 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Integration of Machine Learning into Automated Test Generation: A Systematic Literature Review
Jun 23, 2022
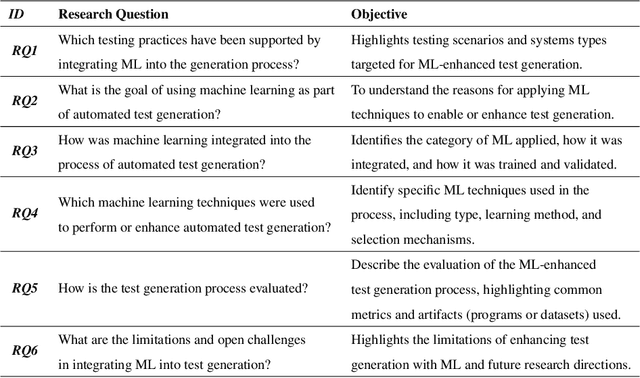
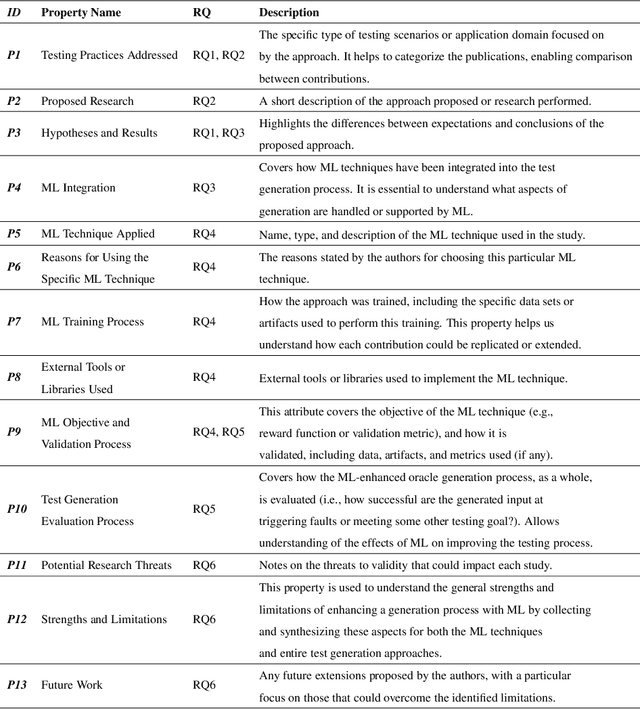
Context: Machine learning (ML) may enable effective automated test generation. Objective: We characterize emerging research, examining testing practices, researcher goals, ML techniques applied, evaluation, and challenges. Methods: We perform a systematic literature review on a sample of 97 publications. Results: ML generates input for system, GUI, unit, performance, and combinatorial testing or improves the performance of existing generation methods. ML is also used to generate test verdicts, property-based, and expected output oracles. Supervised learning - often based on neural networks - and reinforcement learning - often based on Q-learning - are common, and some publications also employ unsupervised or semi-supervised learning. (Semi-/Un-)Supervised approaches are evaluated using both traditional testing metrics and ML-related metrics (e.g., accuracy), while reinforcement learning is often evaluated using testing metrics tied to the reward function. Conclusion: Work-to-date shows great promise, but there are open challenges regarding training data, retraining, scalability, evaluation complexity, ML algorithms employed - and how they are applied - benchmarks, and replicability. Our findings can serve as a roadmap and inspiration for researchers in this field.
