 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Analysis of Out-of-Distribution Detection on Trained Neural Networks
Apr 26, 2022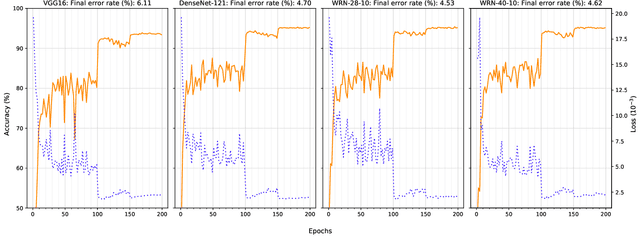
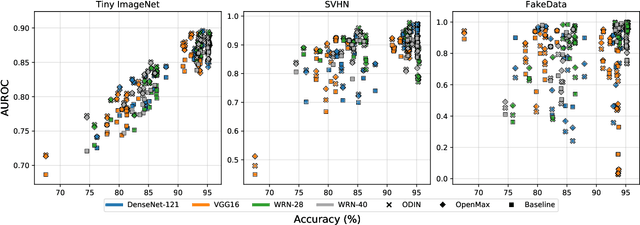
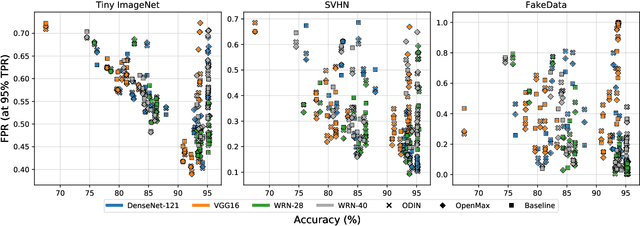
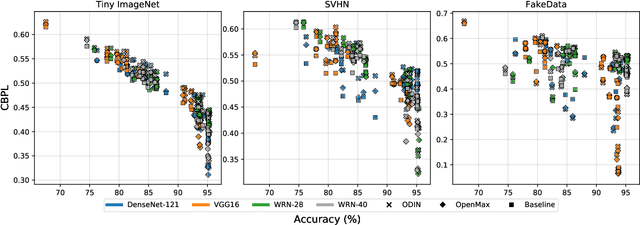
Several areas have been improved with Deep Learning during the past years. Implementing Deep Neural Networks (DNN) for non-safety related applications have shown remarkable achievements over the past years; however, for using DNNs in safety critical applications, we are missing approaches for verifying the robustness of such models. A common challenge for DNNs occurs when exposed to out-of-distribution samples that are outside of the scope of a DNN, but which result in high confidence outputs despite no prior knowledge of such input. In this paper, we analyze three methods that separate between in- and out-of-distribution data, called supervisors, on four well-known DNN architectures. We find that the outlier detection performance improves with the quality of the model. We also analyse the performance of the particular supervisors during the training procedure by applying the supervisor at a predefined interval to investigate its performance as the training proceeds. We observe that understanding the relationship between training results and supervisor performance is crucial to improve the model's robustness and to indicate, what input samples require further measures to improve the robustness of a DNN. In addition, our work paves the road towards an instrument for safety argumentation for safety critical applications. This paper is an extended version of our previous work presented at 2019 SEAA (cf. [1]); here, we elaborate on the used metrics, add an additional supervisor and test them on two additional datasets.
