 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpsilon*: Privacy Metric for Machine Learning Models
Jul 21, 2023



We introduce Epsilon*, a new privacy metric for measuring the privacy risk of a single model instance prior to, during, or after deployment of privacy mitigation strategies. The metric does not require access to the training data sampling or model training algorithm. Epsilon* is a function of true positive and false positive rates in a hypothesis test used by an adversary in a membership inference attack. We distinguish between quantifying the privacy loss of a trained model instance and quantifying the privacy loss of the training mechanism which produces this model instance. Existing approaches in the privacy auditing literature provide lower bounds for the latter, while our metric provides a lower bound for the former by relying on an (${\epsilon}$,${\delta}$)-type of quantification of the privacy of the trained model instance. We establish a relationship between these lower bounds and show how to implement Epsilon* to avoid numerical and noise amplification instability. We further show in experiments on benchmark public data sets that Epsilon* is sensitive to privacy risk mitigation by training with differential privacy (DP), where the value of Epsilon* is reduced by up to 800% compared to the Epsilon* values of non-DP trained baseline models. This metric allows privacy auditors to be independent of model owners, and enables all decision-makers to visualize the privacy-utility landscape to make informed decisions regarding the trade-offs between model privacy and utility.
Sales Channel Optimization via Simulations Based on Observational Data with Delayed Rewards: A Case Study at LinkedIn
Sep 16, 2022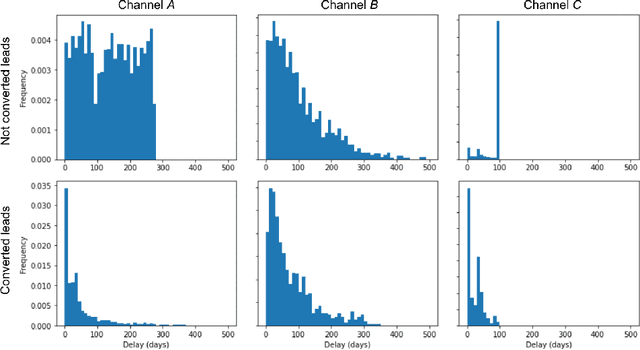
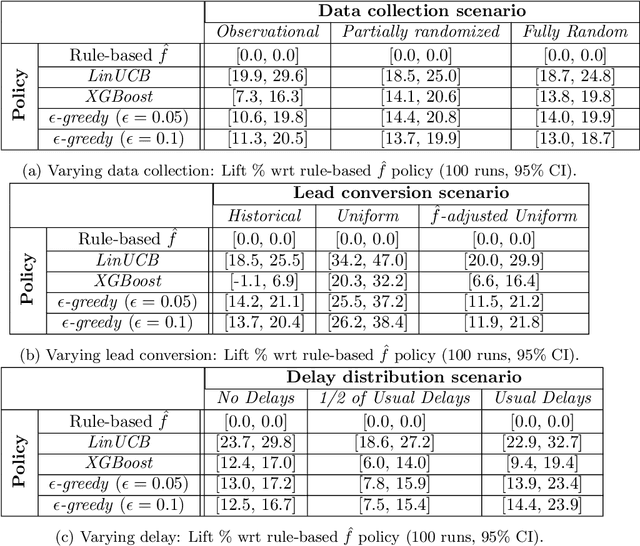
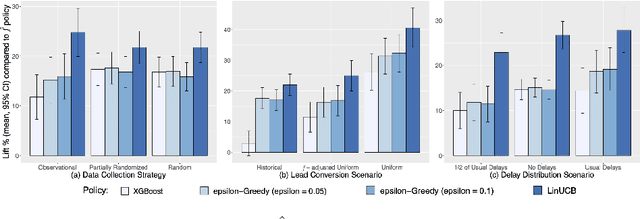
Training models on data obtained from randomized experiments is ideal for making good decisions. However, randomized experiments are often time-consuming, expensive, risky, infeasible or unethical to perform, leaving decision makers little choice but to rely on observational data collected under historical policies when training models. This opens questions regarding not only which decision-making policies would perform best in practice, but also regarding the impact of different data collection protocols on the performance of various policies trained on the data, or the robustness of policy performance with respect to changes in problem characteristics such as action- or reward- specific delays in observing outcomes. We aim to answer