 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain-Invariant Prompt Learning for Vision-Language Models
Mar 30, 2026Large pre-trained vision-language models like CLIP have transformed computer vision by aligning images and text in a shared feature space, enabling robust zero-shot transfer via prompting. Soft-prompting, such as Context Optimization (CoOp), effectively adapts these models for downstream recognition tasks by learning a set of context vectors. However, CoOp lacks explicit mechanisms for handling domain shifts across unseen distributions. To address this, we propose Domain-invariant Context Optimization (DiCoOp), an extension of CoOp optimized for domain generalization. By employing an adversarial training approach, DiCoOp forces the model to learn domain-invariant prompts while preserving discriminative power for classification. Experimental results show that DiCoOp consistently surpasses CoOp in domain generalization tasks across diverse visual domains.
DomAgent: Leveraging Knowledge Graphs and Case-Based Reasoning for Domain-Specific Code Generation
Mar 22, 2026Large language models (LLMs) have shown impressive capabilities in code generation. However, because most LLMs are trained on public domain corpora, directly applying them to real-world software development often yields low success rates, as these scenarios frequently require domain-specific knowledge. In particular, domain-specific tasks usually demand highly specialized solutions, which are often underrepresented or entirely absent in the training data of generic LLMs. To address this challenge, we propose DomAgent, an autonomous coding agent that bridges this gap by enabling LLMs to generate domain-adapted code through structured reasoning and targeted retrieval. A core component of DomAgent is DomRetriever, a novel retrieval module that emulates how humans learn domain-specific knowledge, by combining conceptual understanding with experiential examples. It dynamically integrates top-down knowledge-graph reasoning with bottom-up case-based reasoning, enabling iterative retrieval and synthesis of structured knowledge and representative cases to ensure contextual relevance and broad task coverage. DomRetriever can operate as part of DomAgent or independently with any LLM for flexible domain adaptation. We evaluate DomAgent on an open benchmark dataset in the data science domain (DS-1000) and further apply it to real-world truck software development tasks. Experimental results show that DomAgent significantly enhances domain-specific code generation, enabling small open-source models to close much of the performance gap with large proprietary LLMs in complex, real-world applications. The code is available at: https://github.com/Wangshuaiia/DomAgent.
GateLens: A Reasoning-Enhanced LLM Agent for Automotive Software Release Analytics
Mar 27, 2025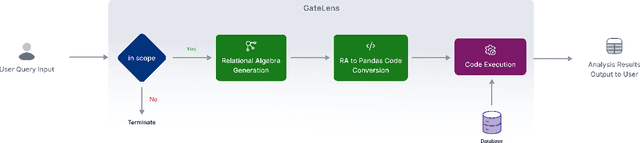


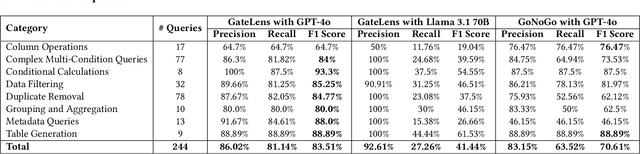
Ensuring the reliability and effectiveness of software release decisions is critical, particularly in safety-critical domains like automotive systems. Precise analysis of release validation data, often presented in tabular form, plays a pivotal role in this process. However, traditional methods that rely on manual analysis of extensive test datasets and validation metrics are prone to delays and high costs. Large Language Models (LLMs) offer a promising alternative but face challenges in analytical reasoning, contextual understanding, handling out-of-scope queries, and processing structured test data consistently; limitations that hinder their direct application in safety-critical scenarios. This paper introduces GateLens, an LLM-based tool for analyzing tabular data in the automotive domain. GateLens translates natural language queries into Relational Algebra (RA) expressions and then generates optimized Python code. It outperforms the baseline system on benchmarking datasets, achieving higher F1 scores and handling complex and ambiguous queries with greater robustness. Ablation studies confirm the critical role of the RA module, with performance dropping sharply when omitted. Industrial evaluations reveal that GateLens reduces analysis time by over 80% while maintaining high accuracy and reliability. As demonstrated by presented results, GateLens achieved high performance without relying on few-shot examples, showcasing strong generalization across various query types from diverse company roles. Insights from deploying GateLens with a partner automotive company offer practical guidance for integrating AI into critical workflows such as release validation. Results show that by automating test result analysis, GateLens enables faster, more informed, and dependable release decisions, and can thus advance software scalability and reliability in automotive systems.