Ergo, SMIRK is Safe: A Safety Case for a Machine Learning Component in a Pedestrian Automatic Emergency Brake System
Apr 16, 2022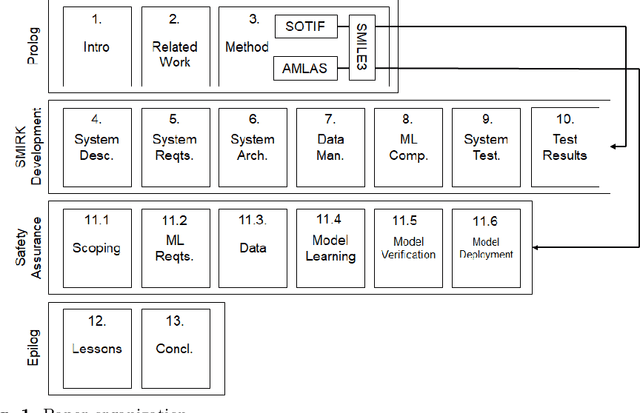
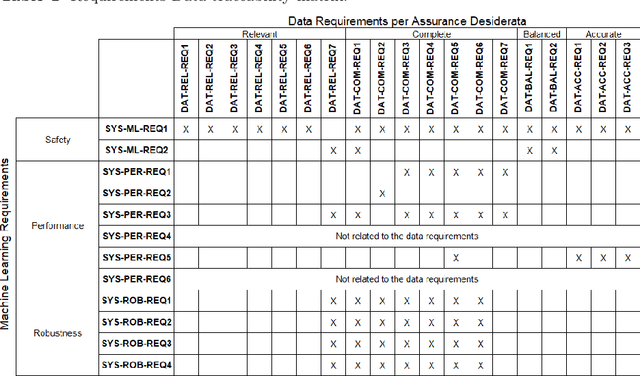
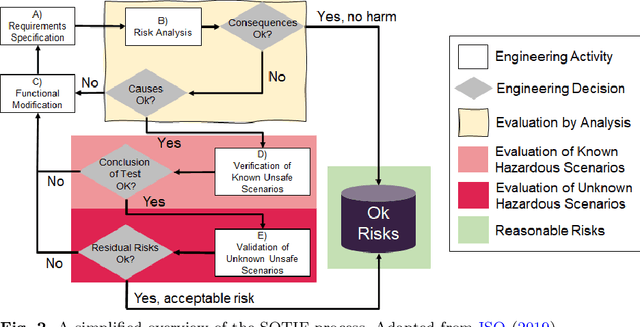
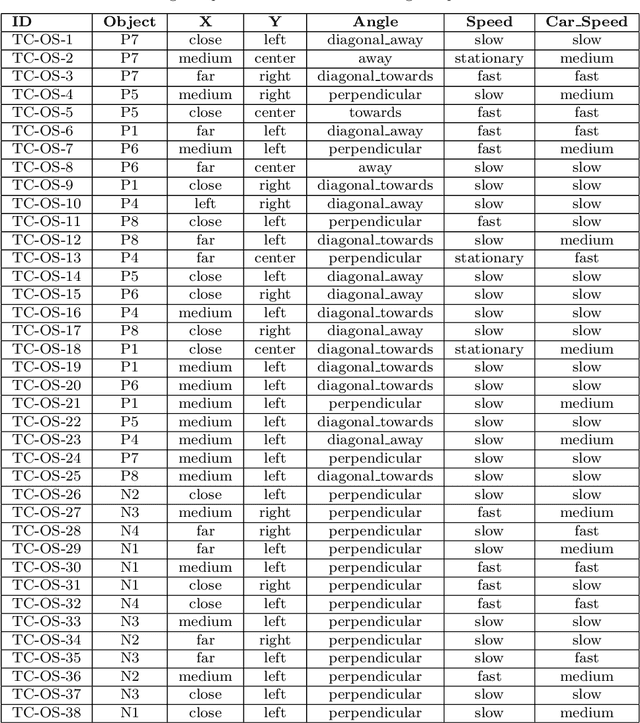
Integration of Machine Learning (ML) components in critical applications introduces novel challenges for software certification and verification. New safety standards and technical guidelines are under development to support the safety of ML-based systems, e.g., ISO 21448 SOTIF for the automotive domain and the Assurance of Machine Learning for use in Autonomous Systems (AMLAS) framework. SOTIF and AMLAS provide high-level guidance but the details must be chiseled out for each specific case. We report results from an industry-academia collaboration on safety assurance of SMIRK, an ML-based pedestrian automatic emergency braking demonstrator running in an industry-grade simulator. We present the outcome of applying AMLAS on SMIRK for a minimalistic operational design domain, i.e., a complete safety case for its integrated ML-based component. Finally, we report lessons learned and provide both SMIRK and the safety case under an open-source licence for the research community to reuse.
