 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetterCheck: Towards Safeguarding VLMs for Automotive Perception Systems
Jul 23, 2025Large language models (LLMs) are growingly extended to process multimodal data such as text and video simultaneously. Their remarkable performance in understanding what is shown in images is surpassing specialized neural networks (NNs) such as Yolo that is supporting only a well-formed but very limited vocabulary, ie., objects that they are able to detect. When being non-restricted, LLMs and in particular state-of-the-art vision language models (VLMs) show impressive performance to describe even complex traffic situations. This is making them potentially suitable components for automotive perception systems to support the understanding of complex traffic situations or edge case situation. However, LLMs and VLMs are prone to hallucination, which mean to either potentially not seeing traffic agents such as vulnerable road users who are present in a situation, or to seeing traffic agents who are not there in reality. While the latter is unwanted making an ADAS or autonomous driving systems (ADS) to unnecessarily slow down, the former could lead to disastrous decisions from an ADS. In our work, we are systematically assessing the performance of 3 state-of-the-art VLMs on a diverse subset of traffic situations sampled from the Waymo Open Dataset to support safety guardrails for capturing such hallucinations in VLM-supported perception systems. We observe that both, proprietary and open VLMs exhibit remarkable image understanding capabilities even paying thorough attention to fine details sometimes difficult to spot for us humans. However, they are also still prone to making up elements in their descriptions to date requiring hallucination detection strategies such as BetterCheck that we propose in our work.
Large Language Models in Code Co-generation for Safe Autonomous Vehicles
May 26, 2025Software engineers in various industrial domains are already using Large Language Models (LLMs) to accelerate the process of implementing parts of software systems. When considering its potential use for ADAS or AD systems in the automotive context, there is a need to systematically assess this new setup: LLMs entail a well-documented set of risks for safety-related systems' development due to their stochastic nature. To reduce the effort for code reviewers to evaluate LLM-generated code, we propose an evaluation pipeline to conduct sanity-checks on the generated code. We compare the performance of six state-of-the-art LLMs (CodeLlama, CodeGemma, DeepSeek-r1, DeepSeek-Coders, Mistral, and GPT-4) on four safety-related programming tasks. Additionally, we qualitatively analyse the most frequent faults generated by these LLMs, creating a failure-mode catalogue to support human reviewers. Finally, the limitations and capabilities of LLMs in code generation, and the use of the proposed pipeline in the existing process, are discussed.
On Simulation-Guided LLM-based Code Generation for Safe Autonomous Driving Software
Apr 02, 2025


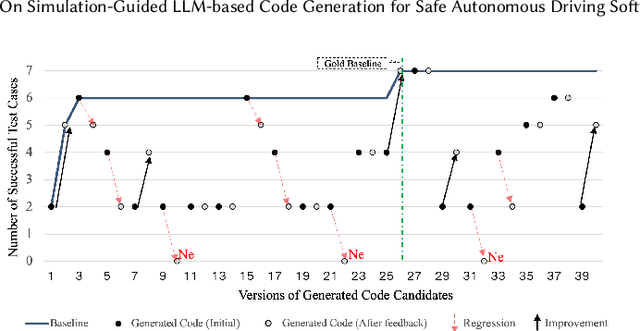
Automated Driving System (ADS) is a safety-critical software system responsible for the interpretation of the vehicle's environment and making decisions accordingly. The unbounded complexity of the driving context, including unforeseeable events, necessitate continuous improvement, often achieved through iterative DevOps processes. However, DevOps processes are themselves complex, making these improvements both time- and resource-intensive. Automation in code generation for ADS using Large Language Models (LLM) is one potential approach to address this challenge. Nevertheless, the development of ADS requires rigorous processes to verify, validate, assess, and qualify the code before it can be deployed in the vehicle and used. In this study, we developed and evaluated a prototype for automatic code generation and assessment using a designed pipeline of a LLM-based agent, simulation model, and rule-based feedback generator in an industrial setup. The LLM-generated code is evaluated automatically in a simulation model against multiple critical traffic scenarios, and an assessment report is provided as feedback to the LLM for modification or bug fixing. We report about the experimental results of the prototype employing Codellama:34b, DeepSeek (r1:32b and Coder:33b), CodeGemma:7b, Mistral:7b, and GPT4 for Adaptive Cruise Control (ACC) and Unsupervised Collision Avoidance by Evasive Manoeuvre (CAEM). We finally assessed the tool with 11 experts at two Original Equipment Manufacturers (OEMs) by conducting an interview study.
