 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalizable Method for Automated Quality Control of Functional Neuroimaging Datasets
Dec 20, 2019


Over the last twenty five years, advances in the collection and analysis of fMRI data have enabled new insights into the brain basis of human health and disease. Individual behavioral variation can now be visualized at a neural level as patterns of connectivity among brain regions. Functional brain imaging is enhancing our understanding of clinical psychiatric disorders by revealing ties between regional and network abnormalities and psychiatric symptoms. Initial success in this arena has recently motivated collection of larger datasets which are needed to leverage fMRI to generate brain-based biomarkers to support development of precision medicines. Despite methodological advances and enhanced computational power, evaluating the quality of fMRI scans remains a critical step in the analytical framework. Before analysis can be performed, expert reviewers visually inspect raw scans and preprocessed derivatives to determine viability of the data. This Quality Control (QC) process is labor intensive, and the inability to automate at large scale has proven to be a limiting factor in clinical neuroscience fMRI research. We present a novel method for automating the QC of fMRI scans. We train machine learning classifiers using features derived from brain MR images to predict the "quality" of those images, based on the ground truth of an expert's opinion. We emphasize the importance of these classifiers' ability to generalize their predictions across data from different studies. To address this, we propose a novel approach entitled "FMRI preprocessing Log mining for Automated, Generalizable Quality Control" (FLAG-QC), in which features derived from mining runtime logs are used to train the classifier. We show that classifiers trained on FLAG-QC features perform much better (AUC=0.79) than previously proposed feature sets (AUC=0.56) when testing their ability to generalize across studies.
MCA-based Rule Mining Enables Interpretable Inference in Clinical Psychiatry
Oct 26, 2018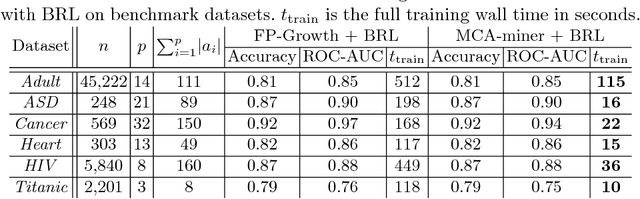
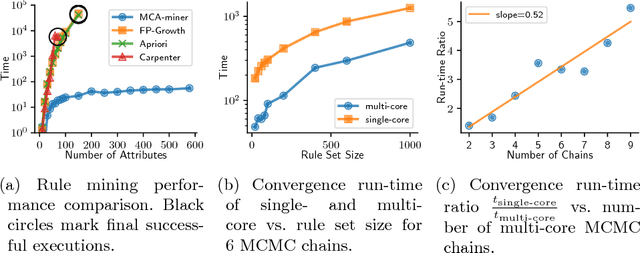
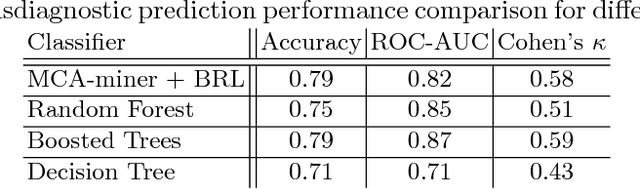
Development of interpretable machine learning models for clinical healthcare applications has the potential of changing the way we understand, treat, and ultimately cure, diseases and disorders in many areas of medicine. Interpretable ML models for clinical healthcare can serve not only as sources of predictions and estimates, but also as discovery tools for clinicians and researchers to reveal new knowledge from the data. High dimensionality of patient information (e.g., phenotype, genotype, and medical history), lack of objective measurements, and the heterogeneity in patient populations often create significant challenges in developing interpretable machine learning models for clinical psychiatry in practice. In this paper we take a step towards the development of such interpretable models. First, by developing a novel categorical rule mining method based on Multivariate Correspondence Analysis (MCA) capable of handling datasets with large numbers of feature categories, and second, by applying this method to build a transdiagnostic Bayesian Rule List model to screen for neuropsychiatric disorders using Consortium for Neuropsychiatric Phenomics dataset. We show that our method is not only at least 100 times faster than state-of-the-art rule mining techniques for datasets with 50 features, but also provides interpretability and comparable prediction accuracy across several benchmark datasets.