Performance Analysis of Out-of-Distribution Detection on Various Trained Neural Networks
Mar 29, 2021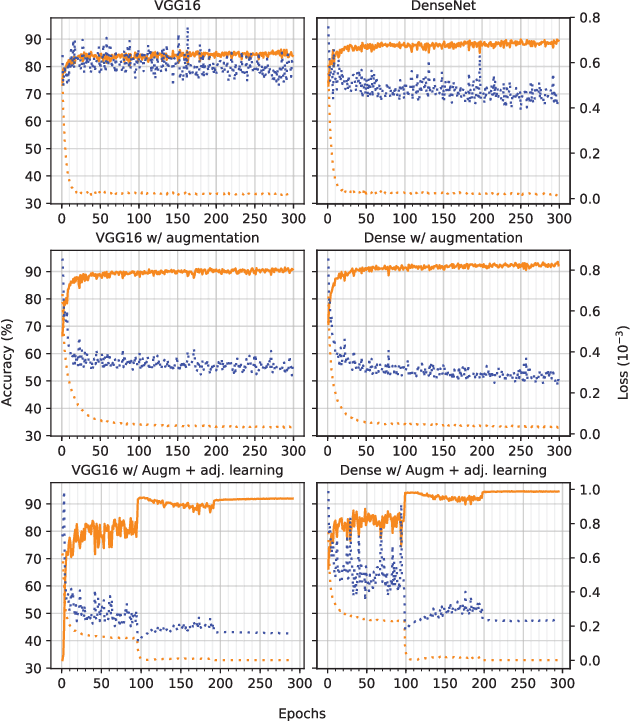
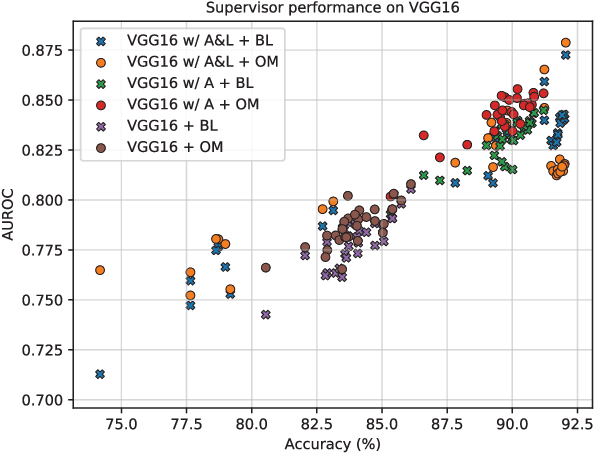
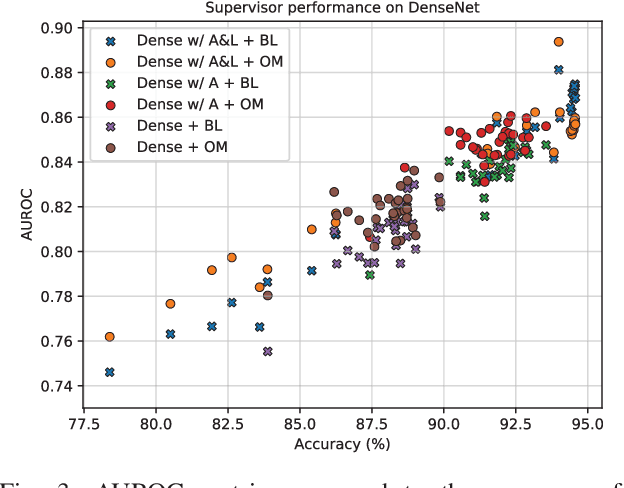
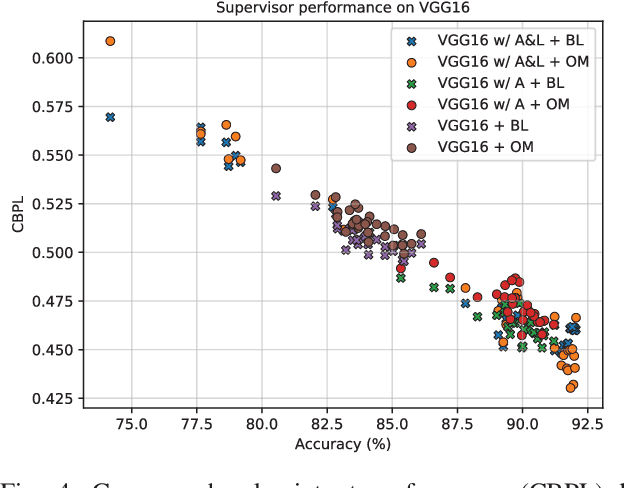
Several areas have been improved with Deep Learning during the past years. For non-safety related products adoption of AI and ML is not an issue, whereas in safety critical applications, robustness of such approaches is still an issue. A common challenge for Deep Neural Networks (DNN) occur when exposed to out-of-distribution samples that are previously unseen, where DNNs can yield high confidence predictions despite no prior knowledge of the input. In this paper we analyse two supervisors on two well-known DNNs with varied setups of training and find that the outlier detection performance improves with the quality of the training procedure. We analyse the performance of the supervisor after each epoch during the training cycle, to investigate supervisor performance as the accuracy converges. Understanding the relationship between training results and supervisor performance is valuable to improve robustness of the model and indicates where more work has to be done to create generalized models for safety critical applications.
Towards Structured Evaluation of Deep Neural Network Supervisors
Mar 07, 2019