Capturing Semantic Flow of ML-based Systems
Mar 13, 2025ML-based systems are software systems that incorporates machine learning components such as Deep Neural Networks (DNNs) or Large Language Models (LLMs). While such systems enable advanced features such as high performance computer vision, natural language processing, and code generation, their internal behaviour remain largely opaque to traditional dynamic analysis such as testing: existing analysis typically concern only what is observable from the outside, such as input similarity or class label changes. We propose semantic flow, a concept designed to capture the internal behaviour of ML-based system and to provide a platform for traditional dynamic analysis techniques to be adapted to. Semantic flow combines the idea of control flow with internal states taken from executions of ML-based systems, such as activation values of a specific layer in a DNN, or embeddings of LLM responses at a specific inference step of LLM agents. The resulting representation, summarised as semantic flow graphs, can capture internal decisions that are not explicitly represented in the traditional control flow of ML-based systems. We propose the idea of semantic flow, introduce two examples using a DNN and an LLM agent, and finally sketch its properties and how it can be used to adapt existing dynamic analysis techniques for use in ML-based software systems.
Automating a Complete Software Test Process Using LLMs: An Automotive Case Study
Feb 06, 2025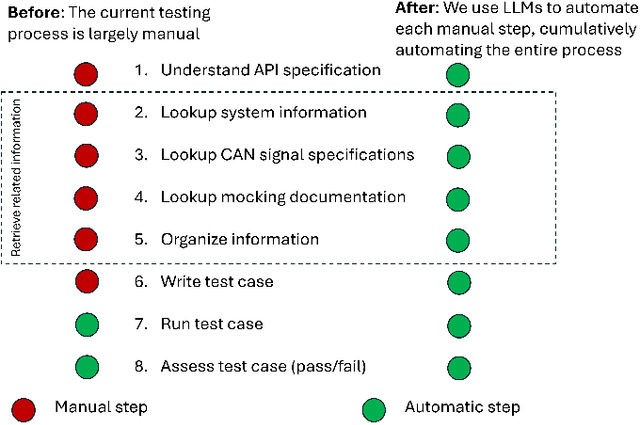
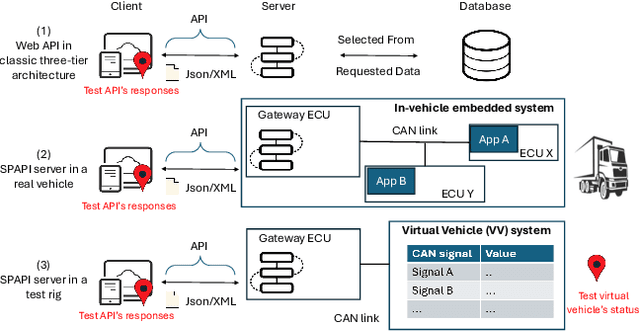
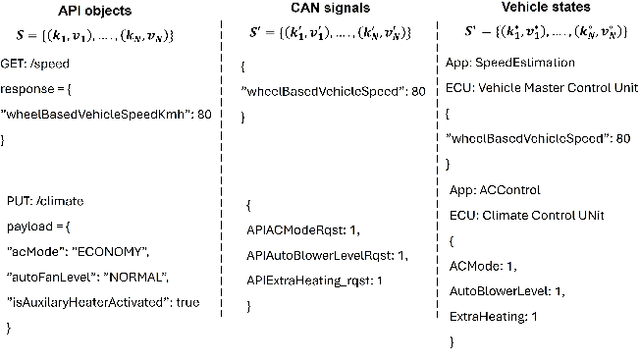
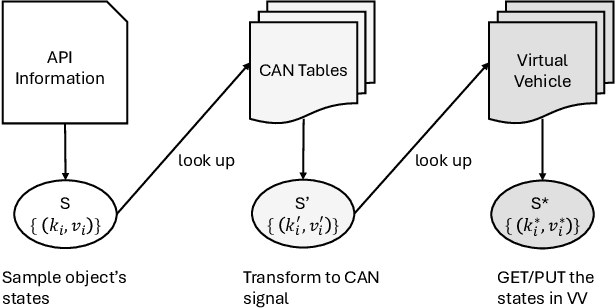
Vehicle API testing verifies whether the interactions between a vehicle's internal systems and external applications meet expectations, ensuring that users can access and control various vehicle functions and data. However, this task is inherently complex, requiring the alignment and coordination of API systems, communication protocols, and even vehicle simulation systems to develop valid test cases. In practical industrial scenarios, inconsistencies, ambiguities, and interdependencies across various documents and system specifications pose significant challenges. This paper presents a system designed for the automated testing of in-vehicle APIs. By clearly defining and segmenting the testing process, we enable Large Language Models (LLMs) to focus on specific tasks, ensuring a stable and controlled testing workflow. Experiments conducted on over 100 APIs demonstrate that our system effectively automates vehicle API testing. The results also confirm that LLMs can efficiently handle mundane tasks requiring human judgment, making them suitable for complete automation in similar industrial contexts.
