 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpsilon*: Privacy Metric for Machine Learning Models
Jul 21, 2023



We introduce Epsilon*, a new privacy metric for measuring the privacy risk of a single model instance prior to, during, or after deployment of privacy mitigation strategies. The metric does not require access to the training data sampling or model training algorithm. Epsilon* is a function of true positive and false positive rates in a hypothesis test used by an adversary in a membership inference attack. We distinguish between quantifying the privacy loss of a trained model instance and quantifying the privacy loss of the training mechanism which produces this model instance. Existing approaches in the privacy auditing literature provide lower bounds for the latter, while our metric provides a lower bound for the former by relying on an (${\epsilon}$,${\delta}$)-type of quantification of the privacy of the trained model instance. We establish a relationship between these lower bounds and show how to implement Epsilon* to avoid numerical and noise amplification instability. We further show in experiments on benchmark public data sets that Epsilon* is sensitive to privacy risk mitigation by training with differential privacy (DP), where the value of Epsilon* is reduced by up to 800% compared to the Epsilon* values of non-DP trained baseline models. This metric allows privacy auditors to be independent of model owners, and enables all decision-makers to visualize the privacy-utility landscape to make informed decisions regarding the trade-offs between model privacy and utility.
Sales Channel Optimization via Simulations Based on Observational Data with Delayed Rewards: A Case Study at LinkedIn
Sep 16, 2022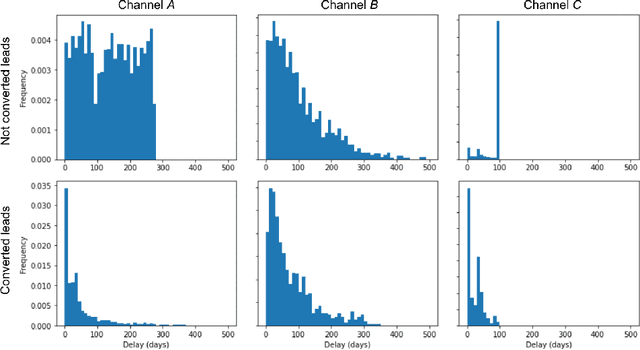
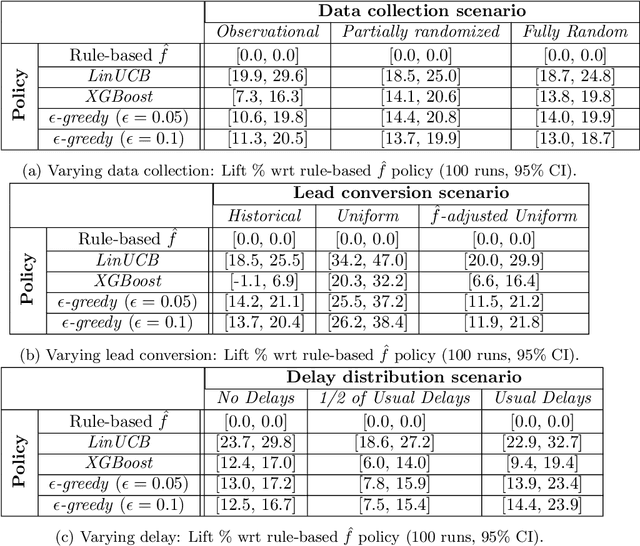
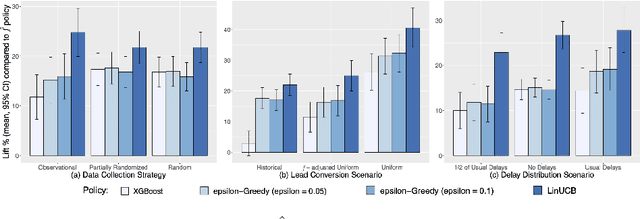
Training models on data obtained from randomized experiments is ideal for making good decisions. However, randomized experiments are often time-consuming, expensive, risky, infeasible or unethical to perform, leaving decision makers little choice but to rely on observational data collected under historical policies when training models. This opens questions regarding not only which decision-making policies would perform best in practice, but also regarding the impact of different data collection protocols on the performance of various policies trained on the data, or the robustness of policy performance with respect to changes in problem characteristics such as action- or reward- specific delays in observing outcomes. We aim to answer such questions for the problem of optimizing sales channel allocations at LinkedIn, where sales accounts (leads) need to be allocated to one of three channels, with the goal of maximizing the number of successful conversions over a period of time. A key problem feature constitutes the presence of stochastic delays in observing allocation outcomes, whose distribution