 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Behavior of Discrete Diffusion Language Models
Dec 11, 2025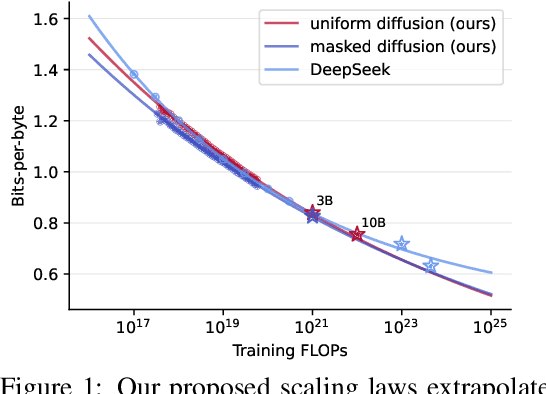
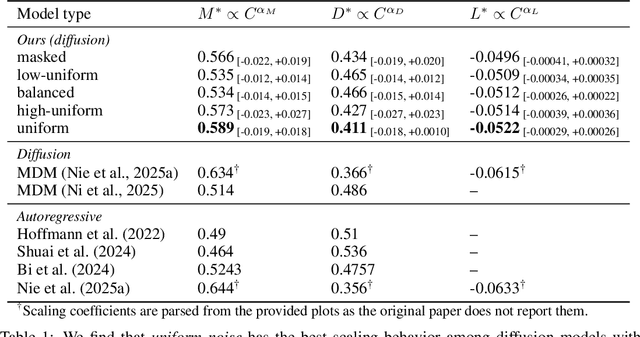
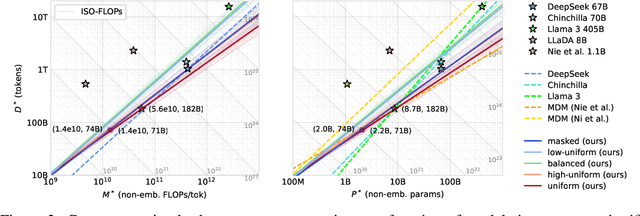
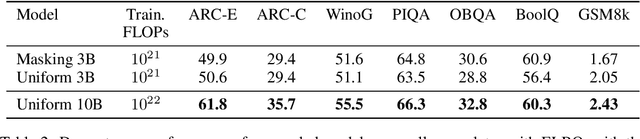
Modern LLM pre-training consumes vast amounts of compute and training data, making the scaling behavior, or scaling laws, of different models a key distinguishing factor. Discrete diffusion language models (DLMs) have been proposed as an alternative to autoregressive language models (ALMs). However, their scaling behavior has not yet been fully explored, with prior work suggesting that they require more data and compute to match the performance of ALMs. We study the scaling behavior of DLMs on different noise types by smoothly interpolating between masked and uniform diffusion while paying close attention to crucial hyperparameters such as batch size and learning rate. Our experiments reveal that the scaling behavior of DLMs strongly depends on the noise type and is considerably different from ALMs. While all noise types converge to similar loss values in compute-bound scaling, we find that uniform diffusion requires more parameters and less data for compute-efficient training compared to masked diffusion, making them a promising candidate in data-bound settings. We scale our uniform diffusion model up to 10B parameters trained for $10^{22}$ FLOPs, confirming the predicted scaling behavior and making it the largest publicly known uniform diffusion model to date.