GoNoGo: An Efficient LLM-based Multi-Agent System for Streamlining Automotive Software Release Decision-Making
Aug 19, 2024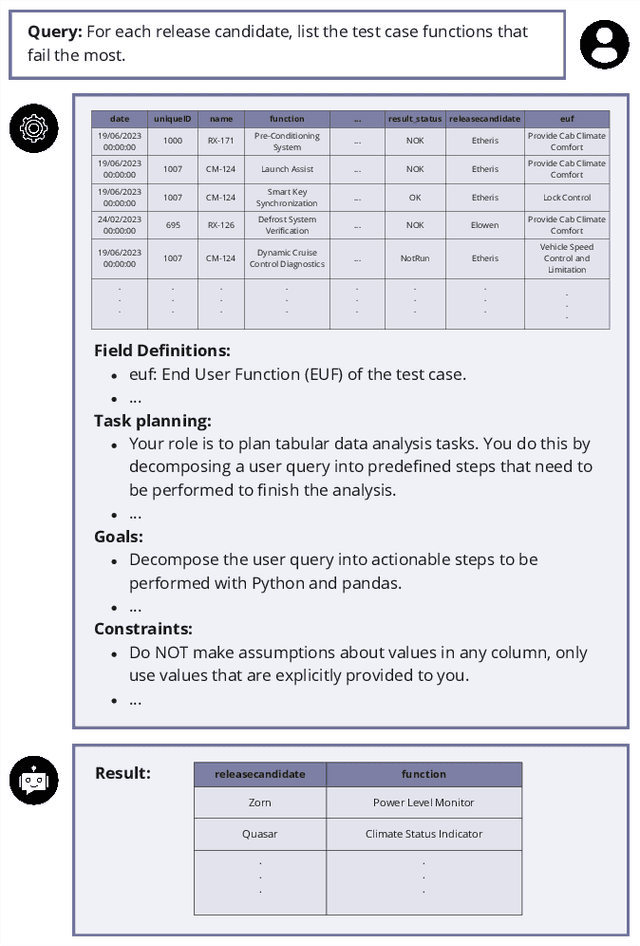
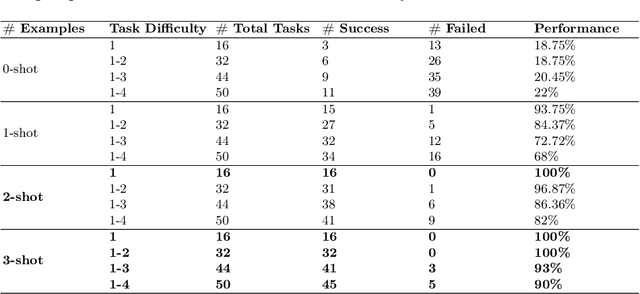

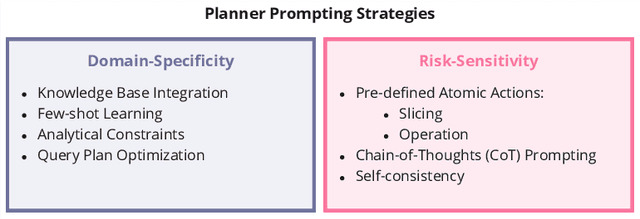
Traditional methods for making software deployment decisions in the automotive industry typically rely on manual analysis of tabular software test data. These methods often lead to higher costs and delays in the software release cycle due to their labor-intensive nature. Large Language Models (LLMs) present a promising solution to these challenges. However, their application generally demands multiple rounds of human-driven prompt engineering, which limits their practical deployment, particularly for industrial end-users who need reliable and efficient results. In this paper, we propose GoNoGo, an LLM agent system designed to streamline automotive software deployment while meeting both functional requirements and practical industrial constraints. Unlike previous systems, GoNoGo is specifically tailored to address domain-specific and risk-sensitive systems. We evaluate GoNoGo's performance across different task difficulties using zero-shot and few-shot examples taken from industrial practice. Our results show that GoNoGo achieves a 100% success rate for tasks up to Level 2 difficulty with 3-shot examples, and maintains high performance even for more complex tasks. We find that GoNoGo effectively automates decision-making for simpler tasks, significantly reducing the need for manual intervention. In summary, GoNoGo represents an efficient and user-friendly LLM-based solution currently employed in our industrial partner's company to assist with software release decision-making, supporting more informed and timely decisions in the release process for risk-sensitive vehicle systems.