such questions for the problem of optimizing sales channel allocations at LinkedIn, where sales accounts (leads) need to be allocated to one of three channels, with the goal of maximizing the number of successful conversions over a period of time. A key problem feature constitutes the presence of stochastic delays in observing allocation outcomes, whose distribution is both channel- and outcome- dependent. We built a discrete-time simulation that can handle our problem features and used it to evaluate: a) a historical rule-based policy; b) a supervised machine learning policy (XGBoost); and c) multi-armed bandit (MAB) policies, under different scenarios involving: i) data collection used for training (observational vs randomized); ii) lead conversion scenarios; iii) delay distributions. Our simulation results indicate that LinUCB, a simple MAB policy, consistently outperforms the other policies, achieving a 18-47% lift relative to a rule-based policy
Greykite: Deploying Flexible Forecasting at Scale at LinkedIn
Jul 15, 2022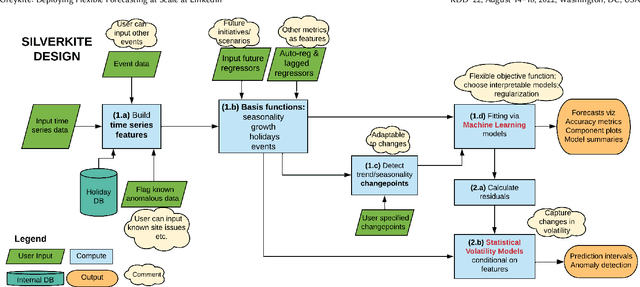
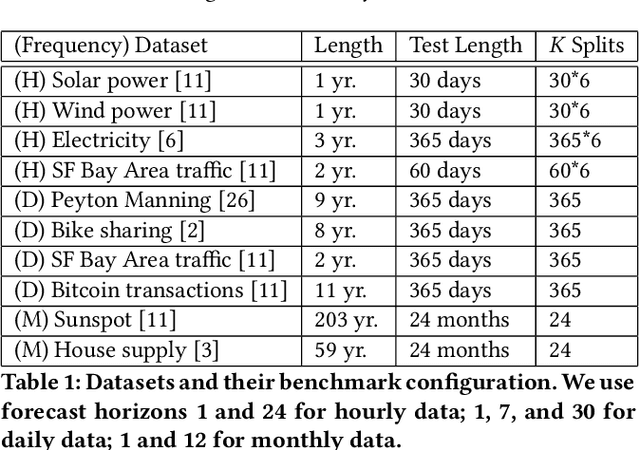
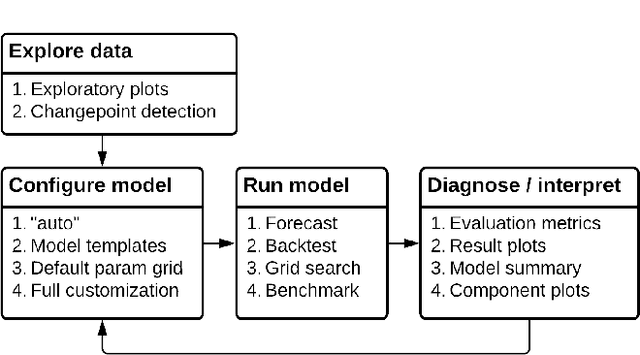
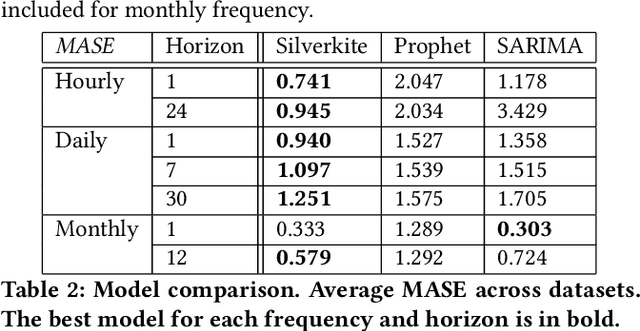
Forecasts help businesses allocate resources and achieve objectives. At LinkedIn, product owners use forecasts to set business targets, track outlook, and monitor health. Engineers use forecasts to efficiently provision hardware. Developing a forecasting solution to meet these needs requires accurate and interpretable forecasts on diverse time series with sub-hourly to quarterly frequencies. We present Greykite, an open-source Python library for forecasting that has been deployed on over twenty use cases at LinkedIn. Its flagship algorithm, Silverkite, provides interpretable, fast, and highly flexible univariate forecasts that capture effects such as time-varying growth and seasonality, autocorrelation, holidays, and regressors. The library enables self-serve accuracy and trust by facilitating data exploration, model configuration, execution, and interpretation. Our benchmark results show excellent out-of-the-box speed and accuracy on datasets from a variety of domains. Over the past two years, Greykite forecasts have been trusted by Finance, Engineering, and Product teams for resource planning and allocation, target setting and progress tracking, anomaly detection and root cause analysis. We expect Greykite to be useful to forecast practitioners with similar applications who need accurate, interpretable forecasts that capture complex dynamics common to time series related to human activity.
