 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating High Fidelity Synthetic Data via Coreset selection and Entropic Regularization
Jan 31, 2023


Generative models have the ability to synthesize data points drawn from the data distribution, however, not all generated samples are high quality. In this paper, we propose using a combination of coresets selection methods and ``entropic regularization'' to select the highest fidelity samples. We leverage an Energy-Based Model which resembles a variational auto-encoder with an inference and generator model for which the latent prior is complexified by an energy-based model. In a semi-supervised learning scenario, we show that augmenting the labeled data-set, by adding our selected subset of samples, leads to better accuracy improvement rather than using all the synthetic samples.
Sales Channel Optimization via Simulations Based on Observational Data with Delayed Rewards: A Case Study at LinkedIn
Sep 16, 2022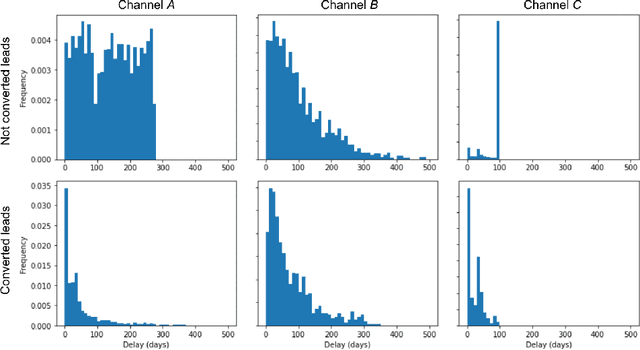
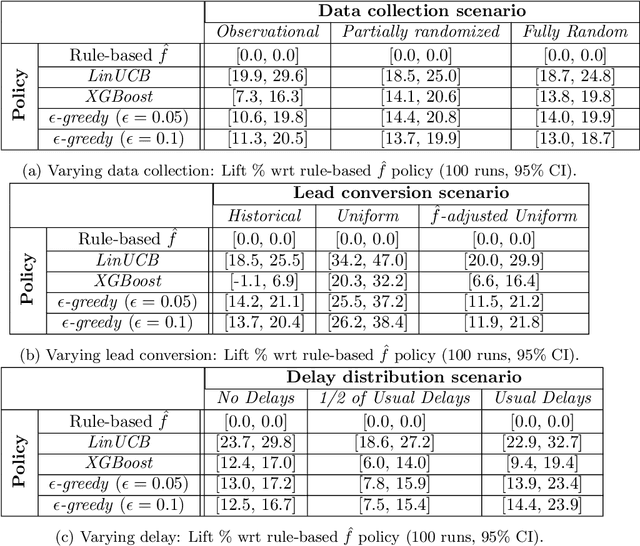
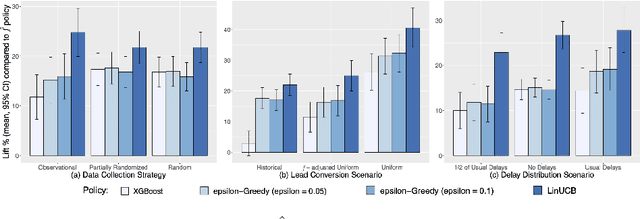
Training models on data obtained from randomized experiments is ideal for making good decisions. However, randomized experiments are often time-consuming, expensive, risky, infeasible or unethical to perform, leaving decision makers little choice but to rely on observational data collected under historical policies when training models. This opens questions regarding not only which decision-making policies would perform best in practice, but also regarding the impact of different data collection protocols on the performance of various policies trained on the data, or the robustness of policy performance with respect to changes in problem characteristics such as action- or reward- specific delays in observing outcomes. We aim to answer such questions for the problem of optimizing sales channel allocations at LinkedIn, where sales accounts (leads) need to be allocated to one of three channels, with the goal of maximizing the number of successful conversions over a period of time. A key problem feature constitutes the presence of stochastic delays in observing allocation outcomes, whose distribution is both channel- and outcome- dependent. We built a discrete-time simulation that can handle our problem features and used it to evaluate: a) a historical rule-based policy; b) a supervised machine learning policy (XGBoost); and c) multi-armed bandit (MAB) policies, under different scenarios involving: i) data collection used for training (observational vs randomized); ii) lead conversion scenarios; iii) delay distributions. Our simulation results indicate that LinUCB, a simple MAB policy, consistently outperforms the other policies, achieving a 18-47% lift relative to a rule-based policy
Probabilistic Sufficient Explanations
May 21, 2021