is both channel- and outcome- dependent. We built a discrete-time simulation that can handle our problem features and used it to evaluate: a) a historical rule-based policy; b) a supervised machine learning policy (XGBoost); and c) multi-armed bandit (MAB) policies, under different scenarios involving: i) data collection used for training (observational vs randomized); ii) lead conversion scenarios; iii) delay distributions. Our simulation results indicate that LinUCB, a simple MAB policy, consistently outperforms the other policies, achieving a 18-47% lift relative to a rule-based policy
MCA-based Rule Mining Enables Interpretable Inference in Clinical Psychiatry
Oct 26, 2018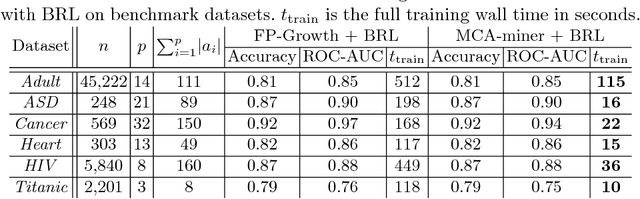
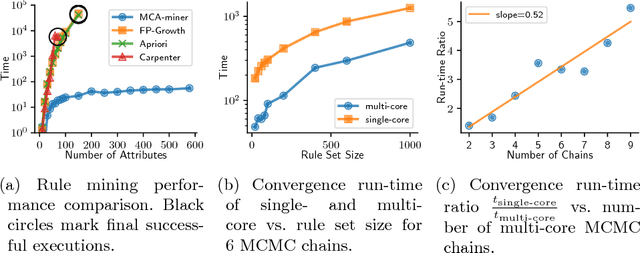
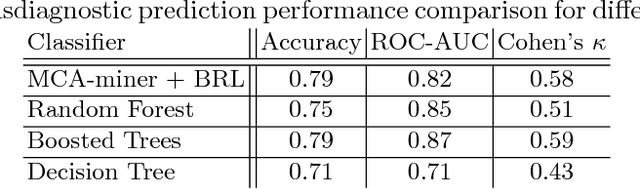
Development of interpretable machine learning models for clinical healthcare applications has the potential of changing the way we understand, treat, and ultimately cure, diseases and disorders in many areas of medicine. Interpretable ML models for clinical healthcare can serve not only as sources of predictions and estimates, but also as discovery tools for clinicians and researchers to reveal new knowledge from the data. High dimensionality of patient information (e.g., phenotype, genotype, and medical history), lack of objective measurements, and the heterogeneity in patient populations often create significant challenges in developing interpretable machine learning models for clinical psychiatry in practice. In this paper we take a step towards the development of such interpretable models. First, by developing a novel categorical rule mining method based on Multivariate Correspondence Analysis (MCA) capable of handling datasets with large numbers of feature categories, and second, by applying this method to build a transdiagnostic Bayesian Rule List model to screen for neuropsychiatric disorders using Consortium for Neuropsychiatric Phenomics dataset. We show that our method is not only at least 100 times faster than state-of-the-art rule mining techniques for datasets with 50 features, but also provides interpretability and comparable prediction accuracy across several benchmark datasets.
Simultaneous Receding Horizon Estimation and Control of a Fencing Robot using a Single Camera
Apr 14, 2015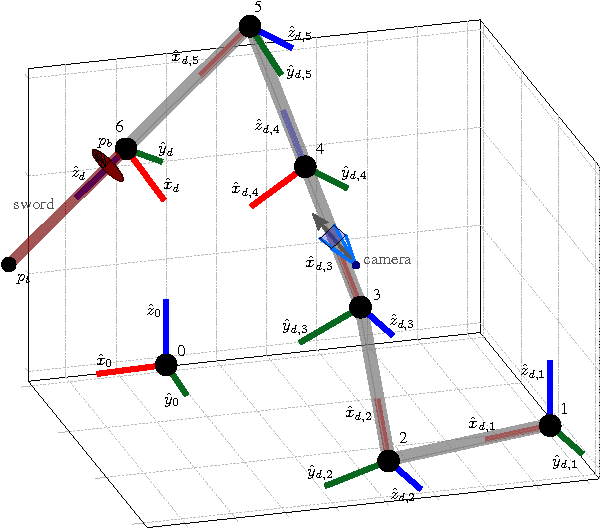
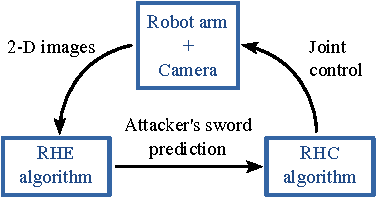
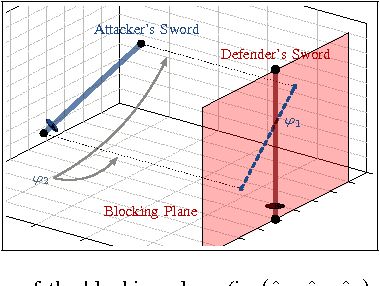
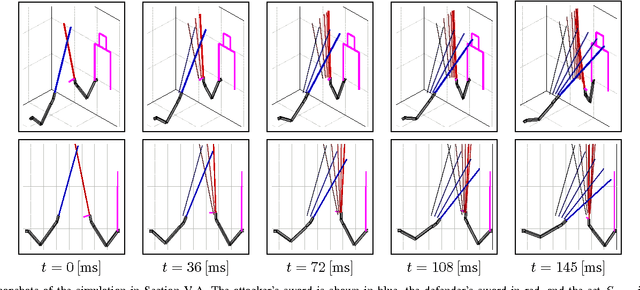
We present a method for simultaneous Receding Horizon Estimation and Control of a robotic arm equipped with a sword in an adversarial situation. Using a single camera mounted on the arm, we solve the problem of blocking a opponent's sword with the robot's sword. Our algorithm uses model-based sensing to estimate the opponent's intentions from the camera's observations, while it simultaneously applies a control action to both block the opponent's sword and improve future camera observations.