Predicting Pedestrian Crossing Behavior in Germany and Japan: Insights into Model Transferability
Dec 04, 2024



Predicting pedestrian crossing behavior is important for intelligent traffic systems to avoid pedestrian-vehicle collisions. Most existing pedestrian crossing behavior models are trained and evaluated on datasets collected from a single country, overlooking differences between countries. To address this gap, we compared pedestrian road-crossing behavior at unsignalized crossings in Germany and Japan. We presented four types of machine learning models to predict gap selection behavior, zebra crossing usage, and their trajectories using simulator data collected from both countries. When comparing the differences between countries, pedestrians from the study conducted in Japan are more cautious, selecting larger gaps compared to those in Germany. We evaluate and analyze model transferability. Our results show that neural networks outperform other machine learning models in predicting gap selection and zebra crossing usage, while random forest models perform best on trajectory prediction tasks, demonstrating strong performance and transferability. We develop a transferable model using an unsupervised clustering method, which improves prediction accuracy for gap selection and trajectory prediction. These findings provide a deeper understanding of pedestrian crossing behaviors in different countries and offer valuable insights into model transferability.
Tapping in a Remote Vehicle's onboard LLM to Complement the Ego Vehicle's Field-of-View
Aug 20, 2024Today's advanced automotive systems are turning into intelligent Cyber-Physical Systems (CPS), bringing computational intelligence to their cyber-physical context. Such systems power advanced driver assistance systems (ADAS) that observe a vehicle's surroundings for their functionality. However, such ADAS have clear limitations in scenarios when the direct line-of-sight to surrounding objects is occluded, like in urban areas. Imagine now automated driving (AD) systems that ideally could benefit from other vehicles' field-of-view in such occluded situations to increase traffic safety if, for example, locations about pedestrians can be shared across vehicles. Current literature suggests vehicle-to-infrastructure (V2I) via roadside units (RSUs) or vehicle-to-vehicle (V2V) communication to address such issues that stream sensor or object data between vehicles. When considering the ongoing revolution in vehicle system architectures towards powerful, centralized processing units with hardware accelerators, foreseeing the onboard presence of large language models (LLMs) to improve the passengers' comfort when using voice assistants becomes a reality. We are suggesting and evaluating a concept to complement the ego vehicle's field-of-view (FOV) with another vehicle's FOV by tapping into their onboard LLM to let the machines have a dialogue about what the other vehicle ``sees''. Our results show that very recent versions of LLMs, such as GPT-4V and GPT-4o, understand a traffic situation to an impressive level of detail, and hence, they can be used even to spot traffic participants. However, better prompts are needed to improve the detection quality and future work is needed towards a standardised message interchange format between vehicles.
