 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Powered Workflow Optimization for Multidisciplinary Software Development: An Automotive Industry Case Study
Mar 22, 2026Multidisciplinary Software Development (MSD) requires domain experts and developers to collaborate across incompatible formalisms and separate artifact sets. Today, even with AI coding assistants like GitHub Copilot, this process remains inefficient; individual coding tasks are semi-automated, but the workflow connecting domain knowledge to implementation is not. Developers and experts still lack a shared view, resulting in repeated coordination, clarification rounds, and error-prone handoffs. We address this gap through a graph-based workflow optimization approach that progressively replaces manual coordination with LLM-powered services, enabling incremental adoption without disrupting established practices. We evaluate our approach on \texttt{spapi}, a production in-vehicle API system at Volvo Group involving 192 endpoints, 420 properties, and 776 CAN signals across six functional domains. The automated workflow achieves 93.7\% F1 score while reducing per-API development time from approximately 5 hours to under 7 minutes, saving an estimated 979 engineering hours. In production, the system received high satisfaction from both domain experts and developers, with all participants reporting full satisfaction with communication efficiency.
DomAgent: Leveraging Knowledge Graphs and Case-Based Reasoning for Domain-Specific Code Generation
Mar 22, 2026Large language models (LLMs) have shown impressive capabilities in code generation. However, because most LLMs are trained on public domain corpora, directly applying them to real-world software development often yields low success rates, as these scenarios frequently require domain-specific knowledge. In particular, domain-specific tasks usually demand highly specialized solutions, which are often underrepresented or entirely absent in the training data of generic LLMs. To address this challenge, we propose DomAgent, an autonomous coding agent that bridges this gap by enabling LLMs to generate domain-adapted code through structured reasoning and targeted retrieval. A core component of DomAgent is DomRetriever, a novel retrieval module that emulates how humans learn domain-specific knowledge, by combining conceptual understanding with experiential examples. It dynamically integrates top-down knowledge-graph reasoning with bottom-up case-based reasoning, enabling iterative retrieval and synthesis of structured knowledge and representative cases to ensure contextual relevance and broad task coverage. DomRetriever can operate as part of DomAgent or independently with any LLM for flexible domain adaptation. We evaluate DomAgent on an open benchmark dataset in the data science domain (DS-1000) and further apply it to real-world truck software development tasks. Experimental results show that DomAgent significantly enhances domain-specific code generation, enabling small open-source models to close much of the performance gap with large proprietary LLMs in complex, real-world applications. The code is available at: https://github.com/Wangshuaiia/DomAgent.
GateLens: A Reasoning-Enhanced LLM Agent for Automotive Software Release Analytics
Mar 27, 2025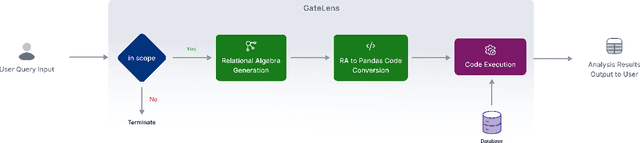


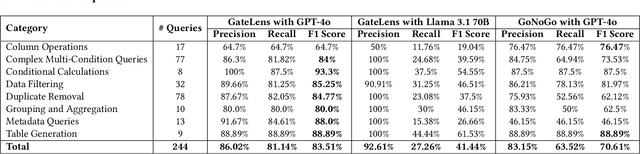
Ensuring the reliability and effectiveness of software release decisions is critical, particularly in safety-critical domains like automotive systems. Precise analysis of release validation data, often presented in tabular form, plays a pivotal role in this process. However, traditional methods that rely on manual analysis of extensive test datasets and validation metrics are prone to delays and high costs. Large Language Models (LLMs) offer a promising alternative but face challenges in analytical reasoning, contextual understanding, handling out-of-scope queries, and processing structured test data consistently; limitations that hinder their direct application in safety-critical scenarios. This paper introduces GateLens, an LLM-based tool for analyzing tabular data in the automotive domain. GateLens translates natural language queries into Relational Algebra (RA) expressions and then generates optimized Python code. It outperforms the baseline system on benchmarking datasets, achieving higher F1 scores and handling complex and ambiguous queries with greater robustness. Ablation studies confirm the critical role of the RA module, with performance dropping sharply when omitted. Industrial evaluations reveal that GateLens reduces analysis time by over 80% while maintaining high accuracy and reliability. As demonstrated by presented results, GateLens achieved high performance without relying on few-shot examples, showcasing strong generalization across various query types from diverse company roles. Insights from deploying GateLens with a partner automotive company offer practical guidance for integrating AI into critical workflows such as release validation. Results show that by automating test result analysis, GateLens enables faster, more informed, and dependable release decisions, and can thus advance software scalability and reliability in automotive systems.