Towards Explainable Test Case Prioritisation with Learning-to-Rank Models
May 22, 2024Test case prioritisation (TCP) is a critical task in regression testing to ensure quality as software evolves. Machine learning has become a common way to achieve it. In particular, learning-to-rank (LTR) algorithms provide an effective method of ordering and prioritising test cases. However, their use poses a challenge in terms of explainability, both globally at the model level and locally for particular results. Here, we present and discuss scenarios that require different explanations and how the particularities of TCP (multiple builds over time, test case and test suite variations, etc.) could influence them. We include a preliminary experiment to analyse the similarity of explanations, showing that they do not only vary depending on test case-specific predictions, but also on the relative ranks.
* 3rd International Workshop on Artificial Intelligence in Software Testing (AIST) - International Conference on Software Testing and Validation (ICST)
Domain Generalization through Meta-Learning: A Survey
Apr 03, 2024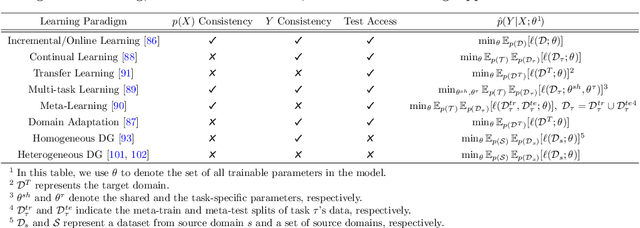

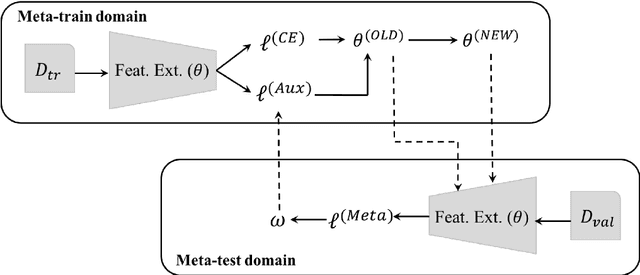
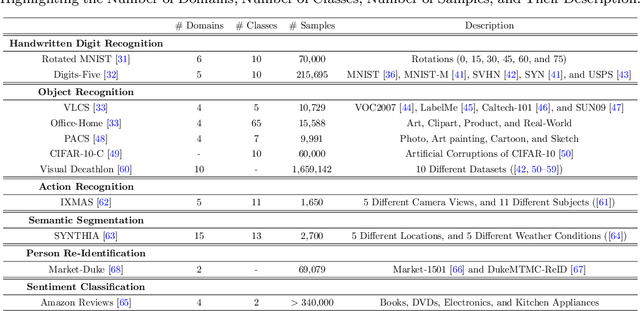
Deep neural networks (DNNs) have revolutionized artificial intelligence but often lack performance when faced with out-of-distribution (OOD) data, a common scenario due to the inevitable domain shifts in real-world applications. This limitation stems from the common assumption that training and testing data share the same distribution-an assumption frequently violated in practice. Despite their effectiveness with large amounts of data and computational power, DNNs struggle with distributional shifts and limited labeled data, leading to overfitting and poor generalization across various tasks and domains. Meta-learning presents a promising approach by employing algorithms that acquire transferable knowledge across various tasks for fast adaptation, eliminating the need to learn each task from scratch. This survey paper delves into the realm of meta-learning with a focus on its contribution to domain generalization. We first clarify the concept of meta-learning for domain generalization and introduce a novel taxonomy based on the feature extraction strategy and the classifier learning methodology, offering a granular view of methodologies. Through an exhaustive review of existing methods and underlying theories, we map out the fundamentals of the field. Our survey provides practical insights and an informed discussion on promising research directions, paving the way for future innovation in meta-learning for domain generalization.
