 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Corner Case Generation for Autonomous Vehicles with Multimodal Large Language Model
Nov 29, 2024


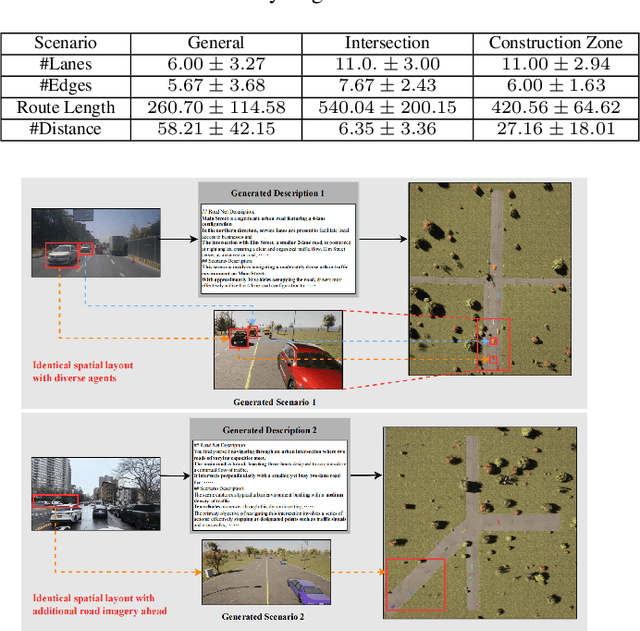
To guarantee the safety and reliability of autonomous vehicle (AV) systems, corner cases play a crucial role in exploring the system's behavior under rare and challenging conditions within simulation environments. However, current approaches often fall short in meeting diverse testing needs and struggle to generalize to novel, high-risk scenarios that closely mirror real-world conditions. To tackle this challenge, we present AutoScenario, a multimodal Large Language Model (LLM)-based framework for realistic corner case generation. It converts safety-critical real-world data from multiple sources into textual representations, enabling the generalization of key risk factors while leveraging the extensive world knowledge and advanced reasoning capabilities of LLMs.Furthermore, it integrates tools from the Simulation of Urban Mobility (SUMO) and CARLA simulators to simplify and execute the code generated by LLMs. Our experiments demonstrate that AutoScenario can generate realistic and challenging test scenarios, precisely tailored to specific testing requirements or textual descriptions. Additionally, we validated its ability to produce diverse and novel scenarios derived from multimodal real-world data involving risky situations, harnessing the powerful generalization capabilities of LLMs to effectively simulate a wide range of corner cases.
Multimodal Large Language Model Driven Scenario Testing for Autonomous Vehicles
Sep 10, 2024The generation of corner cases has become increasingly crucial for efficiently testing autonomous vehicles prior to road deployment. However, existing methods struggle to accommodate diverse testing requirements and often lack the ability to generalize to unseen situations, thereby reducing the convenience and usability of the generated scenarios. A method that facilitates easily controllable scenario generation for efficient autonomous vehicles (AV) testing with realistic and challenging situations is greatly needed. To address this, we proposed OmniTester: a multimodal Large Language Model (LLM) based framework that fully leverages the extensive world knowledge and reasoning capabilities of LLMs. OmniTester is designed to generate realistic and diverse scenarios within a simulation environment, offering a robust solution for testing and evaluating AVs. In addition to prompt engineering, we employ tools from Simulation of Urban Mobility to simplify the complexity of codes generated by LLMs. Furthermore, we incorporate Retrieval-Augmented Generation and a self-improvement mechanism to enhance the LLM's understanding of scenarios, thereby increasing its ability to produce more realistic scenes. In the experiments, we demonstrated the controllability and realism of our approaches in generating three types of challenging and complex scenarios. Additionally, we showcased its effectiveness in reconstructing new scenarios described in crash report, driven by the generalization capability of LLMs.
