 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlleviating Attack Data Scarcity: SCANIA's Experience Towards Enhancing In-Vehicle Cyber Security Measures
Jul 03, 2025The digital evolution of connected vehicles and the subsequent security risks emphasize the critical need for implementing in-vehicle cyber security measures such as intrusion detection and response systems. The continuous advancement of attack scenarios further highlights the need for adaptive detection mechanisms that can detect evolving, unknown, and complex threats. The effective use of ML-driven techniques can help address this challenge. However, constraints on implementing diverse attack scenarios on test vehicles due to safety, cost, and ethical considerations result in a scarcity of data representing attack scenarios. This limitation necessitates alternative efficient and effective methods for generating high-quality attack-representing data. This paper presents a context-aware attack data generator that generates attack inputs and corresponding in-vehicle network log, i.e., controller area network (CAN) log, representing various types of attack including denial of service (DoS), fuzzy, spoofing, suspension, and replay attacks. It utilizes parameterized attack models augmented with CAN message decoding and attack intensity adjustments to configure the attack scenarios with high similarity to real-world scenarios and promote variability. We evaluate the practicality of the generated attack-representing data within an intrusion detection system (IDS) case study, in which we develop and perform an empirical evaluation of two deep neural network IDS models using the generated data. In addition to the efficiency and scalability of the approach, the performance results of IDS models, high detection and classification capabilities, validate the consistency and effectiveness of the generated data as well. In this experience study, we also elaborate on the aspects influencing the fidelity of the data to real-world scenarios and provide insights into its application.
Enabling Smart Retrofitting and Performance Anomaly Detection for a Sensorized Vessel: A Maritime Industry Experience
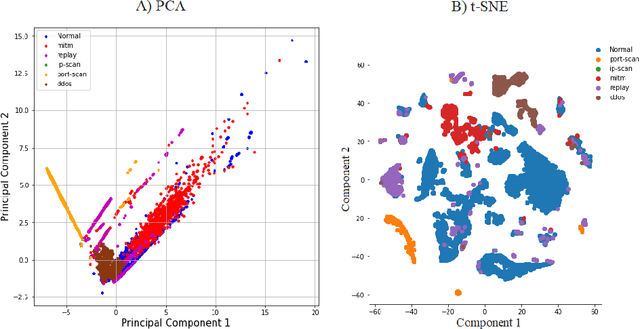
Dec 30, 2023The integration of sensorized vessels, enabling real-time data collection and machine learning-driven data analysis marks a pivotal advancement in the maritime industry. This transformative technology not only can enhance safety, efficiency, and sustainability but also usher in a new era of cost-effective and smart maritime transportation in our increasingly interconnected world. This study presents a deep learning-driven anomaly detection system augmented with interpretable machine learning models for identifying performance anomalies in an industrial sensorized vessel, called TUCANA. We Leverage a human-in-the-loop unsupervised process that involves utilizing standard and Long Short-Term Memory (LSTM) autoencoders augmented with interpretable surrogate models, i.e., random forest and decision tree, to add transparency and interpretability to the results provided by the deep learning models. The interpretable models also enable automated rule generation for translating the inference into human-readable rules. Additionally, the process also includes providing a projection of the results using t-distributed stochastic neighbor embedding (t-SNE), which helps with a better understanding of the structure and relationships within the data and assessment of the identified anomalies. We empirically evaluate the system using real data acquired from the vessel TUCANA and the results involve achieving over 80% precision and 90% recall with the LSTM model used in the process. The interpretable models also provide logical rules aligned with expert thinking, and the t-SNE-based projection enhances interpretability. Our system demonstrates that the proposed approach can be used effectively in real-world scenarios, offering transparency and precision in performance anomaly detection.