Automating a Complete Software Test Process Using LLMs: An Automotive Case Study
Feb 06, 2025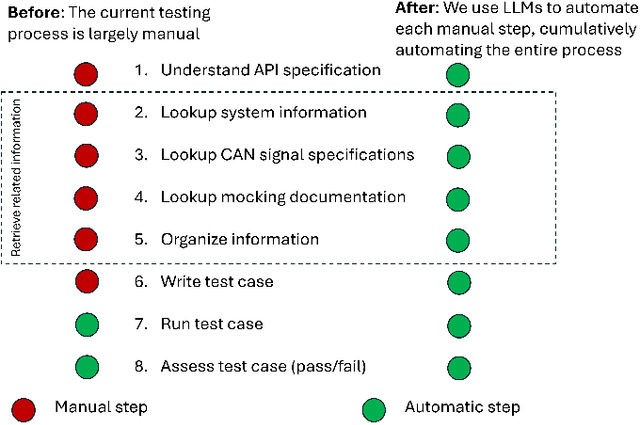
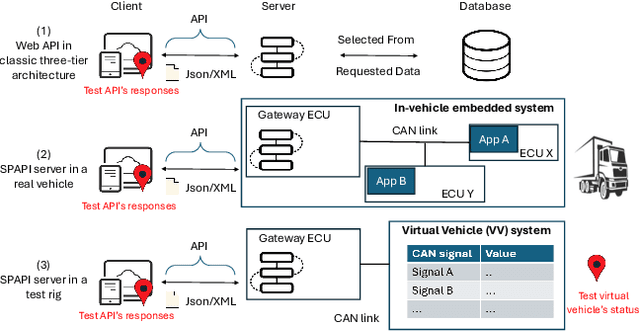
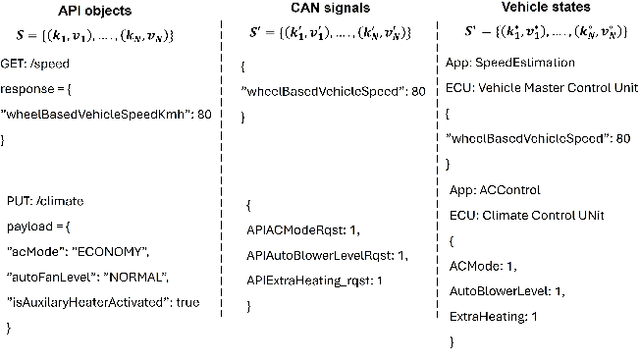
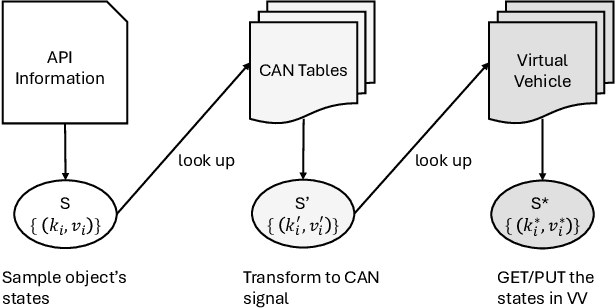
Vehicle API testing verifies whether the interactions between a vehicle's internal systems and external applications meet expectations, ensuring that users can access and control various vehicle functions and data. However, this task is inherently complex, requiring the alignment and coordination of API systems, communication protocols, and even vehicle simulation systems to develop valid test cases. In practical industrial scenarios, inconsistencies, ambiguities, and interdependencies across various documents and system specifications pose significant challenges. This paper presents a system designed for the automated testing of in-vehicle APIs. By clearly defining and segmenting the testing process, we enable Large Language Models (LLMs) to focus on specific tasks, ensuring a stable and controlled testing workflow. Experiments conducted on over 100 APIs demonstrate that our system effectively automates vehicle API testing. The results also confirm that LLMs can efficiently handle mundane tasks requiring human judgment, making them suitable for complete automation in similar industrial contexts.
