 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoAuto-R1: Video Auto Reasoning via Thinking Once, Answering Twice
Jan 08, 2026Chain-of-thought (CoT) reasoning has emerged as a powerful tool for multimodal large language models on video understanding tasks. However, its necessity and advantages over direct answering remain underexplored. In this paper, we first demonstrate that for RL-trained video models, direct answering often matches or even surpasses CoT performance, despite CoT producing step-by-step analyses at a higher computational cost. Motivated by this, we propose VideoAuto-R1, a video understanding framework that adopts a reason-when-necessary strategy. During training, our approach follows a Thinking Once, Answering Twice paradigm: the model first generates an initial answer, then performs reasoning, and finally outputs a reviewed answer. Both answers are supervised via verifiable rewards. During inference, the model uses the confidence score of the initial answer to determine whether to proceed with reasoning. Across video QA and grounding benchmarks, VideoAuto-R1 achieves state-of-the-art accuracy with significantly improved efficiency, reducing the average response length by ~3.3x, e.g., from 149 to just 44 tokens. Moreover, we observe a low rate of thinking-mode activation on perception-oriented tasks, but a higher rate on reasoning-intensive tasks. This suggests that explicit language-based reasoning is generally beneficial but not always necessary.
Efficient Track Anything
Nov 28, 2024Segment Anything Model 2 (SAM 2) has emerged as a powerful tool for video object segmentation and tracking anything. Key components of SAM 2 that drive the impressive video object segmentation performance include a large multistage image encoder for frame feature extraction and a memory mechanism that stores memory contexts from past frames to help current frame segmentation. The high computation complexity of multistage image encoder and memory module has limited its applications in real-world tasks, e.g., video object segmentation on mobile devices. To address this limitation, we propose EfficientTAMs, lightweight track anything models that produce high-quality results with low latency and model size. Our idea is based on revisiting the plain, nonhierarchical Vision Transformer (ViT) as an image encoder for video object segmentation, and introducing an efficient memory module, which reduces the complexity for both frame feature extraction and memory computation for current frame segmentation. We take vanilla lightweight ViTs and efficient memory module to build EfficientTAMs, and train the models on SA-1B and SA-V datasets for video object segmentation and track anything tasks. We evaluate on multiple video segmentation benchmarks including semi-supervised VOS and promptable video segmentation, and find that our proposed EfficientTAM with vanilla ViT perform comparably to SAM 2 model (HieraB+SAM 2) with ~2x speedup on A100 and ~2.4x parameter reduction. On segment anything image tasks, our EfficientTAMs also perform favorably over original SAM with ~20x speedup on A100 and ~20x parameter reduction. On mobile devices such as iPhone 15 Pro Max, our EfficientTAMs can run at ~10 FPS for performing video object segmentation with reasonable quality, highlighting the capability of small models for on-device video object segmentation applications.
LongVU: Spatiotemporal Adaptive Compression for Long Video-Language Understanding
Oct 22, 2024



Multimodal Large Language Models (MLLMs) have shown promising progress in understanding and analyzing video content. However, processing long videos remains a significant challenge constrained by LLM's context size. To address this limitation, we propose LongVU, a spatiotemporal adaptive compression mechanism thats reduces the number of video tokens while preserving visual details of long videos. Our idea is based on leveraging cross-modal query and inter-frame dependencies to adaptively reduce temporal and spatial redundancy in videos. Specifically, we leverage DINOv2 features to remove redundant frames that exhibit high similarity. Then we utilize text-guided cross-modal query for selective frame feature reduction. Further, we perform spatial token reduction across frames based on their temporal dependencies. Our adaptive compression strategy effectively processes a large number of frames with little visual information loss within given context length. Our LongVU consistently surpass existing methods across a variety of video understanding benchmarks, especially on hour-long video understanding tasks such as VideoMME and MLVU. Given a light-weight LLM, our LongVU also scales effectively into a smaller size with state-of-the-art video understanding performance.