Anomaly Detection Dataset for Industrial Control Systems
May 11, 2023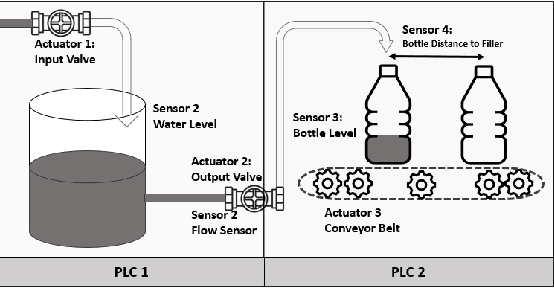


Over the past few decades, Industrial Control Systems (ICSs) have been targeted by cyberattacks and are becoming increasingly vulnerable as more ICSs are connected to the internet. Using Machine Learning (ML) for Intrusion Detection Systems (IDS) is a promising approach for ICS cyber protection, but the lack of suitable datasets for evaluating ML algorithms is a challenge. Although there are a few commonly used datasets, they may not reflect realistic ICS network data, lack necessary features for effective anomaly detection, or be outdated. This paper presents the 'ICS-Flow' dataset, which offers network data and process state variables logs for supervised and unsupervised ML-based IDS assessment. The network data includes normal and anomalous network packets and flows captured from simulated ICS components and emulated networks. The anomalies were injected into the system through various attack techniques commonly used by hackers to modify network traffic and compromise ICSs. We also proposed open-source tools, `ICSFlowGenerator' for generating network flow parameters from Raw network packets. The final dataset comprises over 25,000,000 raw network packets, network flow records, and process variable logs. The paper describes the methodology used to collect and label the dataset and provides a detailed data analysis. Finally, we implement several ML models, including the decision tree, random forest, and artificial neural network to detect anomalies and attacks, demonstrating that our dataset can be used effectively for training intrusion detection ML models.
Ergo, SMIRK is Safe: A Safety Case for a Machine Learning Component in a Pedestrian Automatic Emergency Brake System
Apr 16, 2022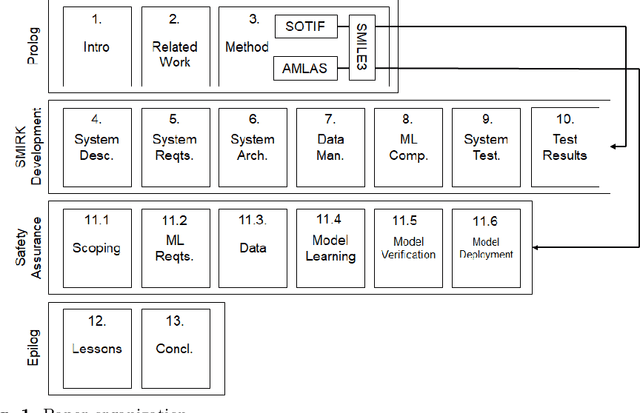
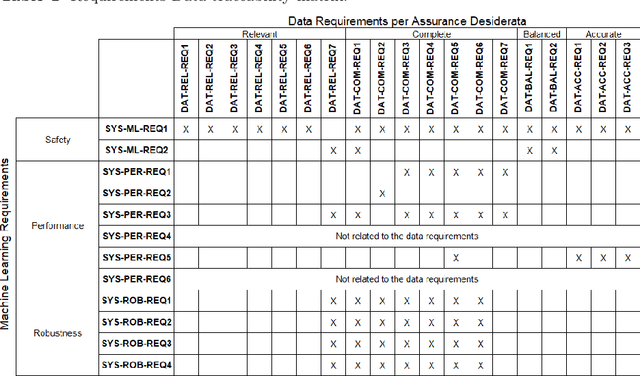
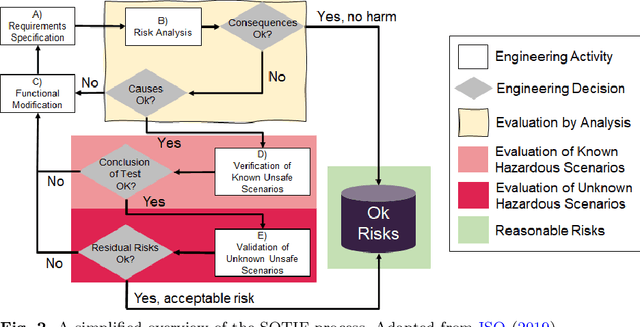
Integration of Machine Learning (ML) components in critical applications introduces novel challenges for software certification and verification. New safety standards and technical guidelines are under development to support the safety of ML-based systems, e.g., ISO 21448 SOTIF for the automotive domain and the Assurance of Machine Learning for use in Autonomous Systems (AMLAS) framework. SOTIF and AMLAS provide high-level guidance but the details must be chiseled out for each specific case. We report results from an industry-academia collaboration on safety assurance of SMIRK, an ML-based pedestrian automatic emergency braking demonstrator running in an industry-grade simulator. We present the outcome of applying AMLAS on SMIRK for a minimalistic operational design domain, i.e., a complete safety case for its integrated ML-based component. Finally, we report lessons learned and provide both SMIRK and the safety case under an open-source licence for the research community to reuse.
