 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKG-Reasoner: A Reinforced Model for End-to-End Multi-Hop Knowledge Graph Reasoning
Apr 14, 2026Large Language Models (LLMs) exhibit strong abilities in natural language understanding and generation, yet they struggle with knowledge-intensive reasoning. Structured Knowledge Graphs (KGs) provide an effective form of external knowledge representation and have been widely used to enhance performance in classical Knowledge Base Question Answering (KBQA) tasks. However, performing precise multi-hop reasoning over KGs for complex queries remains highly challenging. Most existing approaches decompose the reasoning process into a sequence of isolated steps executed through a fixed pipeline. While effective to some extent, such designs constrain reasoning flexibility and fragment the overall decision process, often leading to incoherence and the loss of critical intermediate information from earlier steps. In this paper, we introduce KG-Reasoner, an end-to-end framework that integrates multi-step reasoning into a unified "thinking" phase of a Reasoning LLM. Through Reinforcement Learning (RL), the LLM is trained to internalize the KG traversal process, enabling it to dynamically explore reasoning paths, and perform backtracking when necessary. Experiments on eight multi-hop and knowledge-intensive reasoning benchmarks demonstrate that KG-Reasoner achieves competitive or superior performance compared to the state-of-the-art methods. Codes are available at the repository: https://github.com/Wangshuaiia/KG-Reasoner.
Topology-Aware Reasoning over Incomplete Knowledge Graph with Graph-Based Soft Prompting
Apr 14, 2026Large Language Models (LLMs) have shown remarkable capabilities across various tasks but remain prone to hallucinations in knowledge-intensive scenarios. Knowledge Base Question Answering (KBQA) mitigates this by grounding generation in Knowledge Graphs (KGs). However, most multi-hop KBQA methods rely on explicit edge traversal, making them fragile to KG incompleteness. In this paper, we proposed a novel graph-based soft prompting framework that shifts the reasoning paradigm from node-level path traversal to subgraph-level reasoning. Specifically, we employ a Graph Neural Network (GNN) to encode extracted structural subgraphs into soft prompts, enabling LLM to reason over richer structural context and identify relevant entities beyond immediate graph neighbors, thereby reducing sensitivity to missing edges. Furthermore, we introduce a two-stage paradigm that reduces computational cost while preserving good performance: a lightweight LLM first leverages the soft prompts to identify question-relevant entities and relations, followed by a more powerful LLM for evidence-aware answer generation. Experiments on four multi-hop KBQA benchmarks show that our approach achieves state-of-the-art performance on three of them, demonstrating its effectiveness. Code is available at the repository: https://github.com/Wangshuaiia/GraSP.
Domain-Invariant Prompt Learning for Vision-Language Models
Mar 30, 2026Large pre-trained vision-language models like CLIP have transformed computer vision by aligning images and text in a shared feature space, enabling robust zero-shot transfer via prompting. Soft-prompting, such as Context Optimization (CoOp), effectively adapts these models for downstream recognition tasks by learning a set of context vectors. However, CoOp lacks explicit mechanisms for handling domain shifts across unseen distributions. To address this, we propose Domain-invariant Context Optimization (DiCoOp), an extension of CoOp optimized for domain generalization. By employing an adversarial training approach, DiCoOp forces the model to learn domain-invariant prompts while preserving discriminative power for classification. Experimental results show that DiCoOp consistently surpasses CoOp in domain generalization tasks across diverse visual domains.
LLM-Powered Workflow Optimization for Multidisciplinary Software Development: An Automotive Industry Case Study
Mar 22, 2026Multidisciplinary Software Development (MSD) requires domain experts and developers to collaborate across incompatible formalisms and separate artifact sets. Today, even with AI coding assistants like GitHub Copilot, this process remains inefficient; individual coding tasks are semi-automated, but the workflow connecting domain knowledge to implementation is not. Developers and experts still lack a shared view, resulting in repeated coordination, clarification rounds, and error-prone handoffs. We address this gap through a graph-based workflow optimization approach that progressively replaces manual coordination with LLM-powered services, enabling incremental adoption without disrupting established practices. We evaluate our approach on \texttt{spapi}, a production in-vehicle API system at Volvo Group involving 192 endpoints, 420 properties, and 776 CAN signals across six functional domains. The automated workflow achieves 93.7\% F1 score while reducing per-API development time from approximately 5 hours to under 7 minutes, saving an estimated 979 engineering hours. In production, the system received high satisfaction from both domain experts and developers, with all participants reporting full satisfaction with communication efficiency.