SqueezeSAM: User friendly mobile interactive segmentation
Dec 11, 2023Segment Anything Model (SAM) is a foundation model for interactive segmentation, and it has catalyzed major advances in generative AI, computational photography, and medical imaging. This model takes in an arbitrary user input and provides segmentation masks of the corresponding objects. It is our goal to develop a version of SAM that is appropriate for use in a photography app. The original SAM model has a few challenges in this setting. First, original SAM a 600 million parameter based on ViT-H, and its high computational cost and large model size that are not suitable for todays mobile hardware. We address this by proposing the SqueezeSAM model architecture, which is 50x faster and 100x smaller than SAM. Next, when a user takes a photo on their phone, it might not occur to them to click on the image and get a mask. Our solution is to use salient object detection to generate the first few clicks. This produces an initial segmentation mask that the user can interactively edit. Finally, when a user clicks on an object, they typically expect all related pieces of the object to be segmented. For instance, if a user clicks on a person t-shirt in a photo, they expect the whole person to be segmented, but SAM typically segments just the t-shirt. We address this with a new data augmentation scheme, and the end result is that if the user clicks on a person holding a basketball, the person and the basketball are all segmented together.
KEMP: Keyframe-Based Hierarchical End-to-End Deep Model for Long-Term Trajectory Prediction
May 10, 2022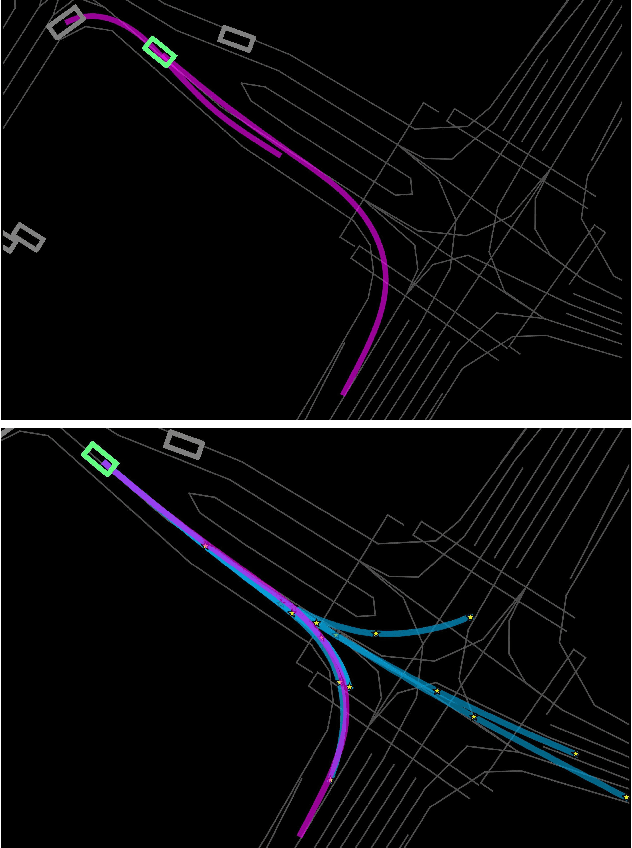
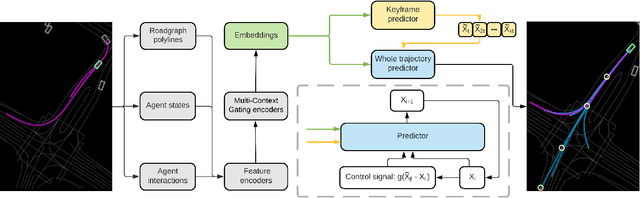
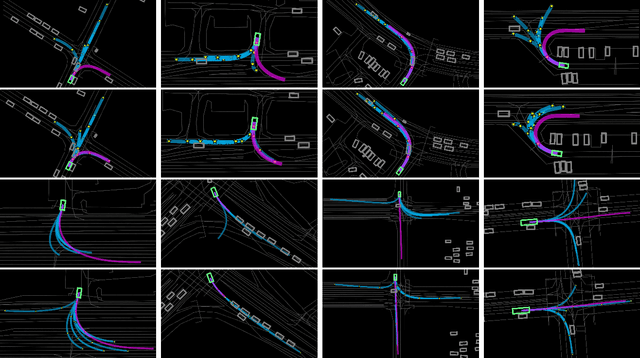
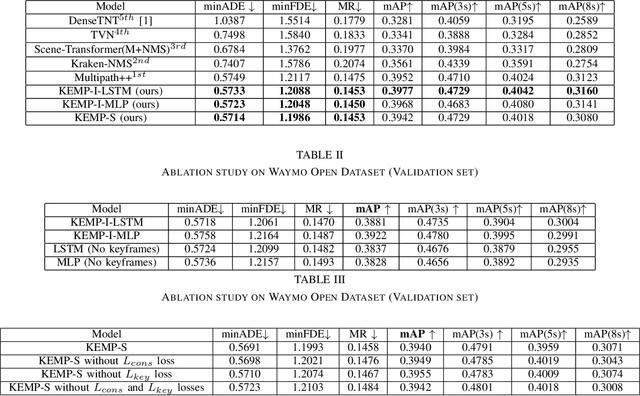
Predicting future trajectories of road agents is a critical task for autonomous driving. Recent goal-based trajectory prediction methods, such as DenseTNT and PECNet, have shown good performance on prediction tasks on public datasets. However, they usually require complicated goal-selection algorithms and optimization. In this work, we propose KEMP, a hierarchical end-to-end deep learning framework for trajectory prediction. At the core of our framework is keyframe-based trajectory prediction, where keyframes are representative states that trace out the general direction of the