Machine Learning Testing in an ADAS Case Study Using Simulation-Integrated Bio-Inspired Search-Based Testing
Mar 22, 2022
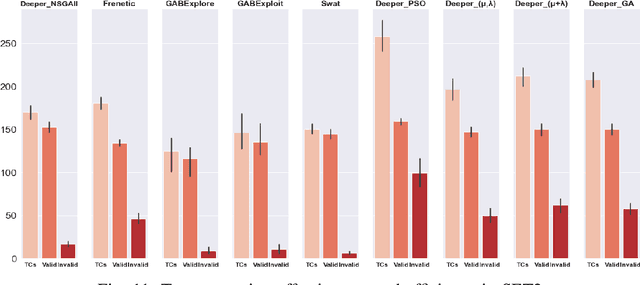


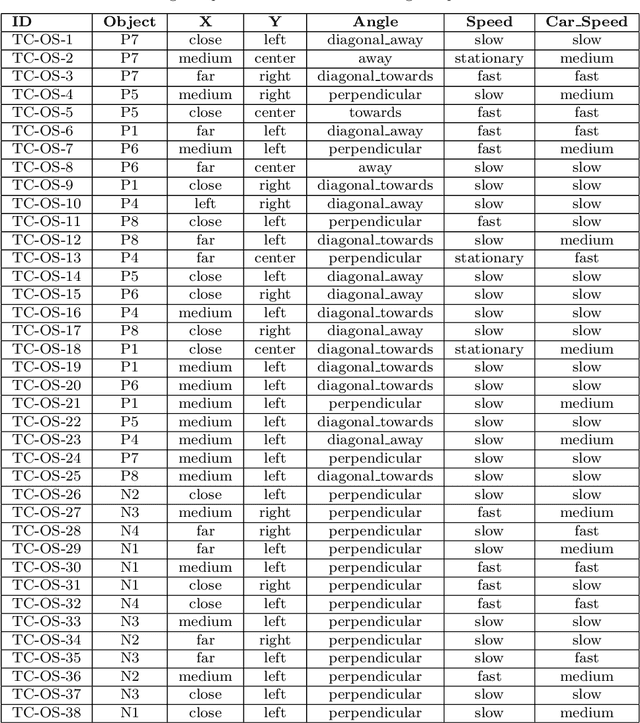
This paper presents an extended version of Deeper, a search-based simulation-integrated test solution that generates failure-revealing test scenarios for testing a deep neural network-based lane-keeping system. In the newly proposed version, we utilize a new set of bio-inspired search algorithms, genetic algorithm (GA), $({\mu}+{\lambda})$ and $({\mu},{\lambda})$ evolution strategies (ES), and particle swarm optimization (PSO), that leverage a quality population seed and domain-specific cross-over and mutation operations tailored for the presentation model used for modeling the test scenarios. In order to demonstrate the capabilities of the new test generators within Deeper, we carry out an empirical evaluation and comparison with regard to the results of five participating tools in the cyber-physical systems testing competition at SBST 2021. Our evaluation shows the newly proposed test generators in Deeper not only represent a considerable improvement on the previous version but also prove to be effective and efficient in provoking a considerable number of diverse failure-revealing test scenarios for testing an ML-driven lane-keeping system. They can trigger several failures while promoting test scenario diversity, under a limited test time budget, high target failure severity, and strict speed limit constraints.