Accurately Predicting Probabilities of Safety-Critical Rare Events for Intelligent Systems
Mar 22, 2024



Intelligent systems are increasingly integral to our daily lives, yet rare safety-critical events present significant latent threats to their practical deployment. Addressing this challenge hinges on accurately predicting the probability of safety-critical events occurring within a given time step from the current state, a metric we define as 'criticality'. The complexity of predicting criticality arises from the extreme data imbalance caused by rare events in high dimensional variables associated with the rare events, a challenge we refer to as the curse of rarity. Existing methods tend to be either overly conservative or prone to overlooking safety-critical events, thus struggling to achieve both high precision and recall rates, which severely limits their applicability. This study endeavors to develop a criticality prediction model that excels in both precision and recall rates for evaluating the criticality of safety-critical autonomous systems. We propose a multi-stage learning framework designed to progressively densify the dataset, mitigating the curse of rarity across stages. To validate our approach, we evaluate it in two cases: lunar lander and bipedal walker scenarios. The results demonstrate that our method surpasses traditional approaches, providing a more accurate and dependable assessment of criticality in intelligent systems.
Action-conditioned On-demand Motion Generation
Jul 17, 2022



We propose a novel framework, On-Demand MOtion Generation (ODMO), for generating realistic and diverse long-term 3D human motion sequences conditioned only on action types with an additional capability of customization. ODMO shows improvements over SOTA approaches on all traditional motion evaluation metrics when evaluated on three public datasets (HumanAct12, UESTC, and MoCap). Furthermore, we provide both qualitative evaluations and quantitative metrics demonstrating several first-known customization capabilities afforded by our framework, including mode discovery, interpolation, and trajectory customization. These capabilities significantly widen the spectrum of potential applications of such motion generation models. The novel on-demand generative capabilities are enabled by innovations in both the encoder and decoder architectures: (i) Encoder: Utilizing contrastive learning in low-dimensional latent space to create a hierarchical embedding of motion sequences, where not only the codes of different action types form different groups, but within an action type, codes of similar inherent patterns (motion styles) cluster together, making them readily discoverable; (ii) Decoder: Using a hierarchical decoding strategy where the motion trajectory is reconstructed first and then used to reconstruct the whole motion sequence. Such an architecture enables effective trajectory control. Our code is released on the Github page: https://github.com/roychowdhuryresearch/ODMO