Evaluating and Enhancing Trustworthiness of LLMs in Perception Tasks
Jul 18, 2024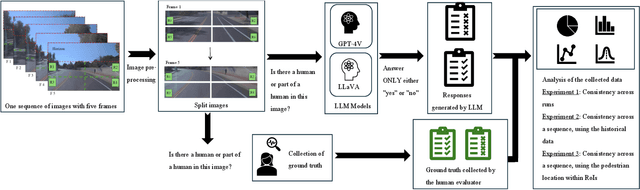
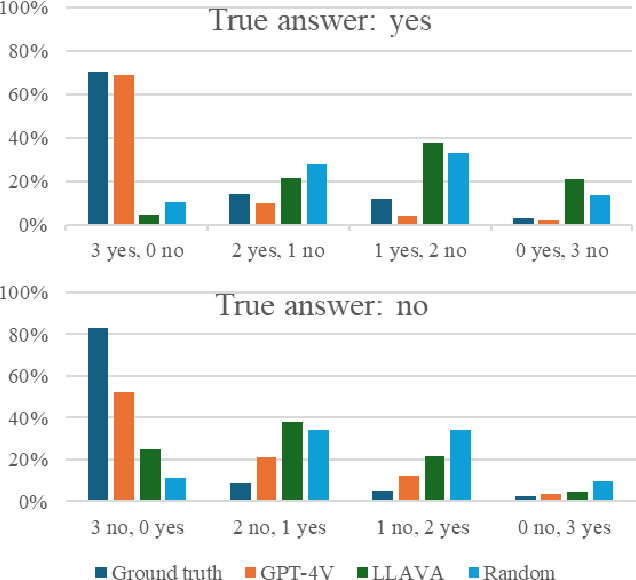

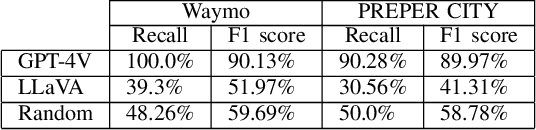
Today's advanced driver assistance systems (ADAS), like adaptive cruise control or rear collision warning, are finding broader adoption across vehicle classes. Integrating such advanced, multimodal Large Language Models (LLMs) on board a vehicle, which are capable of processing text, images, audio, and other data types, may have the potential to greatly enhance passenger comfort. Yet, an LLM's hallucinations are still a major challenge to be addressed. In this paper, we systematically assessed potential hallucination detection strategies for such LLMs in the context of object detection in vision-based data on the example of pedestrian detection and localization. We evaluate three hallucination detection strategies applied to two state-of-the-art LLMs, the proprietary GPT-4V and the open LLaVA, on two datasets (Waymo/US and PREPER CITY/Sweden). Our results show that these LLMs can describe a traffic situation to an impressive level of detail but are still challenged for further analysis activities such as object localization. We evaluate and extend hallucination detection approaches when applying these LLMs to video sequences in the example of pedestrian detection. Our experiments show that, at the moment, the state-of-the-art proprietary LLM performs much better than the open LLM. Furthermore, consistency enhancement techniques based on voting, such as the Best-of-Three (BO3) method, do not effectively reduce hallucinations in LLMs that tend to exhibit high false negatives in detecting pedestrians. However, extending the hallucination detection by including information from the past helps to improve results.
Semantic-Aware Representation of Multi-Modal Data for Data Ingress: A Literature Review
Jul 17, 2024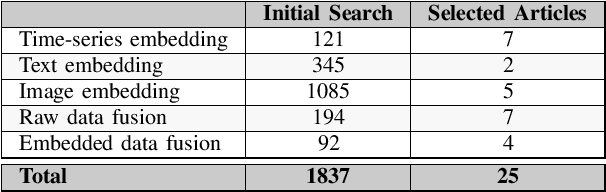
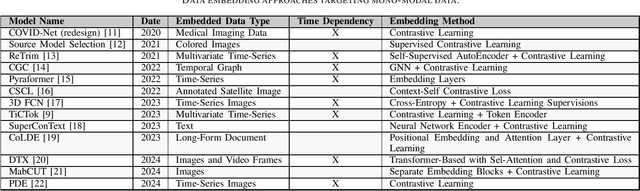
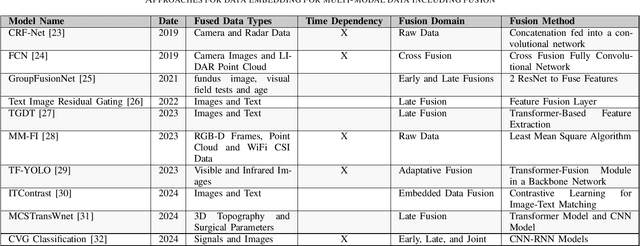
Machine Learning (ML) is continuously permeating a growing amount of application domains. Generative AI such as Large Language Models (LLMs) also sees broad adoption to process multi-modal data such as text, images, audio, and video. While the trend is to use ever-larger datasets for training, managing this data efficiently has become a significant practical challenge in the industry-double as much data is certainly not double as good. Rather the opposite is important since getting an understanding of the inherent quality and diversity of the underlying data lakes is a growing challenge for application-specific ML as well as for fine-tuning foundation models. Furthermore, information retrieval (IR) from expanding data lakes is complicated by the temporal dimension inherent in time-series data which must be considered to determine its semantic value. This study focuses on the different semantic-aware techniques to extract embeddings from mono-modal, multi-modal, and cross-modal data to enhance IR capabilities in a growing data lake. Articles were collected to summarize information about the state-of-the-art techniques focusing on applications of embedding for three different categories of data modalities.