HMS-OS: Improving the Human Mental Search Optimisation Algorithm by Grouping in both Search and Objective Space
Dec 03, 2021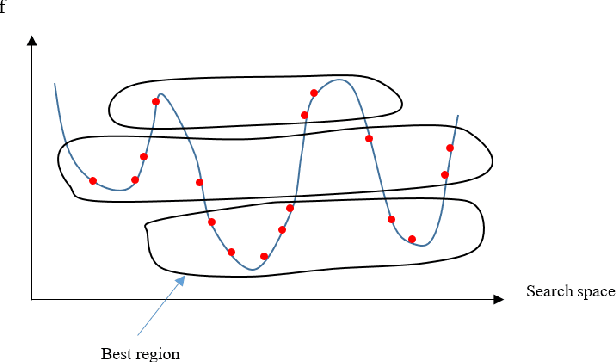
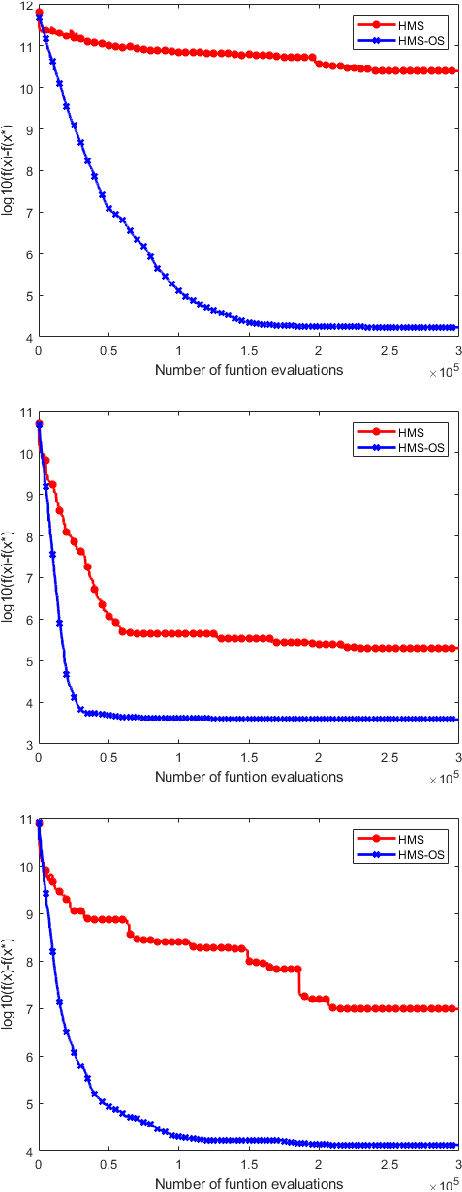
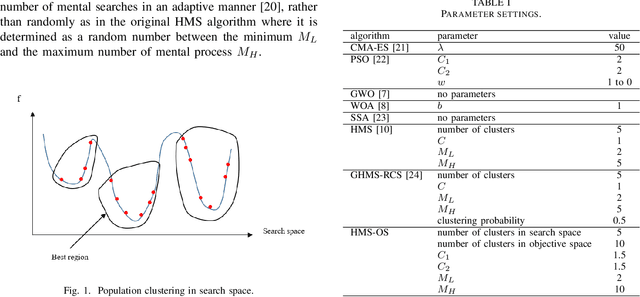

The human mental search (HMS) algorithm is a relatively recent population-based metaheuristic algorithm, which has shown competitive performance in solving complex optimisation problems. It is based on three main operators: mental search, grouping, and movement. In the original HMS algorithm, a clustering algorithm is used to group the current population in order to identify a promising region in search space, while candidate solutions then move towards the best candidate solution in the promising region. In this paper, we propose a novel HMS algorithm, HMS-OS, which is based on clustering in both objective and search space, where clustering in objective space finds a set of best candidate solutions whose centroid is then also used in updating the population. For further improvement, HMSOS benefits from an adaptive selection of the number of mental processes in the mental search operator. Experimental results on CEC-2017 benchmark functions with dimensionalities of 50 and 100, and in comparison to other optimisation algorithms, indicate that HMS-OS yields excellent performance, superior to those of other methods.