GoNoGo: An Efficient LLM-based Multi-Agent System for Streamlining Automotive Software Release Decision-Making
Aug 19, 2024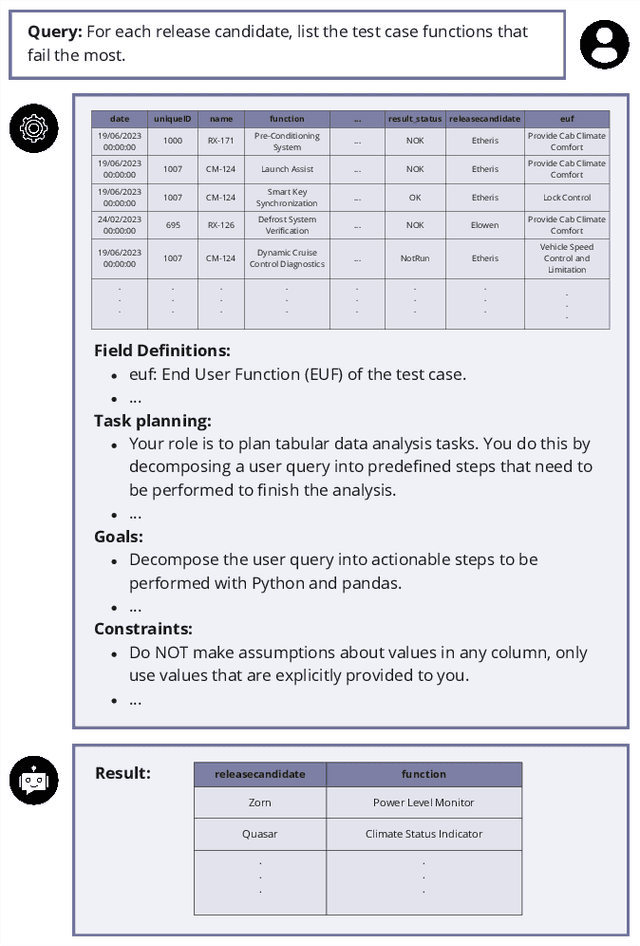
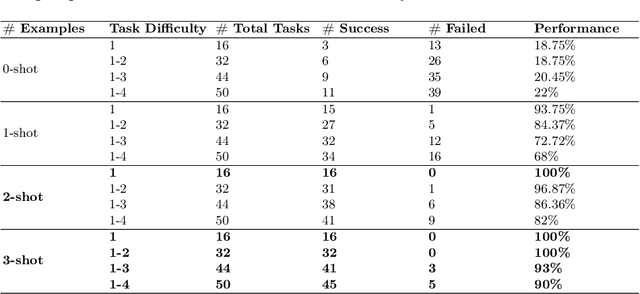

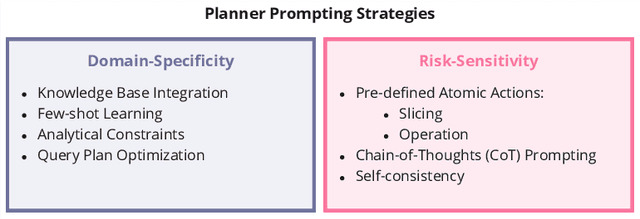
Traditional methods for making software deployment decisions in the automotive industry typically rely on manual analysis of tabular software test data. These methods often lead to higher costs and delays in the software release cycle due to their labor-intensive nature. Large Language Models (LLMs) present a promising solution to these challenges. However, their application generally demands multiple rounds of human-driven prompt engineering, which limits their practical deployment, particularly for industrial end-users who need reliable and efficient results. In this paper, we propose GoNoGo, an LLM agent system designed to streamline automotive software deployment while meeting both functional requirements and practical industrial constraints. Unlike previous systems, GoNoGo is specifically tailored to address domain-specific and risk-sensitive systems. We evaluate GoNoGo's performance across different task difficulties using zero-shot and few-shot examples taken from industrial practice. Our results show that GoNoGo achieves a 100% success rate for tasks up to Level 2 difficulty with 3-shot examples, and maintains high performance even for more complex tasks. We find that GoNoGo effectively automates decision-making for simpler tasks, significantly reducing the need for manual intervention. In summary, GoNoGo represents an efficient and user-friendly LLM-based solution currently employed in our industrial partner's company to assist with software release decision-making, supporting more informed and timely decisions in the release process for risk-sensitive vehicle systems.