PureEBM: Universal Poison Purification via Mid-Run Dynamics of Energy-Based Models
Jun 02, 2024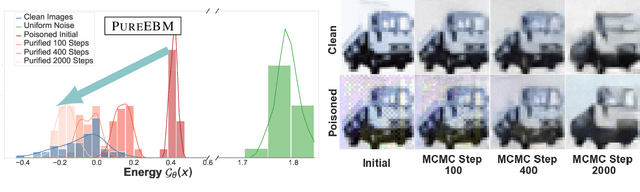
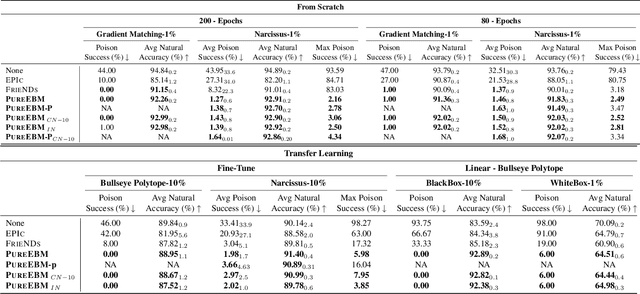
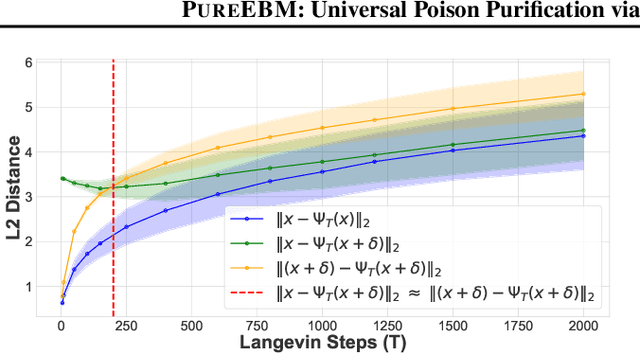
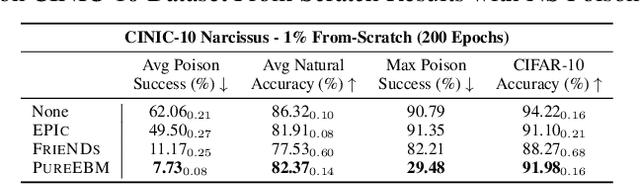
Data poisoning attacks pose a significant threat to the integrity of machine learning models by leading to misclassification of target distribution data by injecting adversarial examples during training. Existing state-of-the-art (SoTA) defense methods suffer from limitations, such as significantly reduced generalization performance and significant overhead during training, making them impractical or limited for real-world applications. In response to this challenge, we introduce a universal data purification method that defends naturally trained classifiers from malicious white-, gray-, and black-box image poisons by applying a universal stochastic preprocessing step $\Psi_{T}(x)$, realized by iterative Langevin sampling of a convergent Energy Based Model (EBM) initialized with an image $x.$ Mid-run dynamics of $\Psi_{T}(x)$ purify poison information with minimal impact on features important to the generalization of a classifier network. We show that EBMs remain universal purifiers, even in the presence of poisoned EBM training data, and achieve SoTA defense on leading triggered and triggerless poisons. This work is a subset of a larger framework introduced in \pgen with a more detailed focus on EBM purification and poison defense.
PureGen: Universal Data Purification for Train-Time Poison Defense via Generative Model Dynamics
May 28, 2024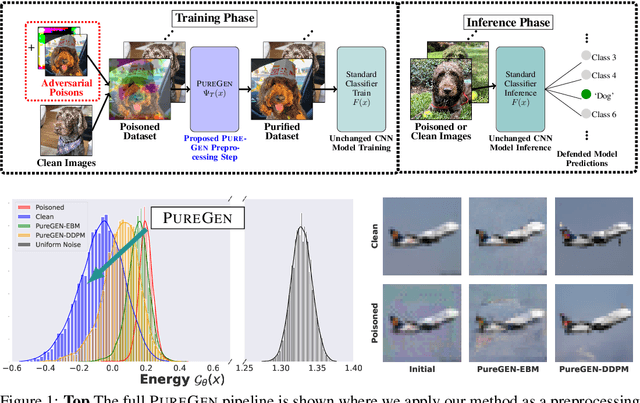
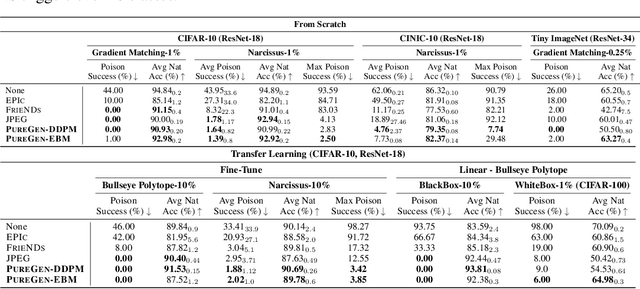
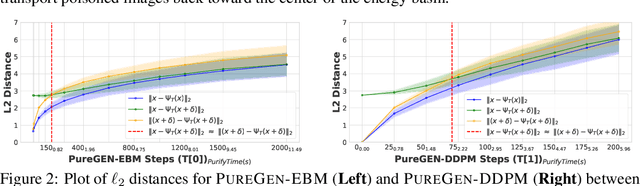
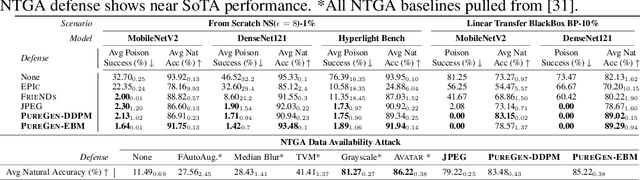
Train-time data poisoning attacks threaten machine learning models by introducing adversarial examples during training, leading to misclassification. Current defense methods often reduce generalization performance, are attack-specific, and impose significant training overhead. To address this, we introduce a set of universal data purification methods using a stochastic transform, $\Psi(x)$, realized via iterative Langevin dynamics of Energy-Based Models (EBMs), Denoising Diffusion Probabilistic Models (DDPMs), or both. These approaches purify poisoned data with minimal impact on classifier generalization. Our specially trained EBMs and DDPMs provide state-of-the-art defense against various attacks (including Narcissus, Bullseye Polytope, Gradient Matching) on CIFAR-10, Tiny-ImageNet, and CINIC-10, without needing attack or classifier-specific information. We discuss performance trade-offs and show that our methods remain highly effective even with poisoned or distributionally shifted generative model training data.
