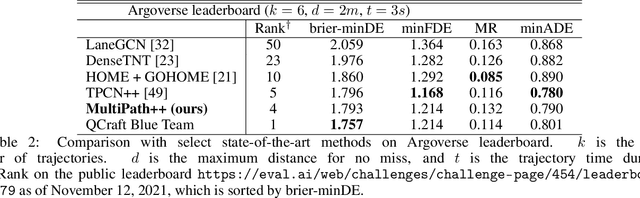
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
An Attention-based Recurrent Convolutional Network for Vehicle Taillight Recognition
Jun 09, 2019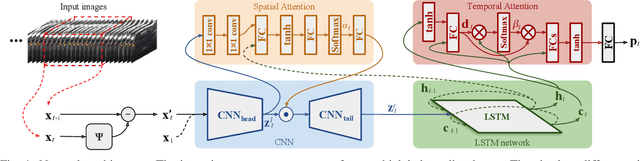

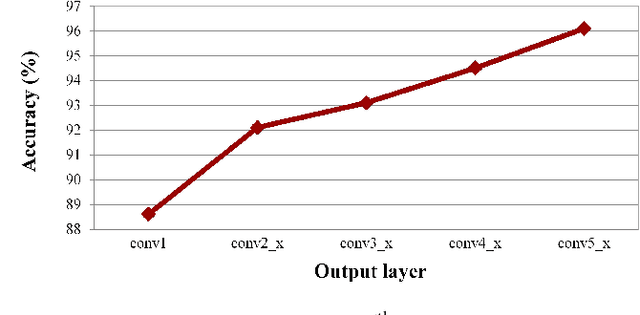
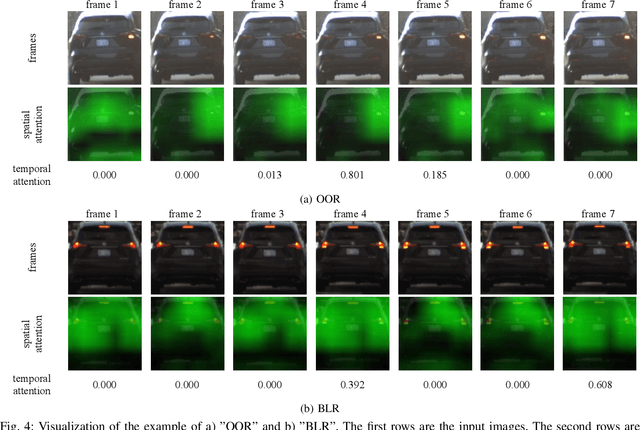
Vehicle taillight recognition is an important application for automated driving, especially for intent prediction of ado vehicles and trajectory planning of the ego vehicle. In this work, we propose an end-to-end deep learning framework to recognize taillights, i.e. rear turn and brake signals, from a sequence of images. The proposed method starts with a Convolutional Neural Network (CNN) to extract spatial features, and then applies a Long Short-Term Memory network (LSTM) to learn temporal dependencies. Furthermore, we integrate attention models in both spatial and temporal domains, where the attention models learn to selectively focus on both spatial and temporal features. Our method is able to outperform the state of the art in terms of accuracy on the UC Merced Vehicle Rear Signal Dataset, demonstrating the effectiveness of attention models for vehicle taillight recognition.