SilGAN: Generating driving maneuvers for scenario-based software-in-the-loop testing
Jul 05, 2021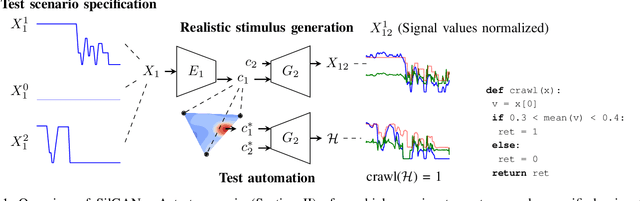

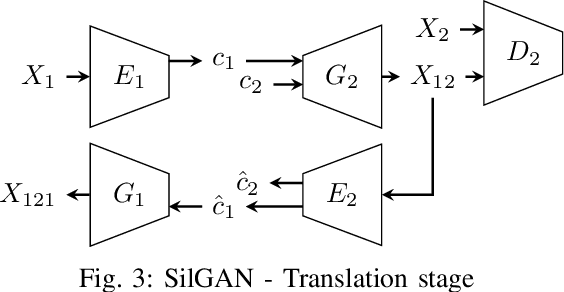

Automotive software testing continues to rely largely upon expensive field tests to ensure quality because alternatives like simulation-based testing are relatively immature. As a step towards lowering reliance on field tests, we present SilGAN, a deep generative model that eases specification, stimulus generation, and automation of automotive software-in-the-loop testing. The model is trained using data recorded from vehicles in the field. Upon training, the model uses a concise specification for a driving scenario to generate realistic vehicle state transitions that can occur during such a scenario. Such authentic emulation of internal vehicle behavior can be used for rapid, systematic and inexpensive testing of vehicle control software. In addition, by presenting a targeted method for searching through the information learned by the model, we show how a test objective like code coverage can be automated. The data driven end-to-end testing pipeline that we present vastly expands the scope and credibility of automotive simulation-based testing. This reduces time to market while helping maintain required standards of quality.
Does the dataset meet your expectations? Explaining sample representation in image data
Dec 06, 2020
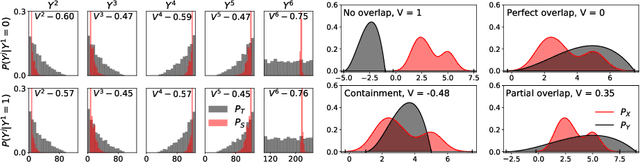
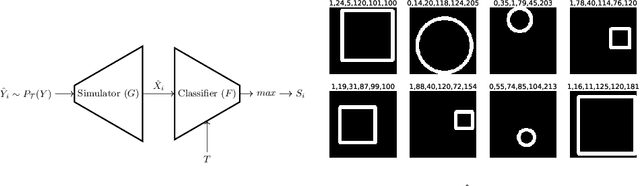
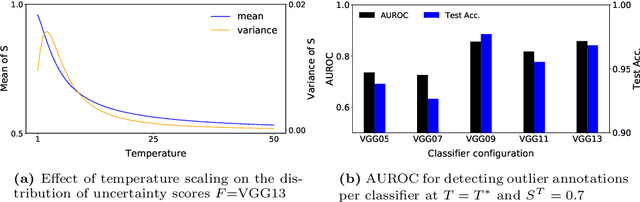
Since the behavior of a neural network model is adversely affected by a lack of diversity in training data, we present a method that identifies and explains such deficiencies. When a dataset is labeled, we note that annotations alone are capable of providing a human interpretable summary of sample diversity. This allows explaining any lack of diversity as the mismatch found when comparing the \textit{actual} distribution of annotations in the dataset with an \textit{expected} distribution of annotations, specified manually to capture essential label diversity. While, in many practical cases, labeling (samples $\rightarrow$ annotations) is expensive, its inverse, simulation (annotations $\rightarrow$ samples) can be cheaper. By mapping the expected distribution of annotations into test samples using parametric simulation, we present a method that explains sample representation using the mismatch in diversity between simulated and collected data. We then apply the method to examine a dataset of geometric shapes to qualitatively and quantitatively explain sample representation in terms of comprehensible aspects such as size, position, and pixel brightness.