Autonomous Large Language Model Agents Enabling Intent-Driven Mobile GUI Testing
Nov 15, 2023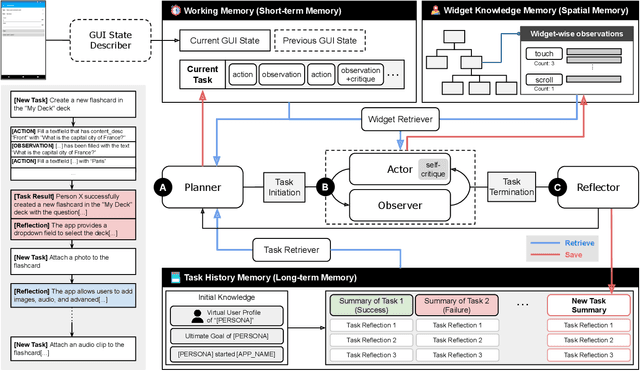



GUI testing checks if a software system behaves as expected when users interact with its graphical interface, e.g., testing specific functionality or validating relevant use case scenarios. Currently, deciding what to test at this high level is a manual task since automated GUI testing tools target lower level adequacy metrics such as structural code coverage or activity coverage. We propose DroidAgent, an autonomous GUI testing agent for Android, for semantic, intent-driven automation of GUI testing. It is based on Large Language Models and support mechanisms such as long- and short-term memory. Given an Android app, DroidAgent sets relevant task goals and subsequently tries to achieve them by interacting with the app. Our empirical evaluation of DroidAgent using 15 apps from the Themis benchmark shows that it can set up and perform realistic tasks, with a higher level of autonomy. For example, when testing a messaging app, DroidAgent created a second account and added a first account as a friend, testing a realistic use case, without human intervention. On average, DroidAgent achieved 61% activity coverage, compared to 51% for current state-of-the-art GUI testing techniques. Further, manual analysis shows that 317 out of the 374 autonomously created tasks are realistic and relevant to app functionalities, and also that DroidAgent interacts deeply with the apps and covers more features.
Test2Vec: An Execution Trace Embedding for Test Case Prioritization
Jun 28, 2022


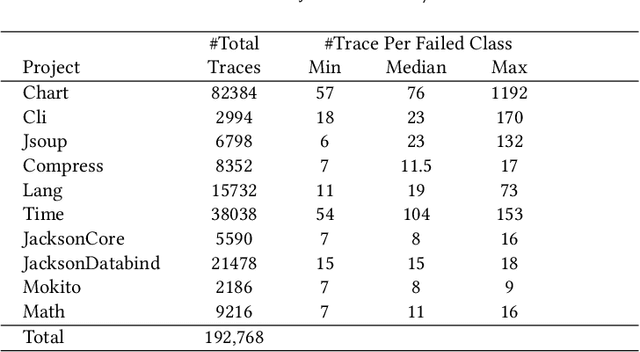
Most automated software testing tasks can benefit from the abstract representation of test cases. Traditionally, this is done by encoding test cases based on their code coverage. Specification-level criteria can replace code coverage to better represent test cases' behavior, but they are often not cost-effective. In this paper, we hypothesize that execution traces of the test cases can be a good alternative to abstract their behavior for automated testing tasks. We propose a novel embedding approach, Test2Vec, that maps test execution traces to a latent space. We evaluate this representation in the test case prioritization (TP) task. Our default TP method is based on the similarity of the embedded vectors to historical failing test vectors. We also study an alternative based on the diversity of test vectors. Finally, we propose a method to decide which TP to choose, for a given test suite. The experiment is based on several real and seeded faults with over a million execution traces. Results show that our proposed TP improves best alternatives by 41.80% in terms of the median normalized rank of the first failing test case (FFR). It outperforms traditional code coverage-based approaches by 25.05% and 59.25% in terms of median APFD and median normalized FFR.