DomAgent: Leveraging Knowledge Graphs and Case-Based Reasoning for Domain-Specific Code Generation
Mar 22, 2026Large language models (LLMs) have shown impressive capabilities in code generation. However, because most LLMs are trained on public domain corpora, directly applying them to real-world software development often yields low success rates, as these scenarios frequently require domain-specific knowledge. In particular, domain-specific tasks usually demand highly specialized solutions, which are often underrepresented or entirely absent in the training data of generic LLMs. To address this challenge, we propose DomAgent, an autonomous coding agent that bridges this gap by enabling LLMs to generate domain-adapted code through structured reasoning and targeted retrieval. A core component of DomAgent is DomRetriever, a novel retrieval module that emulates how humans learn domain-specific knowledge, by combining conceptual understanding with experiential examples. It dynamically integrates top-down knowledge-graph reasoning with bottom-up case-based reasoning, enabling iterative retrieval and synthesis of structured knowledge and representative cases to ensure contextual relevance and broad task coverage. DomRetriever can operate as part of DomAgent or independently with any LLM for flexible domain adaptation. We evaluate DomAgent on an open benchmark dataset in the data science domain (DS-1000) and further apply it to real-world truck software development tasks. Experimental results show that DomAgent significantly enhances domain-specific code generation, enabling small open-source models to close much of the performance gap with large proprietary LLMs in complex, real-world applications. The code is available at: https://github.com/Wangshuaiia/DomAgent.
KG-Hopper: Empowering Compact Open LLMs with Knowledge Graph Reasoning via Reinforcement Learning
Mar 22, 2026Large Language Models (LLMs) demonstrate impressive natural language capabilities but often struggle with knowledge-intensive reasoning tasks. Knowledge Base Question Answering (KBQA), which leverages structured Knowledge Graphs (KGs) exemplifies this challenge due to the need for accurate multi-hop reasoning. Existing approaches typically perform sequential reasoning steps guided by predefined pipelines, restricting flexibility and causing error cascades due to isolated reasoning at each step. To address these limitations, we propose KG-Hopper, a novel Reinforcement Learning (RL) framework that empowers compact open LLMs with the ability to perform integrated multi-hop KG reasoning within a single inference round. Rather than reasoning step-by-step, we train a Reasoning LLM that embeds the entire KG traversal and decision process into a unified ``thinking'' stage, enabling global reasoning over cross-step dependencies and dynamic path exploration with backtracking. Experimental results on eight KG reasoning benchmarks show that KG-Hopper, based on a 7B-parameter LLM, consistently outperforms larger multi-step systems (up to 70B) and achieves competitive performance with proprietary models such as GPT-3.5-Turbo and GPT-4o-mini, while remaining compact, open, and data-efficient. The code is publicly available at: https://github.com/Wangshuaiia/KG-Hopper.
PCARNN-DCBF: Minimal-Intervention Geofence Enforcement for Ground Vehicles
Nov 19, 2025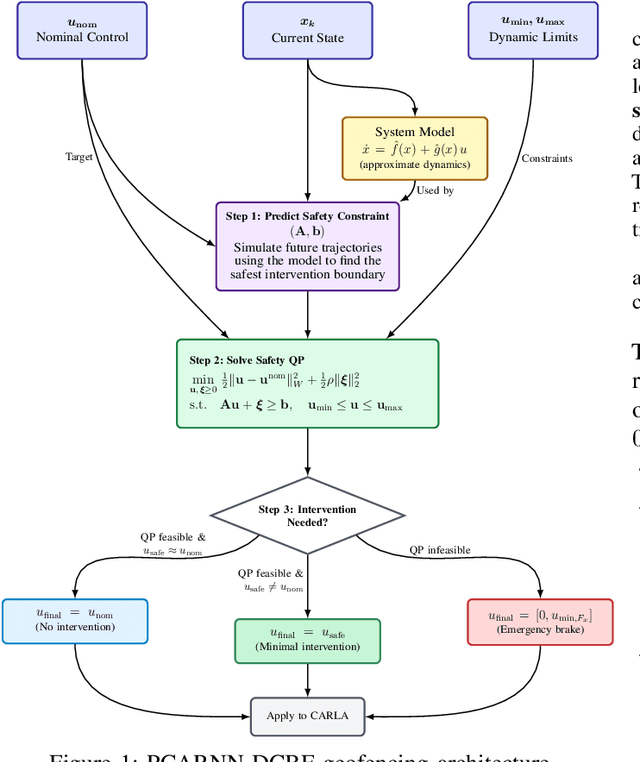



Runtime geofencing for ground vehicles is rapidly emerging as a critical technology for enforcing Operational Design Domains (ODDs). However, existing solutions struggle to reconcile high-fidelity learning with the structural requirements of verifiable control. We address this by introducing PCARNN-DCBF, a novel pipeline integrating a Physics-encoded Control-Affine Residual Neural Network with a preview-based Discrete Control Barrier Function. Unlike generic learned models, PCARNN explicitly preserves the control-affine structure of vehicle dynamics, ensuring the linearity required for reliable optimization. This enables the DCBF to enforce polygonal keep-in constraints via a real-time Quadratic Program (QP) that handles high relative degree and mitigates actuator saturation. Experiments in CARLA across electric and combustion platforms demonstrate that this structure-preserving approach significantly outperforms analytical and unstructured neural baselines.
