 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Integration of Machine Learning into Automated Test Generation: A Systematic Literature Review
Jun 23, 2022
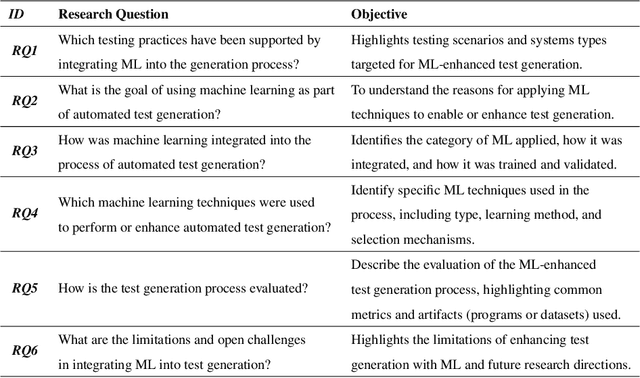
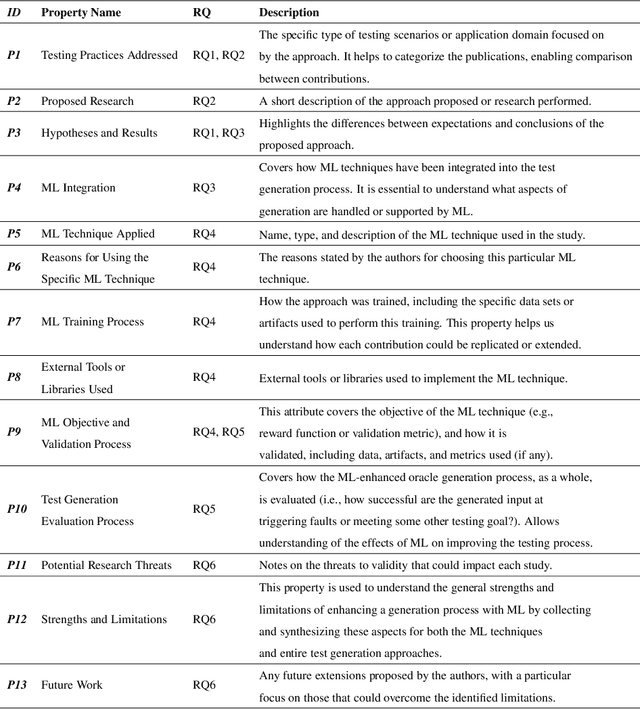
Context: Machine learning (ML) may enable effective automated test generation. Objective: We characterize emerging research, examining testing practices, researcher goals, ML techniques applied, evaluation, and challenges. Methods: We perform a systematic literature review on a sample of 97 publications. Results: ML generates input for system, GUI, unit, performance, and combinatorial testing or improves the performance of existing generation methods. ML is also used to generate test verdicts, property-based, and expected output oracles. Supervised learning - often based on neural networks - and reinforcement learning - often based on Q-learning - are common, and some publications also employ unsupervised or semi-supervised learning. (Semi-/Un-)Supervised approaches are evaluated using both traditional testing metrics and ML-related metrics (e.g., accuracy), while reinforcement learning is often evaluated using testing metrics tied to the reward function. Conclusion: Work-to-date shows great promise, but there are open challenges regarding training data, retraining, scalability, evaluation complexity, ML algorithms employed - and how they are applied - benchmarks, and replicability. Our findings can serve as a roadmap and inspiration for researchers in this field.
Visual Odometry for RGB-D Cameras
Mar 28, 2022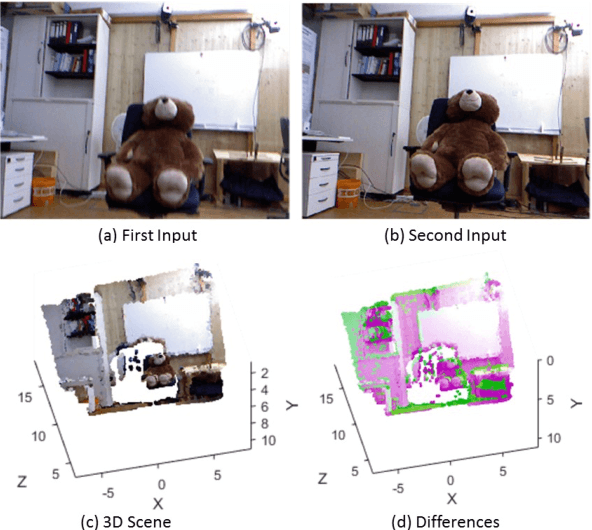