Curvature-Informed SGD via General Purpose Lie-Group Preconditioners
Feb 07, 2024We present a novel approach to accelerate stochastic gradient descent (SGD) by utilizing curvature information obtained from Hessian-vector products or finite differences of parameters and gradients, similar to the BFGS algorithm. Our approach involves two preconditioners: a matrix-free preconditioner and a low-rank approximation preconditioner. We update both preconditioners online using a criterion that is robust to stochastic gradient noise and does not require line search or damping. To preserve the corresponding symmetry or invariance, our preconditioners are constrained to certain connected Lie groups. The Lie group's equivariance property simplifies the preconditioner fitting process, while its invariance property eliminates the need for damping, which is commonly required in second-order optimizers. As a result, the learning rate for parameter updating and the step size for preconditioner fitting are naturally normalized, and their default values work well in most scenarios. Our proposed approach offers a promising direction for improving the convergence of SGD with low computational overhead. We demonstrate that Preconditioned SGD (PSGD) outperforms SoTA on Vision, NLP, and RL tasks across multiple modern deep-learning architectures. We have provided code for reproducing toy and large scale experiments in this paper.
Towards Composable Distributions of Latent Space Augmentations
Mar 06, 2023We propose a composable framework for latent space image augmentation that allows for easy combination of multiple augmentations. Image augmentation has been shown to be an effective technique for improving the performance of a wide variety of image classification and generation tasks. Our framework is based on the Variational Autoencoder architecture and uses a novel approach for augmentation via linear transformation within the latent space itself. We explore losses and augmentation latent geometry to enforce the transformations to be composable and involuntary, thus allowing the transformations to be readily combined or inverted. Finally, we show these properties are better performing with certain pairs of augmentations, but we can transfer the latent space to other sets of augmentations to modify performance, effectively constraining the VAE's bottleneck to preserve the variance of specific augmentations and features of the image which we care about. We demonstrate the effectiveness of our approach with initial results on the MNIST dataset against both a standard VAE and a Conditional VAE. This latent augmentation method allows for much greater control and geometric interpretability of the latent space, making it a valuable tool for researchers and practitioners in the field.
Generating High Fidelity Synthetic Data via Coreset selection and Entropic Regularization
Jan 31, 2023


Generative models have the ability to synthesize data points drawn from the data distribution, however, not all generated samples are high quality. In this paper, we propose using a combination of coresets selection methods and ``entropic regularization'' to select the highest fidelity samples. We leverage an Energy-Based Model which resembles a variational auto-encoder with an inference and generator model for which the latent prior is complexified by an energy-based model. In a semi-supervised learning scenario, we show that augmenting the labeled data-set, by adding our selected subset of samples, leads to better accuracy improvement rather than using all the synthetic samples.
Improving Levenberg-Marquardt Algorithm for Neural Networks
Dec 17, 2022



We explore the usage of the Levenberg-Marquardt (LM) algorithm for regression (non-linear least squares) and classification (generalized Gauss-Newton methods) tasks in neural networks. We compare the performance of the LM method with other popular first-order algorithms such as SGD and Adam, as well as other second-order algorithms such as L-BFGS , Hessian-Free and KFAC. We further speed up the LM method by using adaptive momentum, learning rate line search, and uphill step acceptance.
Hypothesis Testing using Causal and Causal Variational Generative Models
Oct 20, 2022
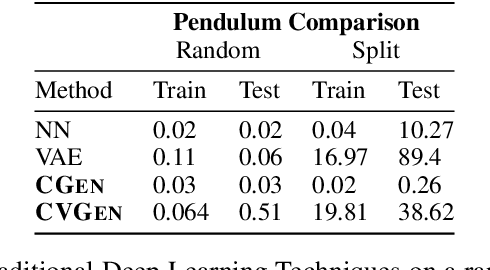

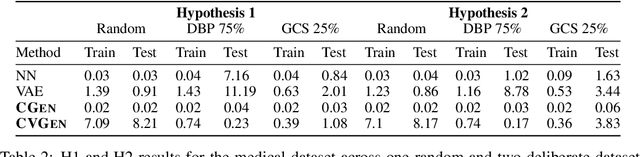
Hypothesis testing and the usage of expert knowledge, or causal priors, has not been well explored in the context of generative models. We propose a novel set of generative architectures, Causal Gen and Causal Variational Gen, that can utilize nonparametric structural causal knowledge combined with a deep learning functional approximation. We show how, using a deliberate (non-random) split of training and testing data, these models can generalize better to similar, but out-of-distribution data points, than non-causal generative models and prediction models such as Variational autoencoders and Fully Connected Neural Networks. We explore using this generalization error as a proxy for causal model hypothesis testing. We further show how dropout can be used to learn functional relationships of structural models that are difficult to learn with traditional methods. We validate our methods on a synthetic pendulum dataset, as well as a trauma surgery ground level fall dataset.