Cost-Aware Prediction (CAP): An LLM-Enhanced Machine Learning Pipeline and Decision Support System for Heart Failure Mortality Prediction
Nov 19, 2025Objective: Machine learning (ML) predictive models are often developed without considering downstream value trade-offs and clinical interpretability. This paper introduces a cost-aware prediction (CAP) framework that combines cost-benefit analysis assisted by large language model (LLM) agents to communicate the trade-offs involved in applying ML predictions. Materials and Methods: We developed an ML model predicting 1-year mortality in patients with heart failure (N = 30,021, 22% mortality) to identify those eligible for home care. We then introduced clinical impact projection (CIP) curves to visualize important cost dimensions - quality of life and healthcare provider expenses, further divided into treatment and error costs, to assess the clinical consequences of predictions. Finally, we used four LLM agents to generate patient-specific descriptions. The system was evaluated by clinicians for its decision support value. Results: The eXtreme gradient boosting (XGB) model achieved the best performance, with an area under the receiver operating characteristic curve (AUROC) of 0.804 (95% confidence interval (CI) 0.792-0.816), area under the precision-recall curve (AUPRC) of 0.529 (95% CI 0.502-0.558) and a Brier score of 0.135 (95% CI 0.130-0.140). Discussion: The CIP cost curves provided a population-level overview of cost composition across decision thresholds, whereas LLM-generated cost-benefit analysis at individual patient-levels. The system was well received according to the evaluation by clinicians. However, feedback emphasizes the need to strengthen the technical accuracy for speculative tasks. Conclusion: CAP utilizes LLM agents to integrate ML classifier outcomes and cost-benefit analysis for more transparent and interpretable decision support.
BetterCheck: Towards Safeguarding VLMs for Automotive Perception Systems
Jul 23, 2025Large language models (LLMs) are growingly extended to process multimodal data such as text and video simultaneously. Their remarkable performance in understanding what is shown in images is surpassing specialized neural networks (NNs) such as Yolo that is supporting only a well-formed but very limited vocabulary, ie., objects that they are able to detect. When being non-restricted, LLMs and in particular state-of-the-art vision language models (VLMs) show impressive performance to describe even complex traffic situations. This is making them potentially suitable components for automotive perception systems to support the understanding of complex traffic situations or edge case situation. However, LLMs and VLMs are prone to hallucination, which mean to either potentially not seeing traffic agents such as vulnerable road users who are present in a situation, or to seeing traffic agents who are not there in reality. While the latter is unwanted making an ADAS or autonomous driving systems (ADS) to unnecessarily slow down, the former could lead to disastrous decisions from an ADS. In our work, we are systematically assessing the performance of 3 state-of-the-art VLMs on a diverse subset of traffic situations sampled from the Waymo Open Dataset to support safety guardrails for capturing such hallucinations in VLM-supported perception systems. We observe that both, proprietary and open VLMs exhibit remarkable image understanding capabilities even paying thorough attention to fine details sometimes difficult to spot for us humans. However, they are also still prone to making up elements in their descriptions to date requiring hallucination detection strategies such as BetterCheck that we propose in our work.
GateLens: A Reasoning-Enhanced LLM Agent for Automotive Software Release Analytics
Mar 27, 2025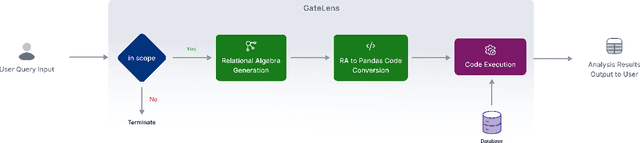


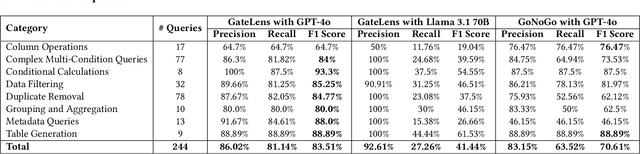
Ensuring the reliability and effectiveness of software release decisions is critical, particularly in safety-critical domains like automotive systems. Precise analysis of release validation data, often presented in tabular form, plays a pivotal role in this process. However, traditional methods that rely on manual analysis of extensive test datasets and validation metrics are prone to delays and high costs. Large Language Models (LLMs) offer a promising alternative but face challenges in analytical reasoning, contextual understanding, handling out-of-scope queries, and processing structured test data consistently; limitations that hinder their direct application in safety-critical scenarios. This paper introduces GateLens, an LLM-based tool for analyzing tabular data in the automotive domain. GateLens translates natural language queries into Relational Algebra (RA) expressions and then generates optimized Python code. It outperforms the baseline system on benchmarking datasets, achieving higher F1 scores and handling complex and ambiguous queries with greater robustness. Ablation studies confirm the critical role of the RA module, with performance dropping sharply when omitted. Industrial evaluations reveal that GateLens reduces analysis time by over 80% while maintaining high accuracy and reliability. As demonstrated by presented results, GateLens achieved high performance without relying on few-shot examples, showcasing strong generalization across various query types from diverse company roles. Insights from deploying GateLens with a partner automotive company offer practical guidance for integrating AI into critical workflows such as release validation. Results show that by automating test result analysis, GateLens enables faster, more informed, and dependable release decisions, and can thus advance software scalability and reliability in automotive systems.