Automated Support for Unit Test Generation: A Tutorial Book Chapter
Oct 26, 2021


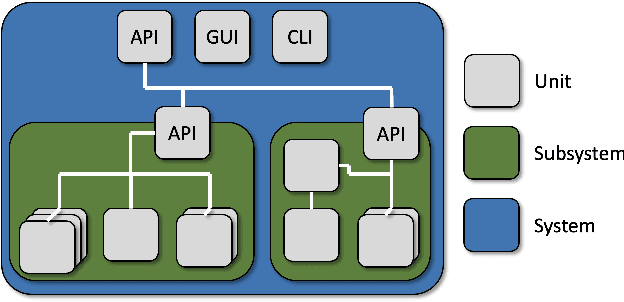
Unit testing is a stage of testing where the smallest segment of code that can be tested in isolation from the rest of the system - often a class - is tested. Unit tests are typically written as executable code, often in a format provided by a unit testing framework such as pytest for Python. Creating unit tests is a time and effort-intensive process with many repetitive, manual elements. To illustrate how AI can support unit testing, this chapter introduces the concept of search-based unit test generation. This technique frames the selection of test input as an optimization problem - we seek a set of test cases that meet some measurable goal of a tester - and unleashes powerful metaheuristic search algorithms to identify the best possible test cases within a restricted timeframe. This chapter introduces two algorithms that can generate pytest-formatted unit tests, tuned towards coverage of source code statements. The chapter concludes by discussing more advanced concepts and gives pointers to further reading for how artificial intelligence can support developers and testers when unit testing software.
Efficient and Effective Generation of Test Cases for Pedestrian Detection -- Search-based Software Testing of Baidu Apollo in SVL
Sep 16, 2021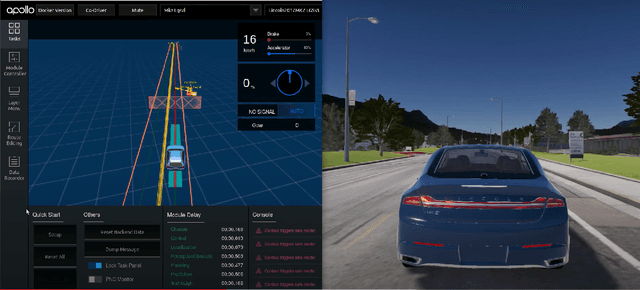
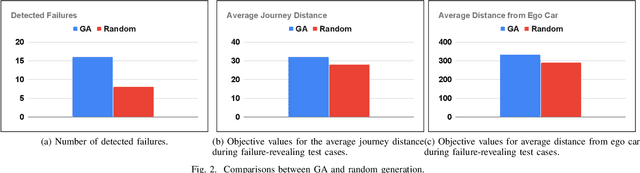

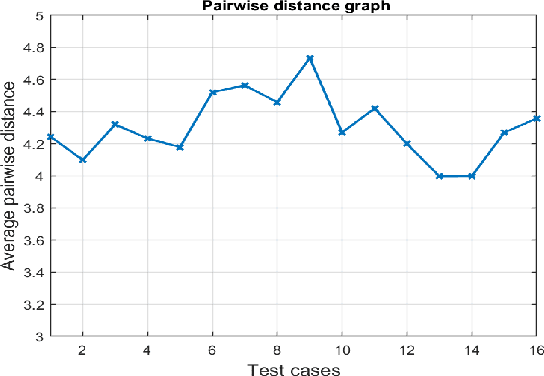
With the growing capabilities of autonomous vehicles, there is a higher demand for sophisticated and pragmatic quality assurance approaches for machine learning-enabled systems in the automotive AI context. The use of simulation-based prototyping platforms provides the possibility for early-stage testing, enabling inexpensive testing and the ability to capture critical corner-case test scenarios. Simulation-based testing properly complements conventional on-road testing. However, due to the large space of test input parameters in these systems, the efficient generation of effective test scenarios leading to the unveiling of failures is a challenge. This paper presents a study on testing pedestrian detection and emergency braking system of the Baidu Apollo autonomous driving platform within the SVL simulator. We propose an evolutionary automated test generation technique that generates failure-revealing scenarios for Apollo in the SVL environment. Our approach models the input space using a generic and flexible data structure and benefits a multi-criteria safety-based heuristic for the objective function targeted for optimization. This paper presents the results of our proposed test generation technique in the 2021 IEEE Autonomous Driving AI Test Challenge. In order to demonstrate the efficiency and effectiveness of our approach, we also report the results from a baseline random generation technique. Our evaluation shows that the proposed evolutionary test case generator is more effective at generating failure-revealing test cases and provides higher diversity between the generated failures than the random baseline.
