 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetterCheck: Towards Safeguarding VLMs for Automotive Perception Systems
Jul 23, 2025Large language models (LLMs) are growingly extended to process multimodal data such as text and video simultaneously. Their remarkable performance in understanding what is shown in images is surpassing specialized neural networks (NNs) such as Yolo that is supporting only a well-formed but very limited vocabulary, ie., objects that they are able to detect. When being non-restricted, LLMs and in particular state-of-the-art vision language models (VLMs) show impressive performance to describe even complex traffic situations. This is making them potentially suitable components for automotive perception systems to support the understanding of complex traffic situations or edge case situation. However, LLMs and VLMs are prone to hallucination, which mean to either potentially not seeing traffic agents such as vulnerable road users who are present in a situation, or to seeing traffic agents who are not there in reality. While the latter is unwanted making an ADAS or autonomous driving systems (ADS) to unnecessarily slow down, the former could lead to disastrous decisions from an ADS. In our work, we are systematically assessing the performance of 3 state-of-the-art VLMs on a diverse subset of traffic situations sampled from the Waymo Open Dataset to support safety guardrails for capturing such hallucinations in VLM-supported perception systems. We observe that both, proprietary and open VLMs exhibit remarkable image understanding capabilities even paying thorough attention to fine details sometimes difficult to spot for us humans. However, they are also still prone to making up elements in their descriptions to date requiring hallucination detection strategies such as BetterCheck that we propose in our work.
Tapping in a Remote Vehicle's onboard LLM to Complement the Ego Vehicle's Field-of-View
Aug 20, 2024Today's advanced automotive systems are turning into intelligent Cyber-Physical Systems (CPS), bringing computational intelligence to their cyber-physical context. Such systems power advanced driver assistance systems (ADAS) that observe a vehicle's surroundings for their functionality. However, such ADAS have clear limitations in scenarios when the direct line-of-sight to surrounding objects is occluded, like in urban areas. Imagine now automated driving (AD) systems that ideally could benefit from other vehicles' field-of-view in such occluded situations to increase traffic safety if, for example, locations about pedestrians can be shared across vehicles. Current literature suggests vehicle-to-infrastructure (V2I) via roadside units (RSUs) or vehicle-to-vehicle (V2V) communication to address such issues that stream sensor or object data between vehicles. When considering the ongoing revolution in vehicle system architectures towards powerful, centralized processing units with hardware accelerators, foreseeing the onboard presence of large language models (LLMs) to improve the passengers' comfort when using voice assistants becomes a reality. We are suggesting and evaluating a concept to complement the ego vehicle's field-of-view (FOV) with another vehicle's FOV by tapping into their onboard LLM to let the machines have a dialogue about what the other vehicle ``sees''. Our results show that very recent versions of LLMs, such as GPT-4V and GPT-4o, understand a traffic situation to an impressive level of detail, and hence, they can be used even to spot traffic participants. However, better prompts are needed to improve the detection quality and future work is needed towards a standardised message interchange format between vehicles.
Evaluating and Enhancing Trustworthiness of LLMs in Perception Tasks
Jul 18, 2024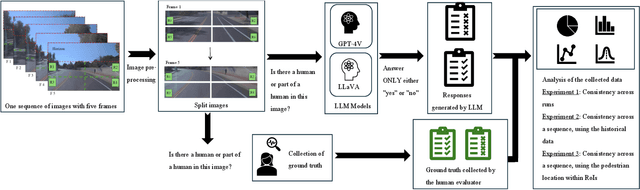
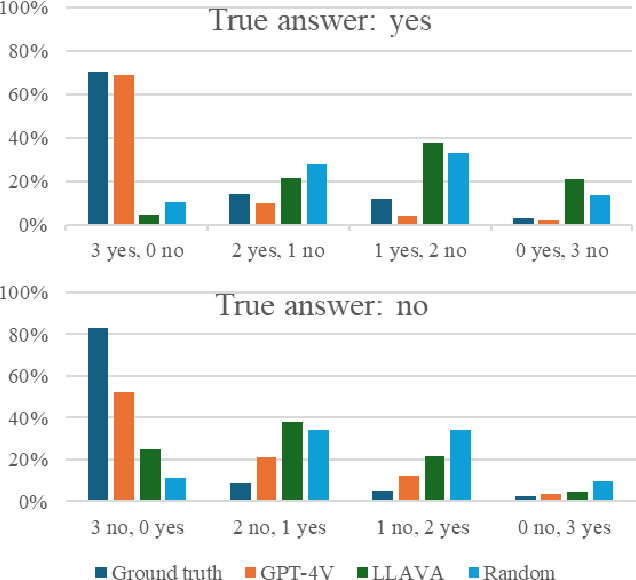

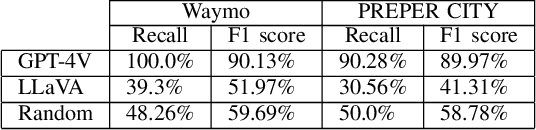
Today's advanced driver assistance systems (ADAS), like adaptive cruise control or rear collision warning, are finding broader adoption across vehicle classes. Integrating such advanced, multimodal Large Language Models (LLMs) on board a vehicle, which are capable of processing text, images, audio, and other data types, may have the potential to greatly enhance passenger comfort. Yet, an LLM's hallucinations are still a major challenge to be addressed. In this paper, we systematically assessed potential hallucination detection strategies for such LLMs in the context of object detection in vision-based data on the example of pedestrian detection and localization. We evaluate three hallucination detection strategies applied to two state-of-the-art LLMs, the proprietary GPT-4V and the open LLaVA, on two datasets (Waymo/US and PREPER CITY/Sweden). Our results show that these LLMs can describe a traffic situation to an impressive level of detail but are still challenged for further analysis activities such as object localization. We evaluate and extend hallucination detection approaches when applying these LLMs to video sequences in the example of pedestrian detection. Our experiments show that, at the moment, the state-of-the-art proprietary LLM performs much better than the open LLM. Furthermore, consistency enhancement techniques based on voting, such as the Best-of-Three (BO3) method, do not effectively reduce hallucinations in LLMs that tend to exhibit high false negatives in detecting pedestrians. However, extending the hallucination detection by including information from the past helps to improve results.