Rapid Integration and Calibration of New Sensors Using the Berkeley Aachen Robotics Toolkit (BART)
Sep 08, 2014
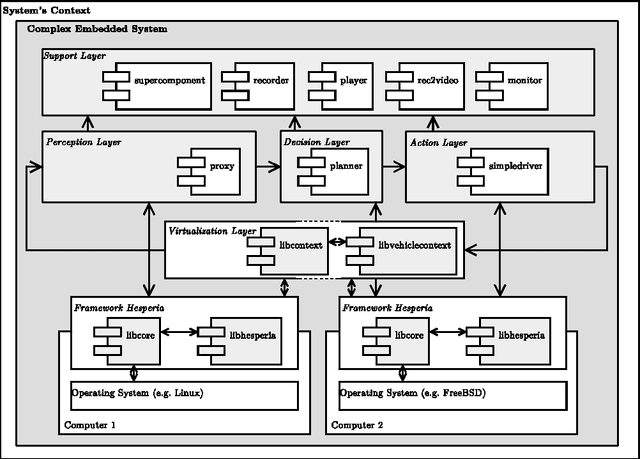
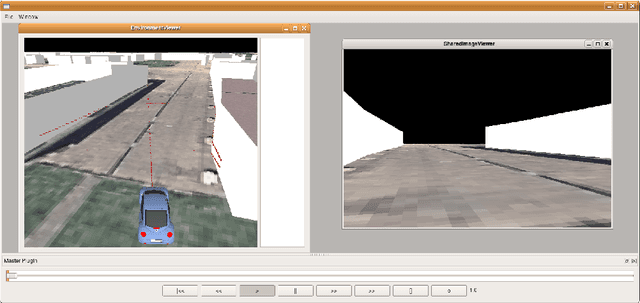
After the three DARPA Grand Challenge contests many groups around the world have continued to actively research and work toward an autonomous vehicle capable of accomplishing a mission in a given context (e.g. desert, city) while following a set of prescribed rules, but none has been completely successful in uncontrolled environments, a task that many people trivially fulfill every day. We believe that, together with improving the sensors used in cars and the artificial intelligence algorithms used to process the information, the community should focus on the systems engineering aspects of the problem, i.e. the limitations of the car (in terms of space, power, or heat dissipation) and the limitations of the software development cycle. This paper explores these issues and our experiences overcoming them.
Provably Safe and Robust Learning-Based Model Predictive Control
Aug 04, 2012
Controller design faces a trade-off between robustness and performance, and the reliability of linear controllers has caused many practitioners to focus on the former. However, there is renewed interest in improving system performance to deal with growing energy constraints. This paper describes a learning-based model predictive control (LBMPC) scheme that provides deterministic guarantees on robustness, while statistical identification tools are used to identify richer models of the system in order to improve performance; the benefits of this framework are that it handles state and input constraints, optimizes system performance with respect to a cost function, and can be designed to use a wide variety of parametric or nonparametric statistical tools. The main insight of LBMPC is that safety and performance can be decoupled under reasonable conditions in an optimization framework by maintaining two models of the system. The first is an approximate model with bounds on its uncertainty, and the second model is updated by statistical methods. LBMPC improves performance by choosing inputs that minimize a cost subject to the learned dynamics, and it ensures safety and robustness by checking whether these same inputs keep the approximate model stable when it is subject to uncertainty. Furthermore, we show that if the system is sufficiently excited, then the LBMPC control action probabilistically converges to that of an MPC computed using the true dynamics.
Statistical Results on Filtering and Epi-convergence for Learning-Based Model Predictive Control
Aug 03, 2012
Learning-based model predictive control (LBMPC) is a technique that provides deterministic guarantees on robustness, while statistical identification tools are used to identify richer models of the system in order to improve performance. This technical note provides proofs that elucidate the reasons for our choice of measurement model, as well as giving proofs concerning the stochastic convergence of LBMPC. The first part of this note discusses simultaneous state estimation and statistical identification (or learning) of unmodeled dynamics, for dynamical systems that can be described by ordinary differential equations (ODE's). The second part provides proofs concerning the epi-convergence of different statistical estimators that can be used with the learning-based model predictive control (LBMPC) technique. In particular, we prove results on the statistical properties of a nonparametric estimator that we have designed to have the correct deterministic and stochastic properties for numerical implementation when used in conjunction with LBMPC.