Mapping Research Topics in Software Testing: A Bibliometric Analysis
Sep 09, 2021

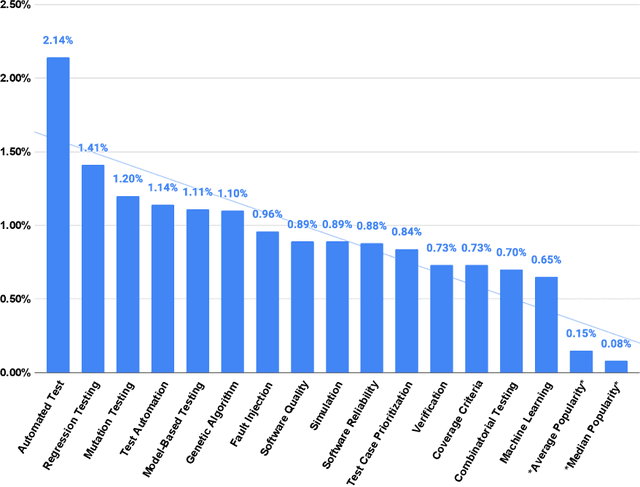

In this study, we apply co-word analysis - a text mining technique based on the co-occurrence of terms - to map the topology of software testing research topics, with the goal of providing current and prospective researchers with a map, and observations about the evolution, of the software testing field. Our analysis enables the mapping of software testing research into clusters of connected topics, from which emerge a total of 16 high-level research themes and a further 18 subthemes. This map also suggests topics that are growing in importance, including topics related to web and mobile applications and artificial intelligence. Exploration of author and country-based collaboration patterns offers similar insight into the implicit and explicit factors that influence collaboration and suggests emerging sources of collaboration for future work. We make our observations - and the underlying mapping of research topics and research collaborations - available so that researchers can gain a deeper understanding of the topology of the software testing field, inspiration regarding new areas and connections to explore, and collaborators who will broaden their perspectives.
Learning How to Search: Generating Effective Test Cases Through Adaptive Fitness Function Selection
Feb 09, 2021



Search-based test generation is guided by feedback from one or more fitness functions - scoring functions that judge solution optimality. Choosing informative fitness functions is crucial to meeting the goals of a tester. Unfortunately, many goals - such as forcing the class-under-test to throw exceptions, increasing test suite diversity, and attaining Strong Mutation Coverage - do not have effective fitness function formulations. We propose that meeting such goals requires treating fitness function identification as a secondary optimization step. An adaptive algorithm that can vary the selection of fitness functions could adjust its selection throughout the generation process to maximize goal attainment, based on the current population of test suites. To test this hypothesis, we have implemented two reinforcement learning algorithms in the EvoSuite unit test generation framework, and used these algorithms to dynamically set the fitness functions used during generation for the three goals identified above. We have evaluated our framework, EvoSuiteFIT, on a set of real Java case examples. EvoSuiteFIT techniques attain significant improvements for two of the three goals, and show small improvements on the third when the number of generations of evolution is fixed. Additionally, for all goals, EvoSuiteFIT detects faults missed by the other techniques. The ability to adjust fitness functions allows EvoSuiteFIT to make strategic choices that efficiently produce more effective test suites, and examining its choices offers insight into how to attain our testing goals. We find that AFFS is a powerful technique to apply when an effective fitness function does not already exist for generating tests to achieve a testing goal.