trajectory. KEMP first predicts keyframes conditioned on the road context, and then fills in intermediate states conditioned on the keyframes and the road context. Under our general framework, goal-conditioned methods are special cases in which the number of keyframes equal to one. Unlike goal-conditioned methods, our keyframe predictor is learned automatically and does not require hand-crafted goal-selection algorithms. We evaluate our model on public benchmarks and our model ranked 1st on Waymo Open Motion Dataset Leaderboard (as of September 1, 2021).
MultiPath++: Efficient Information Fusion and Trajectory Aggregation for Behavior Prediction
Dec 22, 2021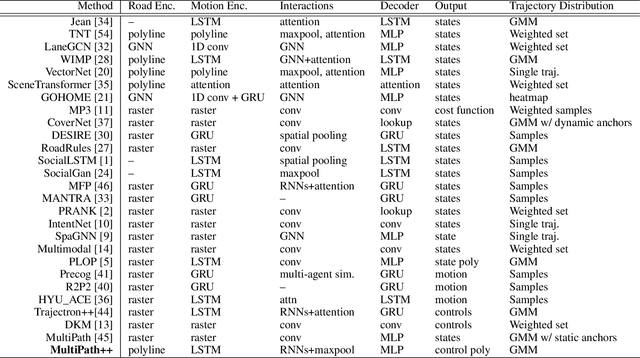
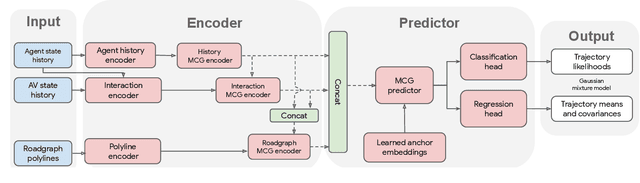
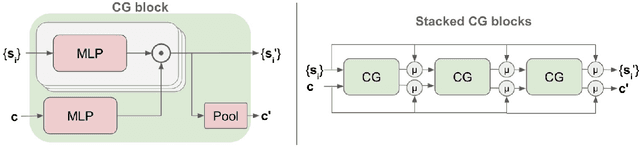
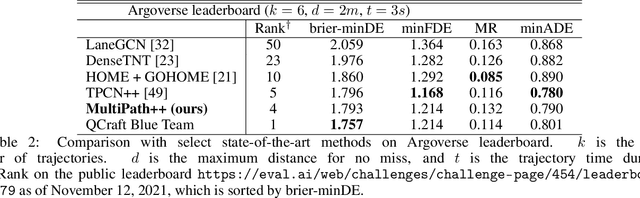
Predicting the future behavior of road users is one of the most challenging and important problems in autonomous driving. Applying deep learning to this problem requires fusing heterogeneous world state in the form of rich perception signals and map information, and inferring highly multi-modal distributions over possible futures. In this paper, we present MultiPath++, a future prediction model that achieves state-of-the-art performance on popular benchmarks. MultiPath++ improves the MultiPath architecture by revisiting many design choices. The first key design difference is a departure from dense image-based encoding of the input world state in favor of a sparse encoding of heterogeneous scene elements: MultiPath++ consumes compact and efficient polylines to describe road features, and raw agent state information directly (e.g., position, velocity, acceleration). We propose a context-aware fusion of these elements and develop a reusable multi-context gating fusion component. Second, we reconsider the choice of pre-defined, static anchors, and develop a way to learn latent anchor embeddings end-to-end in the model. Lastly, we explore ensembling and output aggregation techniques -- common in other ML domains -- and find effective variants for our probabilistic multimodal output representation. We perform an extensive ablation on these design choices, and show that our proposed model achieves state-of-the-art performance on the Argoverse Motion Forecasting Competition and the Waymo Open Dataset Motion Prediction Challenge.