An LSTM-based Plagiarism Detection via Attention Mechanism and a Population-based Approach for Pre-Training Parameters with imbalanced Classes
Oct 17, 2021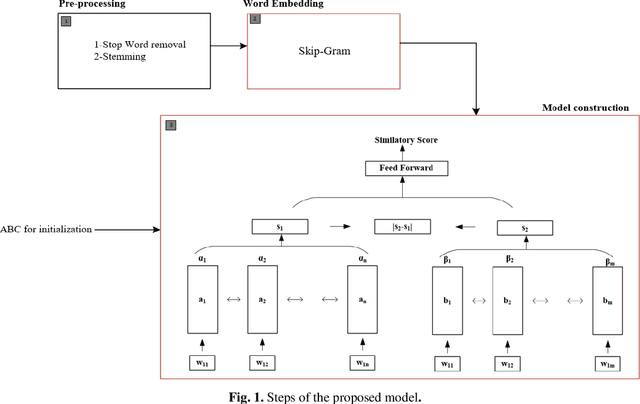
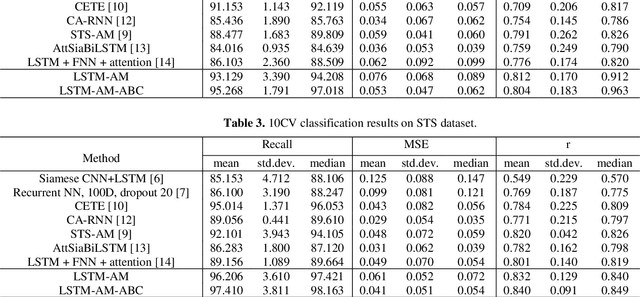
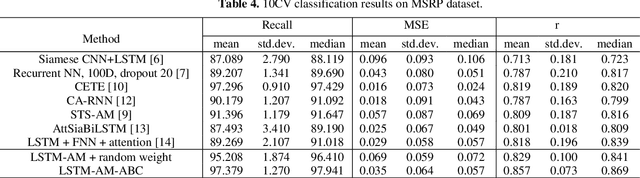

Plagiarism is one of the leading problems in academic and industrial environments, which its goal is to find the similar items in a typical document or source code. This paper proposes an architecture based on a Long Short-Term Memory (LSTM) and attention mechanism called LSTM-AM-ABC boosted by a population-based approach for parameter initialization. Gradient-based optimization algorithms such as back-propagation (BP) are widely used in the literature for learning process in LSTM, attention mechanism, and feed-forward neural network, while they suffer from some problems such as getting stuck in local optima. To tackle this problem, population-based metaheuristic (PBMH) algorithms can be used. To this end, this paper employs a PBMH algorithm, artificial bee colony (ABC), to moderate the problem. Our proposed algorithm can find the initial values for model learning in all LSTM, attention mechanism, and feed-forward neural network, simultaneously. In other words, ABC algorithm finds a promising point for starting BP algorithm. For evaluation, we compare our proposed algorithm with both conventional and population-based methods. The results clearly show that the proposed method can provide competitive performance.