Adaptive Second Order Coresets for Data-efficient Machine Learning
Jul 28, 2022



Training machine learning models on massive datasets incurs substantial computational costs. To alleviate such costs, there has been a sustained effort to develop data-efficient training methods that can carefully select subsets of the training examples that generalize on par with the full training data. However, existing methods are limited in providing theoretical guarantees for the quality of the models trained on the extracted subsets, and may perform poorly in practice. We propose AdaCore, a method that leverages the geometry of the data to extract subsets of the training examples for efficient machine learning. The key idea behind our method is to dynamically approximate the curvature of the loss function via an exponentially-averaged estimate of the Hessian to select weighted subsets (coresets) that provide a close approximation of the full gradient preconditioned with the Hessian. We prove rigorous guarantees for the convergence of various first and second-order methods applied to the subsets chosen by AdaCore. Our extensive experiments show that AdaCore extracts coresets with higher quality compared to baselines and speeds up training of convex and non-convex machine learning models, such as logistic regression and neural networks, by over 2.9x over the full data and 4.5x over random subsets.
De-Biasing Generative Models using Counterfactual Methods
Jul 05, 2022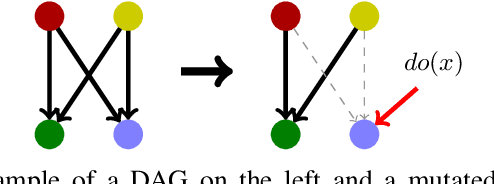

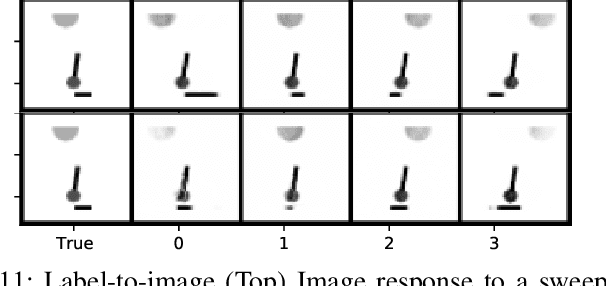
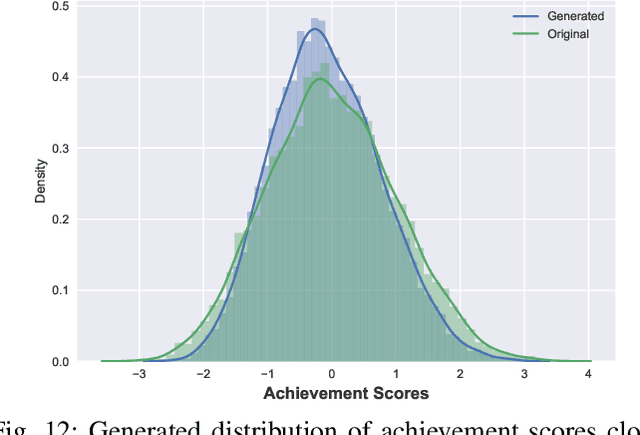
Variational autoencoders (VAEs) and other generative methods have garnered growing interest not just for their generative properties but also for the ability to dis-entangle a low-dimensional latent variable space. However, few existing generative models take causality into account. We propose a new decoder based framework named the Causal Counterfactual Generative Model (CCGM), which includes a partially trainable causal layer in which a part of a causal model can be learned without significantly impacting reconstruction fidelity. By learning the causal relationships between image semantic labels or tabular variables, we can analyze biases, intervene on the generative model, and simulate new scenarios. Furthermore, by modifying the causal structure, we can generate samples outside the domain of the original training data and use such counterfactual models to de-bias datasets. Thus, datasets with known biases can still be used to train the causal generative model and learn the causal relationships, but we can produce de-biased datasets on the generative side. Our proposed method combines a causal latent space VAE model with specific modification to emphasize causal fidelity, enabling finer control over the causal layer and the ability to learn a robust intervention framework. We explore how better disentanglement of causal learning and encoding/decoding generates higher causal intervention quality. We also compare our model against similar research to demonstrate the need for explicit generative de-biasing beyond interventions. Our initial experiments show that our model can generate images and tabular data with high fidelity to the causal framework and accommodate explicit de-biasing to ignore undesired relationships in the causal data compared to the baseline.