Intellige: A User-Facing Model Explainer for Narrative Explanations
May 27, 2021
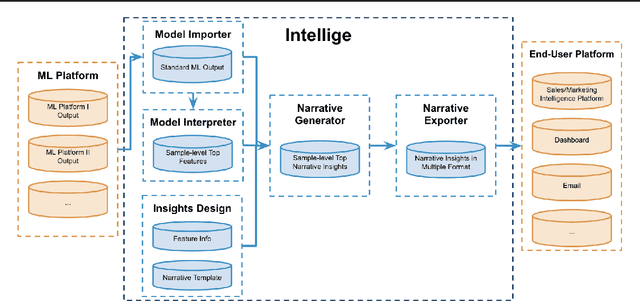

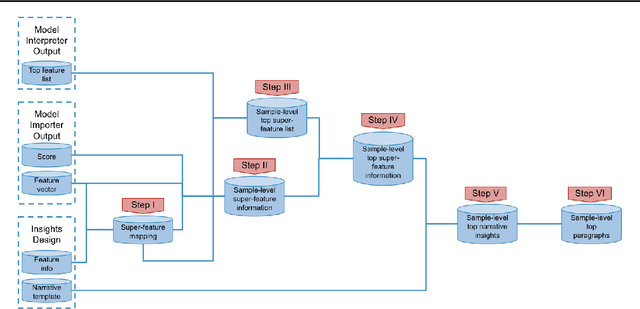
Predictive machine learning models often lack interpretability, resulting in low trust from model end users despite having high predictive performance. While many model interpretation approaches return top important features to help interpret model predictions, these top features may not be well-organized or intuitive to end users, which limits model adoption rates. In this paper, we propose Intellige, a user-facing model explainer that creates user-digestible interpretations and insights reflecting the rationale behind model predictions. Intellige builds an end-to-end pipeline from machine learning platforms to end user platforms, and provides users with an interface for implementing model interpretation approaches and for customizing narrative insights. Intellige is a platform consisting of four components: Model Importer, Model Interpreter, Narrative Generator, and Narrative Exporter. We describe these components, and then demonstrate the effectiveness of Intellige through use cases at LinkedIn. Quantitative performance analyses indicate that Intellige's narrative insights lead to lifts in adoption rates of predictive model recommendations, as well as to increases in downstream key metrics such as revenue when compared to previous approaches, while qualitative analyses indicate positive feedback from end users.