An Enhanced Differential Evolution Algorithm Using a Novel Clustering-based Mutation Operator
Sep 20, 2021
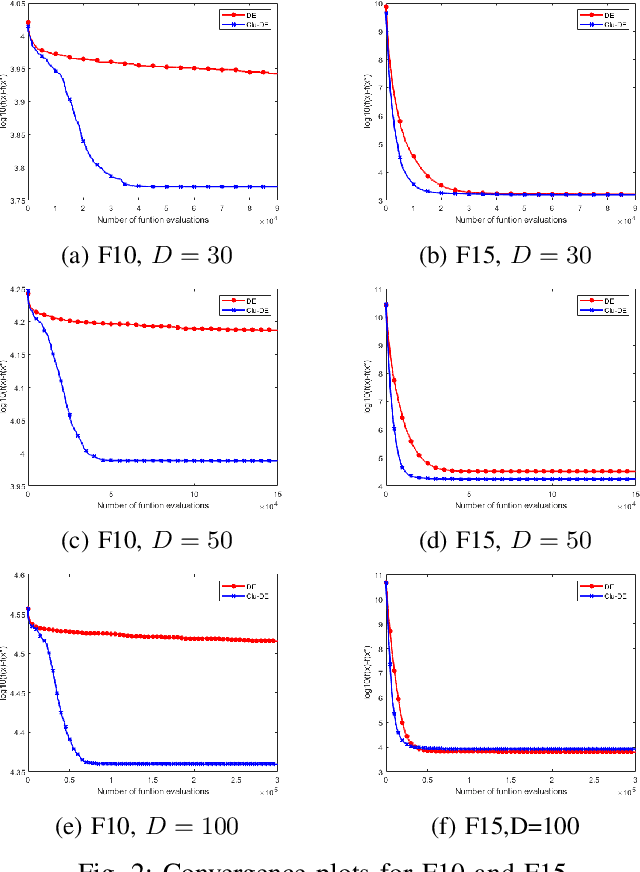


Differential evolution (DE) is an effective population-based metaheuristic algorithm for solving complex optimisation problems. However, the performance of DE is sensitive to the mutation operator. In this paper, we propose a novel DE algorithm, Clu-DE, that improves the efficacy of DE using a novel clustering-based mutation operator. First, we find, using a clustering algorithm, a winner cluster in search space and select the best candidate solution in this cluster as the base vector in the mutation operator. Then, an updating scheme is introduced to include new candidate solutions in the current population. Experimental results on CEC-2017 benchmark functions with dimensionalities of 30, 50 and 100 confirm that Clu-DE yields improved performance compared to DE.
Efficient and Effective Generation of Test Cases for Pedestrian Detection -- Search-based Software Testing of Baidu Apollo in SVL
Sep 16, 2021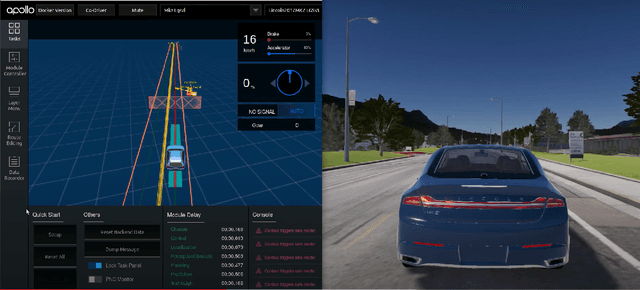
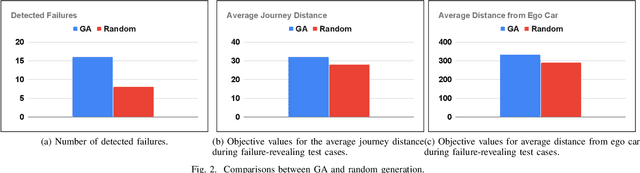

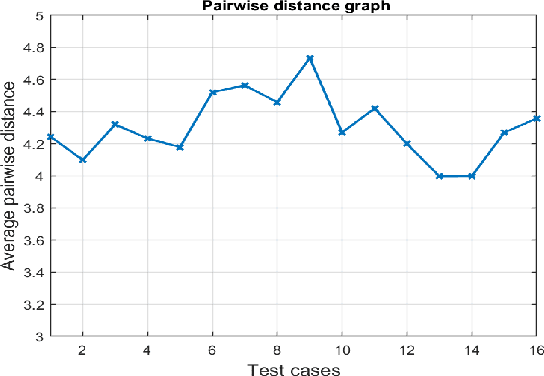
With the growing capabilities of autonomous vehicles, there is a higher demand for sophisticated and pragmatic quality assurance approaches for machine learning-enabled systems in the automotive AI context. The use of simulation-based prototyping platforms provides the possibility for early-stage testing, enabling inexpensive testing and the ability to capture critical corner-case test scenarios. Simulation-based testing properly complements conventional on-road testing. However, due to the large space of test input parameters in these systems, the efficient generation of effective test scenarios leading to the unveiling of failures is a challenge. This paper presents a study on testing pedestrian detection and emergency braking system of the Baidu Apollo autonomous driving platform within the SVL simulator. We propose an evolutionary automated test generation technique that generates failure-revealing