Predicting and Analyzing Pedestrian Crossing Behavior at Unsignalized Crossings
Apr 15, 2024Understanding and predicting pedestrian crossing behavior is essential for enhancing automated driving and improving driving safety. Predicting gap selection behavior and the use of zebra crossing enables driving systems to proactively respond and prevent potential conflicts. This task is particularly challenging at unsignalized crossings due to the ambiguous right of way, requiring pedestrians to constantly interact with vehicles and other pedestrians. This study addresses these challenges by utilizing simulator data to investigate scenarios involving multiple vehicles and pedestrians. We propose and evaluate machine learning models to predict gap selection in non-zebra scenarios and zebra crossing usage in zebra scenarios. We investigate and discuss how pedestrians' behaviors are influenced by various factors, including pedestrian waiting time, walking speed, the number of unused gaps, the largest missed gap, and the influence of other pedestrians. This research contributes to the evolution of intelligent vehicles by providing predictive models and valuable insights into pedestrian crossing behavior.
Engineering Safety Requirements for Autonomous Driving with Large Language Models
Mar 24, 2024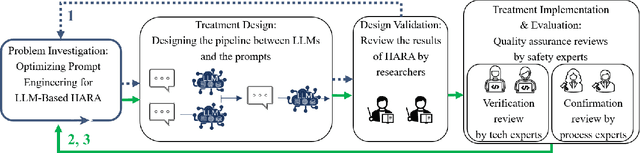

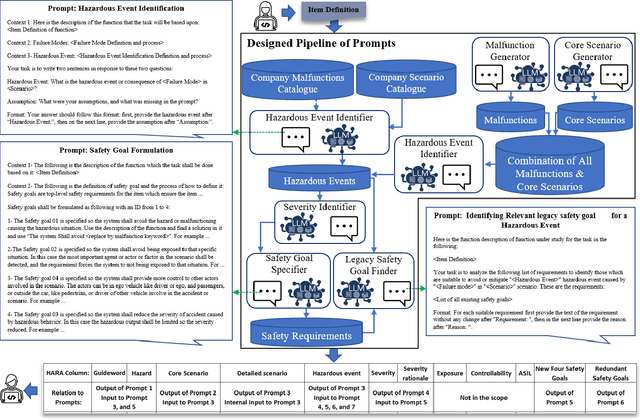

Changes and updates in the requirement artifacts, which can be frequent in the automotive domain, are a challenge for SafetyOps. Large Language Models (LLMs), with their impressive natural language understanding and generating capabilities, can play a key role in automatically refining and decomposing requirements after each update. In this study, we propose a prototype of a pipeline of prompts and LLMs that receives an item definition and outputs solutions in the form of safety requirements. This pipeline also performs a review of the requirement dataset and identifies redundant or contradictory requirements. We first identified the necessary characteristics for performing HARA and then defined tests to assess an LLM's capability in meeting these criteria. We used design science with multiple iterations and let experts from different companies evaluate each cycle quantitatively and qualitatively. Finally, the prototype was implemented at a case company and the responsible team evaluated its efficiency.
Welcome Your New AI Teammate: On Safety Analysis by Leashing Large Language Models
Mar 14, 2024DevOps is a necessity in many industries, including the development of Autonomous Vehicles. In those settings, there are iterative activities that reduce the speed of SafetyOps cycles. One of these activities is "Hazard Analysis & Risk Assessment" (HARA), which is an essential step to start the safety requirements specification. As a potential approach to increase the speed of this step in SafetyOps, we have delved into the capabilities of Large Language Models (LLMs). Our objective is to systematically assess their potential for application in the field of safety engineering. To that end, we propose a framework to support a higher degree of automation of HARA with LLMs. Despite our endeavors to automate as much of the process as possible, expert review remains crucial to ensure the validity and correctness of the analysis results, with necessary modifications made accordingly.