Controlled time series generation for automotive software-in-the-loop testing using GANs
Feb 18, 2020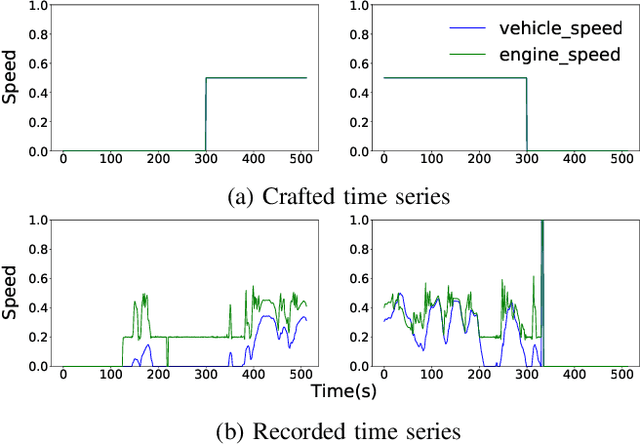
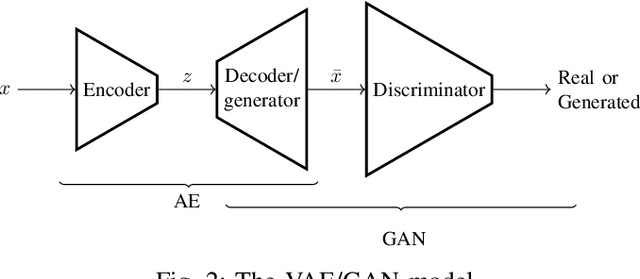
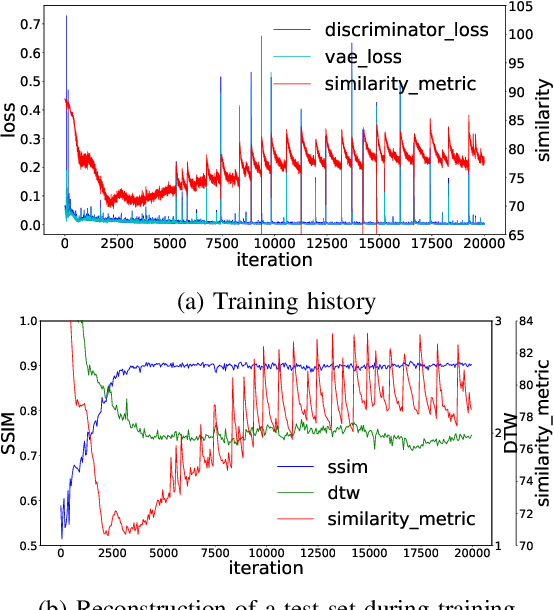
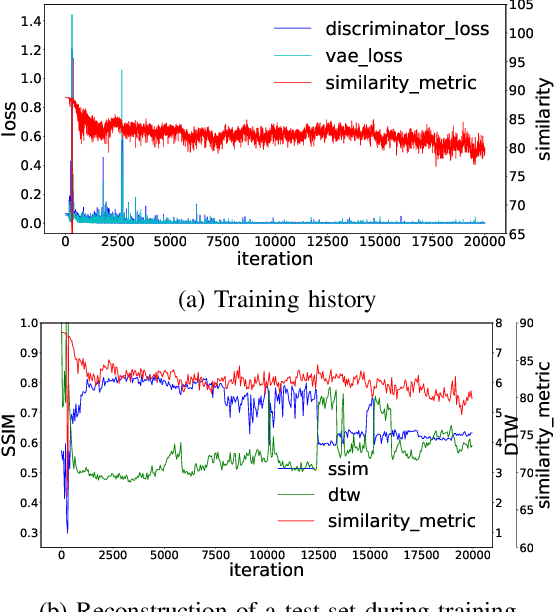
Testing automotive mechatronic systems partly uses the software-in-the-loop approach, where systematically covering inputs of the system-under-test remains a major challenge. In current practice, there are two major techniques of input stimulation. One approach is to craft input sequences which eases control and feedback of the test process but falls short of exposing the system to realistic scenarios. The other is to replay sequences recorded from field operations which accounts for reality but requires collecting a well-labeled dataset of sufficient capacity for widespread use, which is expensive. This work applies the well-known unsupervised learning framework of Generative Adversarial Networks (GAN) to learn an unlabeled dataset of recorded in-vehicle signals and uses it for generation of synthetic input stimuli. Additionally, a metric-based linear interpolation algorithm is demonstrated, which guarantees that generated stimuli follow a customizable similarity relationship with specified references. This combination of techniques enables controlled generation of a rich range of meaningful and realistic input patterns, improving virtual test coverage and reducing the need for expensive field tests.