scenarios for Apollo in the SVL environment. Our approach models the input space using a generic and flexible data structure and benefits a multi-criteria safety-based heuristic for the objective function targeted for optimization. This paper presents the results of our proposed test generation technique in the 2021 IEEE Autonomous Driving AI Test Challenge. In order to demonstrate the efficiency and effectiveness of our approach, we also report the results from a baseline random generation technique. Our evaluation shows that the proposed evolutionary test case generator is more effective at generating failure-revealing test cases and provides higher diversity between the generated failures than the random baseline.
Automated Performance Testing Based on Active Deep Learning
Apr 05, 2021
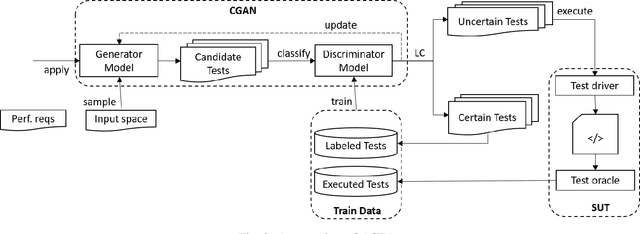
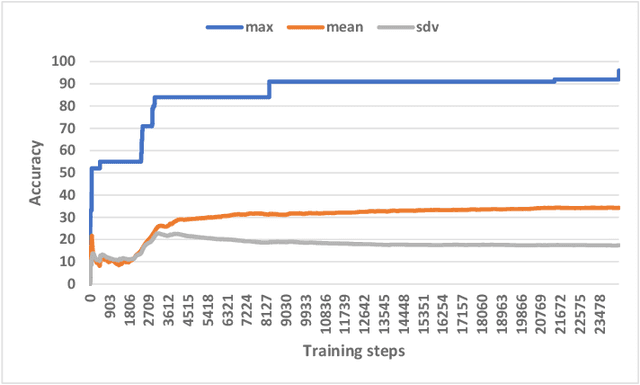
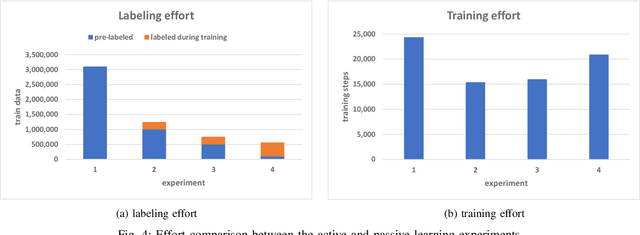
Generating tests that can reveal performance issues in large and complex software systems within a reasonable amount of time is a challenging task. On one hand, there are numerous combinations of input data values to explore. On the other hand, we have a limited test budget to execute tests. What makes this task even more difficult is the lack of access to source code and the internal details of these systems. In this paper, we present an automated test generation method called ACTA for black-box performance testing. ACTA is based on active learning, which means that it does not require a large set of historical test data to learn about the performance characteristics of the system under test. Instead, it dynamically chooses the tests to execute using uncertainty sampling. ACTA relies on a conditional variant of generative adversarial networks,and facilitates specifying performance requirements in terms of conditions and generating tests that address those conditions.We have evaluated ACTA on a benchmark web application, and the experimental results indicate that this method is comparable with random testing, and two other machine learning methods,i.e. PerfXRL and DN.