Understanding the Nature of System-Related Issues in Machine Learning Frameworks: An Exploratory Study
May 13, 2020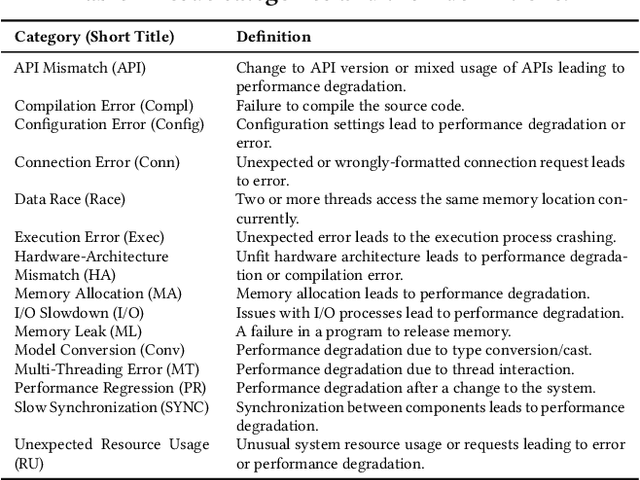
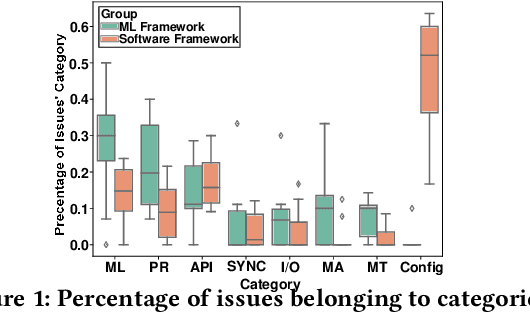
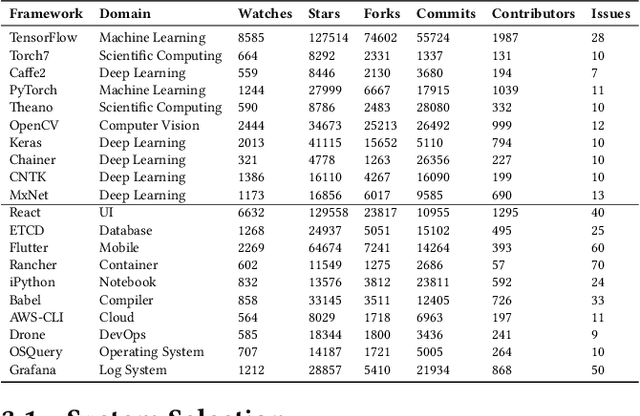
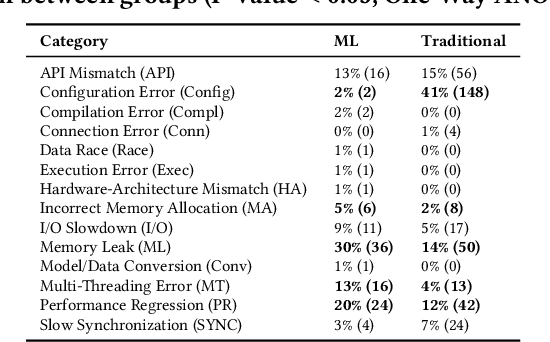
Modern systems are built using development frameworks. These frameworks have a major impact on how the resulting system executes, how configurations are managed, how it is tested, and how and where it is deployed. Machine learning (ML) frameworks and the systems developed using them differ greatly from traditional frameworks. Naturally, the issues that manifest in such frameworks may differ as well---as may the behavior of developers addressing those issues. We are interested in characterizing the system-related issues---issues impacting performance, memory and resource usage, and other quality attributes---that emerge in ML frameworks, and how they differ from those in traditional frameworks. We have conducted a moderate-scale exploratory study analyzing real-world system-related issues from 10 popular machine learning frameworks. Our findings offer implications for the development of machine learning systems, including differences in the frequency of occurrence of certain issue types, observations regarding the impact of debate and time on issue correction, and differences in the specialization of developers. We hope that this exploratory study will enable developers to improve their expectations, plan for risk, and allocate resources accordingly when making use of the tools provided by these frameworks to develop ML-based systems.