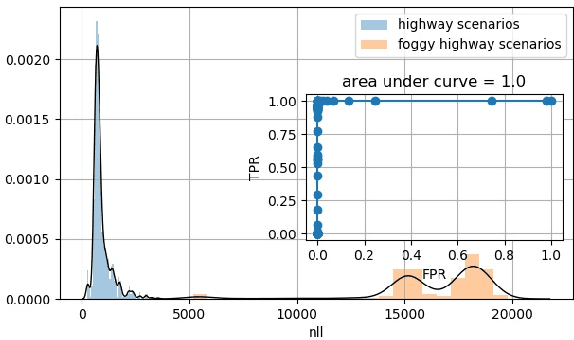
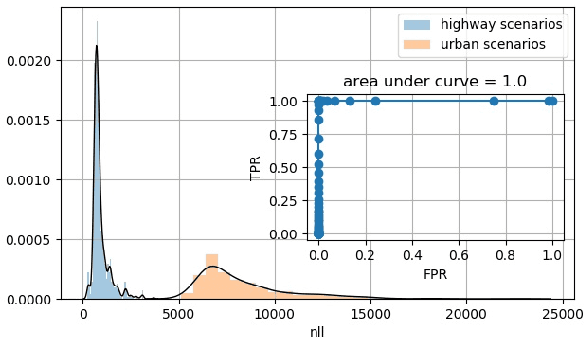

Deep Neural Networks (DNN) have improved the quality of several non-safety related products in the past years. However, before DNNs should be deployed to safety-critical applications, their robustness needs to be systematically analyzed. A common challenge for DNNs occurs when input is dissimilar to the training set, which might lead to high confidence predictions despite proper knowledge of the input. Several previous studies have proposed to complement DNNs with a supervisor that detects when inputs are outside the scope of the network. Most of these supervisors, however, are developed and tested for a selected scenario using a specific performance metric. In this work, we emphasize the need to assess and compare the performance of supervisors in a structured way. We present a framework constituted by four datasets organized in six test cases combined with seven evaluation metrics. The test cases provide varying complexity and include data from publicly available sources as well as a novel dataset consisting of images from simulated driving scenarios. The latter we plan to make publicly available. Our framework can be used to support DNN supervisor evaluation, which in turn could be used to motive development, validation, and deployment of DNNs in safety-critical applications.