 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCA-based Rule Mining Enables Interpretable Inference in Clinical Psychiatry
Paper and Code
Oct 26, 2018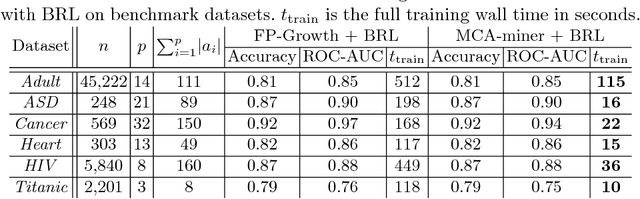
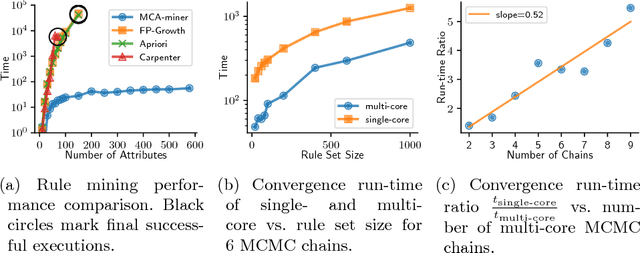
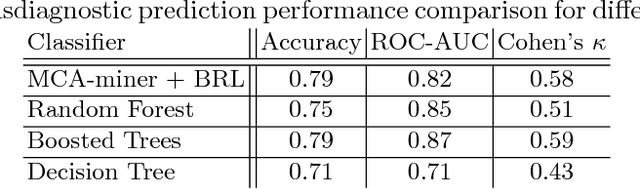
Development of interpretable machine learning models for clinical healthcare applications has the potential of changing the way we understand, treat, and ultimately cure, diseases and disorders in many areas of medicine. Interpretable ML models for clinical healthcare can serve not only as sources of predictions and estimates, but also as discovery tools for clinicians and researchers to reveal new knowledge from the data. High dimensionality of patient information (e.g., phenotype, genotype, and medical history), lack of objective measurements, and the heterogeneity in patient populations often create significant challenges in developing interpretable machine learning models for clinical psychiatry in practice. In this paper we take a step towards the development of such interpretable models. First, by developing a novel categorical rule mining method based on Multivariate Correspondence Analysis (MCA) capable of handling datasets with large numbers of feature categories, and second, by applying this method to build a transdiagnostic Bayesian Rule List model to screen for neuropsychiatric disorders using Consortium for Neuropsychiatric Phenomics dataset. We show that our method is not only at least 100 times faster than state-of-the-art rule mining techniques for datasets with 50 features, but also provides interpretability and comparable prediction accuracy across several benchmark datasets.