KEMP: Keyframe-Based Hierarchical End-to-End Deep Model for Long-Term Trajectory Prediction
May 10, 2022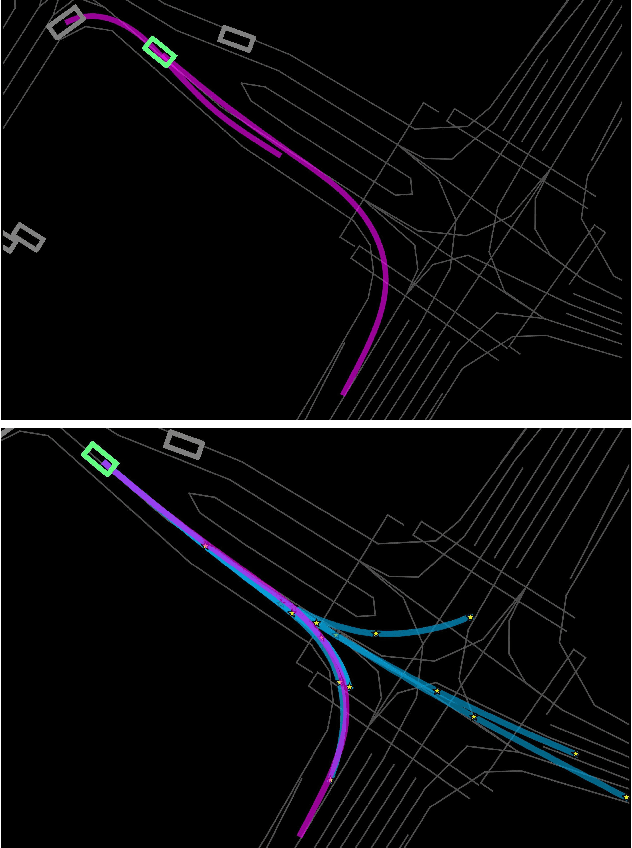
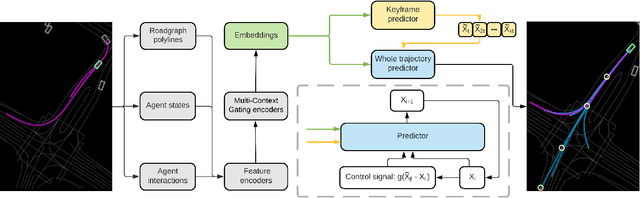
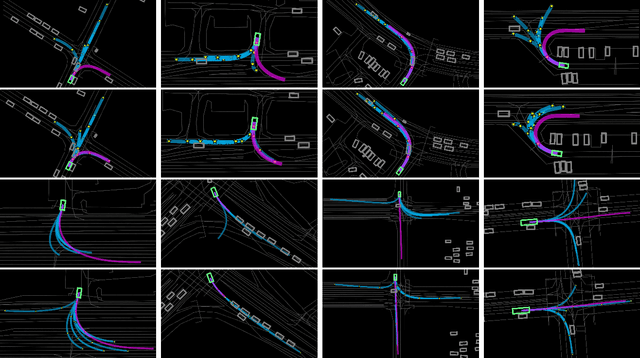
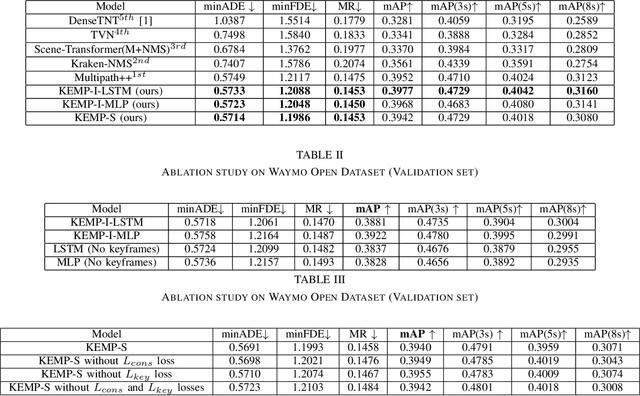
Predicting future trajectories of road agents is a critical task for autonomous driving. Recent goal-based trajectory prediction methods, such as DenseTNT and PECNet, have shown good performance on prediction tasks on public datasets. However, they usually require complicated goal-selection algorithms and optimization. In this work, we propose KEMP, a hierarchical end-to-end deep learning framework for trajectory prediction. At the core of our framework is keyframe-based trajectory prediction, where keyframes are representative states that trace out the general direction of the trajectory. KEMP first predicts keyframes conditioned on the road context, and then fills in intermediate states conditioned on the keyframes and the road context. Under our general framework, goal-conditioned methods are special cases in which the number of keyframes equal to one. Unlike goal-conditioned methods, our keyframe predictor is learned automatically and does not require hand-crafted goal-selection algorithms. We evaluate our model on public benchmarks and our model ranked 1st on Waymo Open Motion Dataset Leaderboard (as of September 1, 2021).
Diverse Imitation Learning via Self-Organizing Generative Models
May 06, 2022



Imitation learning is the task of replicating expert policy from demonstrations, without access to a reward function. This task becomes particularly challenging when the expert exhibits a mixture of behaviors. Prior work has introduced latent variables to model variations of the expert policy. However, our experiments show that the existing works do not exhibit appropriate imitation of individual modes. To tackle this problem, we adopt an encoder-free generative model for behavior cloning (BC) to accurately distinguish and imitate different modes. Then, we integrate it with GAIL to make the learning robust towards compounding errors at unseen states. We show that our method significantly outperforms the state of the art across multiple experiments.