 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating and Enhancing Trustworthiness of LLMs in Perception Tasks
Paper and Code
Jul 18, 2024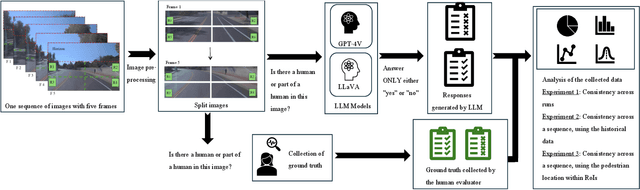
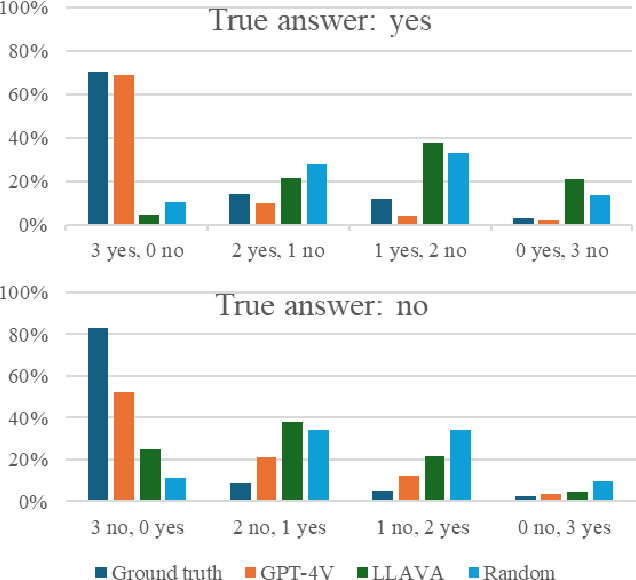

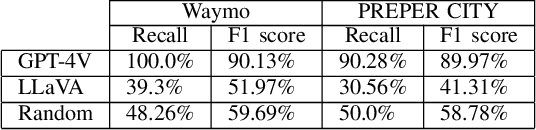
Today's advanced driver assistance systems (ADAS), like adaptive cruise control or rear collision warning, are finding broader adoption across vehicle classes. Integrating such advanced, multimodal Large Language Models (LLMs) on board a vehicle, which are capable of processing text, images, audio, and other data types, may have the potential to greatly enhance passenger comfort. Yet, an LLM's hallucinations are still a major challenge to be addressed. In this paper, we systematically assessed potential hallucination detection strategies for such LLMs in the context of object detection in vision-based data on the example of pedestrian detection and localization. We evaluate three hallucination detection strategies applied to two state-of-the-art LLMs, the proprietary GPT-4V and the open LLaVA, on two datasets (Waymo/US and PREPER CITY/Sweden). Our results show that these LLMs can describe a traffic situation to an impressive level of detail but are still challenged for further analysis activities such as object localization. We evaluate and extend hallucination detection approaches when applying these LLMs to video sequences in the example of pedestrian detection. Our experiments show that, at the moment, the state-of-the-art proprietary LLM performs much better than the open LLM. Furthermore, consistency enhancement techniques based on voting, such as the Best-of-Three (BO3) method, do not effectively reduce hallucinations in LLMs that tend to exhibit high false negatives in detecting pedestrians. However, extending the hallucination detection by including information from the past helps to improve results.