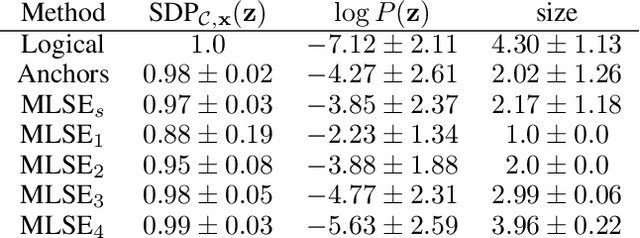
Understanding the behavior of learned classifiers is an important task, and various black-box explanations, logical reasoning approaches, and model-specific methods have been proposed. In this paper, we introduce probabilistic sufficient explanations, which formulate explaining an instance of classification as choosing the "simplest" subset of features such that only observing those features is "sufficient" to explain the classification. That is, sufficient to give us strong probabilistic guarantees that the model will behave similarly when all features are observed under the data distribution. In addition, we leverage tractable probabilistic reasoning tools such as probabilistic circuits and expected predictions to design a scalable algorithm for finding the desired explanations while keeping the guarantees intact. Our experiments demonstrate the effectiveness of our algorithm in finding sufficient explanations, and showcase its advantages compared to Anchors and logical explanations.
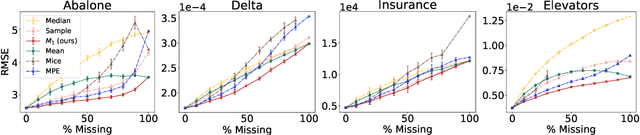
Handling Missing Data in Decision Trees: A Probabilistic Approach
Jun 29, 2020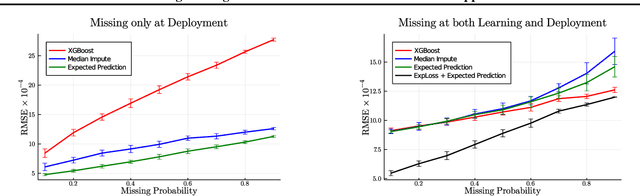

Decision trees are a popular family of models due to their attractive properties such as interpretability and ability to handle heterogeneous data. Concurrently, missing data is a prevalent occurrence that hinders performance of machine learning models. As such, handling missing data in decision trees is a well studied problem. In this paper, we tackle this problem by taking a probabilistic approach. At deployment time, we use tractable density estimators to compute the "expected prediction" of our models. At learning time, we fine-tune parameters of already learned trees by minimizing their "expected prediction loss" w.r.t.\ our density estimators. We provide brief experiments showcasing effectiveness of our methods compared to few baselines.
On Tractable Computation of Expected Predictions
Oct 31, 2019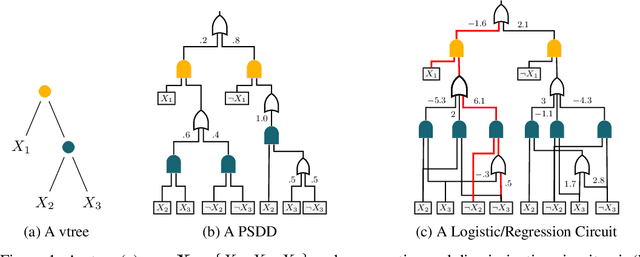
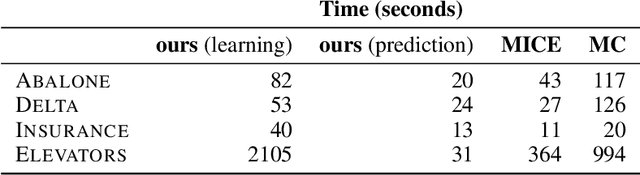
Computing expected predictions of discriminative models is a fundamental task in machine learning that appears in many interesting applications such as fairness, handling missing values, and data analysis. Unfortunately, computing expectations of a discriminative model with respect to a probability distribution defined by an arbitrary generative model has been proven to be hard in general. In fact, the task is intractable even for simple models such as logistic regression and a naive Bayes distribution. In this paper, we identify a pair of generative and discriminative models that enables tractable computation of expectations, as well as moments of any order, of the latter with respect to the former in case of regression. Specifically, we consider expressive probabilistic circuits with certain structural constraints that support tractable probabilistic inference. Moreover, we exploit the tractable computation of high-order moments to derive an algorithm to approximate the expectations for classification scenarios in which exact computations are intractable. Our framework to compute expected predictions allows for handling of missing data during prediction time in a principled and accurate way and enables reasoning about the behavior of discriminative models. We empirically show our algorithm to consistently outperform standard imputation techniques on a variety of datasets. Finally, we illustrate how our framework can be used for exploratory data analysis.
What to Expect of Classifiers? Reasoning about Logistic Regression with Missing Features
Mar 05, 2019
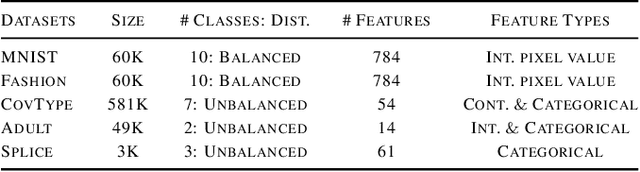


While discriminative classifiers often yield strong predictive performance, missing feature values at prediction time can still be a challenge. Classifiers may not behave as expected under certain ways of substituting the missing values, since they inherently make assumptions about the data distribution they were trained on. In this paper, we propose a novel framework that classifies examples with missing features by computing the expected prediction on a given feature distribution. We then use geometric programming to learn a naive Bayes distribution that embeds a given logistic regression classifier and can efficiently take its expected predictions. Empirical evaluations show that our model achieves the same performance as the logistic regression with all features observed, and outperforms standard imputation techniques when features go missing during prediction time. Furthermore, we demonstrate that our method can be used to generate 'sufficient explanations' of logistic regression classifications, by removing features that do not affect the classification.