TNT: Target-driveN Trajectory Prediction
Aug 21, 2020



Predicting the future behavior of moving agents is essential for real world applications. It is challenging as the intent of the agent and the corresponding behavior is unknown and intrinsically multimodal. Our key insight is that for prediction within a moderate time horizon, the future modes can be effectively captured by a set of target states. This leads to our target-driven trajectory prediction (TNT) framework. TNT has three stages which are trained end-to-end. It first predicts an agent's potential target states $T$ steps into the future, by encoding its interactions with the environment and the other agents. TNT then generates trajectory state sequences conditioned on targets. A final stage estimates trajectory likelihoods and a final compact set of trajectory predictions is selected. This is in contrast to previous work which models agent intents as latent variables, and relies on test-time sampling to generate diverse trajectories. We benchmark TNT on trajectory prediction of vehicles and pedestrians, where we outperform state-of-the-art on Argoverse Forecasting, INTERACTION, Stanford Drone and an in-house Pedestrian-at-Intersection dataset.
YouTube-8M: A Large-Scale Video Classification Benchmark
Sep 27, 2016



Many recent advancements in Computer Vision are attributed to large datasets. Open-source software packages for Machine Learning and inexpensive commodity hardware have reduced the barrier of entry for exploring novel approaches at scale. It is possible to train models over millions of examples within a few days. Although large-scale datasets exist for image understanding, such as ImageNet, there are no comparable size video classification datasets. In this paper, we introduce YouTube-8M, the largest multi-label video classification dataset, composed of ~8 million videos (500K hours of video), annotated with a vocabulary of 4800 visual entities. To get the videos and their labels, we used a YouTube video annotation system, which labels videos with their main topics. While the labels are machine-generated, they have high-precision and are derived from a variety of human-based signals including metadata and query click signals. We filtered the video labels (Knowledge Graph entities) using both automated and manual curation strategies, including asking human raters if the labels are visually recognizable. Then, we decoded each video at one-frame-per-second, and used a Deep CNN pre-trained on ImageNet to extract the hidden representation immediately prior to the classification layer. Finally, we compressed the frame features and make both the features and video-level labels available for download. We trained various (modest) classification models on the dataset, evaluated them using popular evaluation metrics, and report them as baselines. Despite the size of the dataset, some of our models train to convergence in less than a day on a single machine using TensorFlow. We plan to release code for training a TensorFlow model and for computing metrics.
Efficient Large Scale Video Classification
May 22, 2015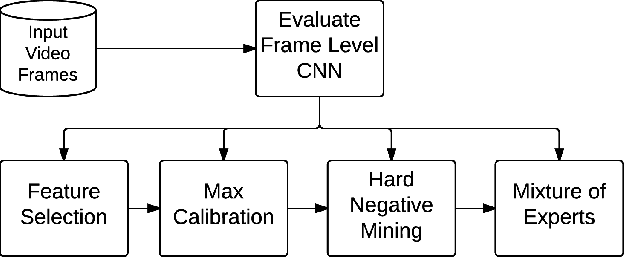



Video classification has advanced tremendously over the recent years. A large part of the improvements in video classification had to do with the work done by the image classification community and the use of deep convolutional networks (CNNs) which produce competitive results with hand- crafted motion features. These networks were adapted to use video frames in various ways and have yielded state of the art classification results. We present two methods that build on this work, and scale it up to work with millions of videos and hundreds of thousands of classes while maintaining a low computational cost. In the context of large scale video processing, training CNNs on video frames is extremely time consuming, due to the large number of frames involved. We propose to avoid this problem by training CNNs on either YouTube thumbnails or Flickr images, and then using these networks' outputs as features for other higher level classifiers. We discuss the challenges of achieving this and propose two models for frame-level and video-level classification. The first is a highly efficient mixture of experts while the latter is based on long short term memory neural networks. We present results on the Sports-1M video dataset (1 million videos, 487 classes) and on a new dataset which has 12 million videos and 150,000 labels.