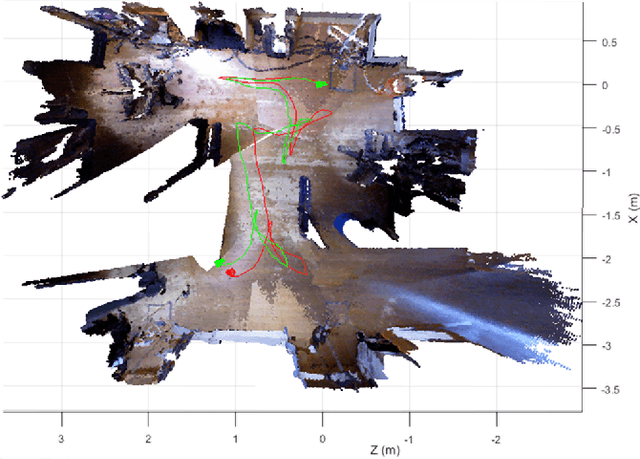

Visual odometry is the process of estimating the position and orientation of a camera by analyzing the images associated to it. This paper develops a quick and accurate approach to visual odometry of a moving RGB-D camera navigating on a static environment. The proposed algorithm uses SURF (Speeded Up Robust Features) as feature extractor, RANSAC (Random Sample Consensus) to filter the results and Minimum Mean Square to estimate the rigid transformation of six parameters between successive video frames. Data from a Kinect camera were used in the tests. The results show that this approach is feasible and promising, surpassing in performance the algorithms ICP (Interactive Closest Point) and SfM (Structure from Motion) in tests using a publicly available dataset.
Automated Support for Unit Test Generation: A Tutorial Book Chapter
Oct 26, 2021


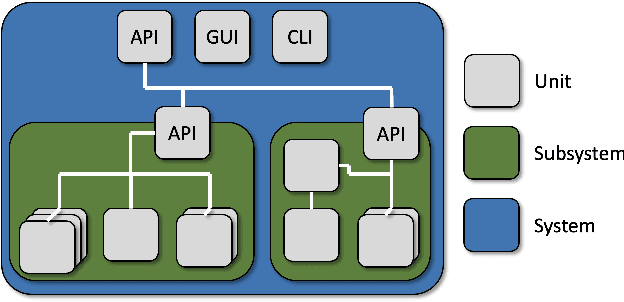
Unit testing is a stage of testing where the smallest segment of code that can be tested in isolation from the rest of the system - often a class - is tested. Unit tests are typically written as executable code, often in a format provided by a unit testing framework such as pytest for Python. Creating unit tests is a time and effort-intensive process with many repetitive, manual elements. To illustrate how AI can support unit testing, this chapter introduces the concept of search-based unit test generation. This technique frames the selection of test input as an optimization problem - we seek a set of test cases that meet some measurable goal of a tester - and unleashes powerful metaheuristic search algorithms to identify the best possible test cases within a restricted timeframe. This chapter introduces two algorithms that can generate pytest-formatted unit tests, tuned towards coverage of source code statements. The chapter concludes by discussing more advanced concepts and gives pointers to further reading for how artificial intelligence can support developers and testers when unit testing software.
Efficient and Effective Generation of Test Cases for Pedestrian Detection -- Search-based Software Testing of Baidu Apollo in SVL
Sep 16, 2021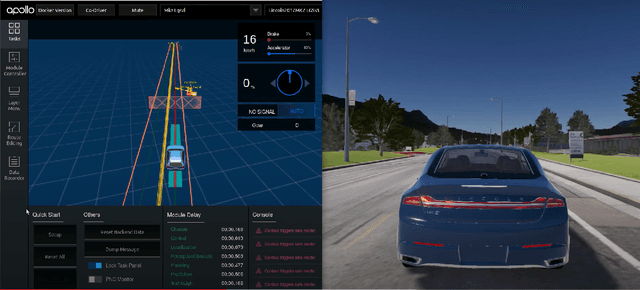
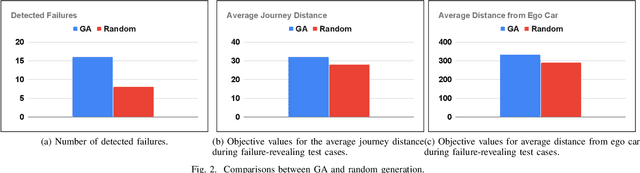

With the growing capabilities of autonomous vehicles, there is a higher demand for sophisticated and pragmatic quality assurance approaches for machine learning-enabled systems in the automotive AI context. The use of simulation-based prototyping platforms provides the possibility for early-stage testing, enabling inexpensive testing and the ability to capture critical corner-case test scenarios. Simulation-based testing properly complements conventional on-road testing. However, due to the large space of test input parameters in these systems, the efficient generation of effective test scenarios leading to the unveiling of failures is a challenge. This paper presents a study on testing pedestrian detection and emergency braking system of the Baidu Apollo autonomous driving platform within the SVL simulator. We propose an evolutionary automated test generation technique that generates failure-revealing scenarios for Apollo in the SVL environment. Our approach models the input space using a generic and flexible data structure and benefits a multi-criteria safety-based heuristic for the objective function targeted for optimization. This paper presents the results of our proposed test generation technique in the 2021 IEEE Autonomous Driving AI Test Challenge. In order to demonstrate the efficiency and effectiveness of our approach, we also report the results from a baseline random generation technique. Our evaluation shows that the proposed evolutionary test case generator is more effective at generating failure-revealing test cases and provides higher diversity between the generated failures than the random baseline.