MCA-based Rule Mining Enables Interpretable Inference in Clinical Psychiatry
Oct 26, 2018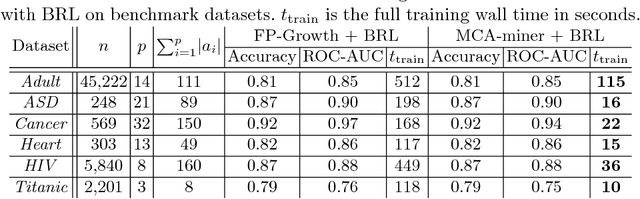
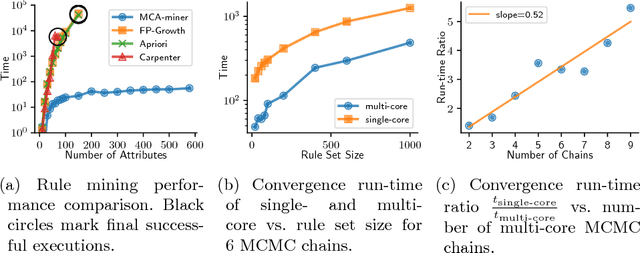
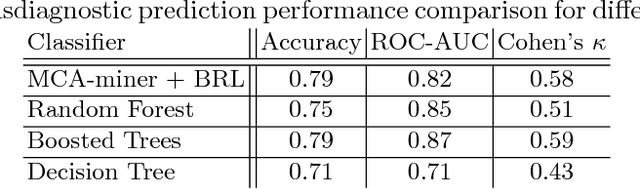
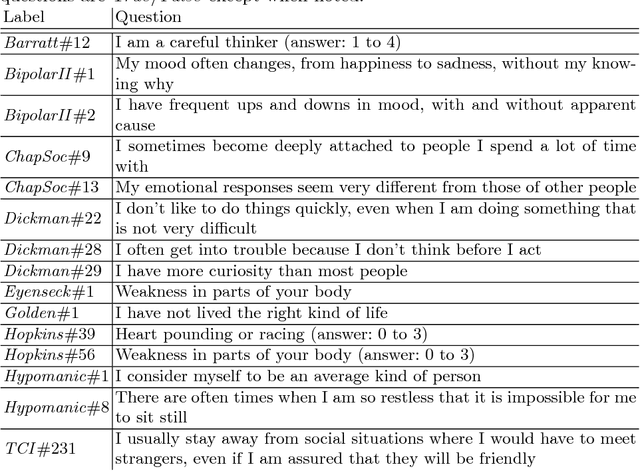
Development of interpretable machine learning models for clinical healthcare applications has the potential of changing the way we understand, treat, and ultimately cure, diseases and disorders in many areas of medicine. Interpretable ML models for clinical healthcare can serve not only as sources of predictions and estimates, but also as discovery tools for clinicians and researchers to reveal new knowledge from the data. High dimensionality of patient information (e.g., phenotype, genotype, and medical history), lack of objective measurements, and the heterogeneity in patient populations often create significant challenges in developing interpretable machine learning models for clinical psychiatry in practice. In this paper we take a step towards the development of such interpretable models. First, by developing a novel categorical rule mining method based on Multivariate Correspondence Analysis (MCA) capable of handling datasets with large numbers of feature categories, and second, by applying this method to build a transdiagnostic Bayesian Rule List model to screen for neuropsychiatric disorders using Consortium for Neuropsychiatric Phenomics dataset. We show that our method is not only at least 100 times faster than state-of-the-art rule mining techniques for datasets with 50 features, but also provides interpretability and comparable prediction accuracy across several benchmark datasets.
SoK: Applying Machine Learning in Security - A Survey
Nov 10, 2016
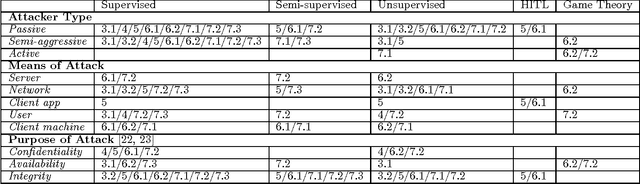
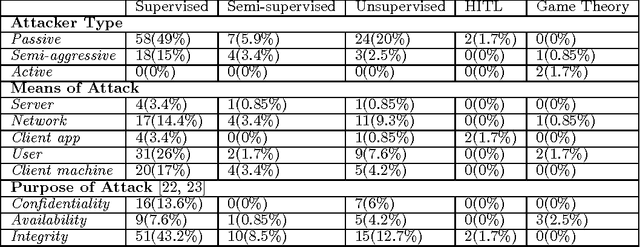

The idea of applying machine learning(ML) to solve problems in security domains is almost 3 decades old. As information and communications grow more ubiquitous and more data become available, many security risks arise as well as appetite to manage and mitigate such risks. Consequently, research on applying and designing ML algorithms and systems for security has grown fast, ranging from intrusion detection systems(IDS) and malware classification to security policy management(SPM) and information leak checking. In this paper, we systematically study the methods, algorithms, and system designs in academic publications from 2008-2015 that applied ML in security domains. 98 percent of the surveyed papers appeared in the 6 highest-ranked academic security conferences and 1 conference known for pioneering ML applications in security. We examine the generalized system designs, underlying assumptions, measurements, and use cases in active research. Our examinations lead to 1) a taxonomy on ML paradigms and security domains for future exploration and exploitation, and 2) an agenda detailing open and upcoming challenges. Based on our survey, we also suggest a point of view that treats security as a game theory problem instead of a batch-trained ML problem.