 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Analysis of Out-of-Distribution Detection on Trained Neural Networks
Paper and Code
Apr 26, 2022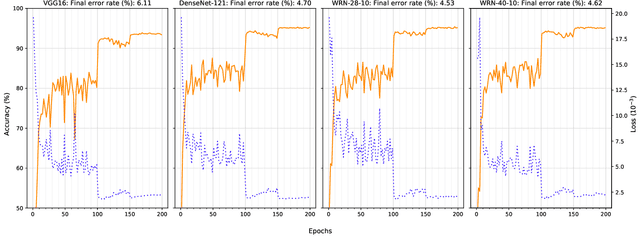
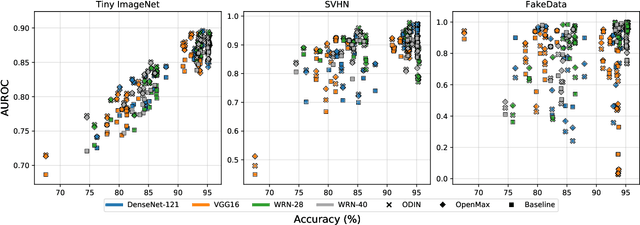
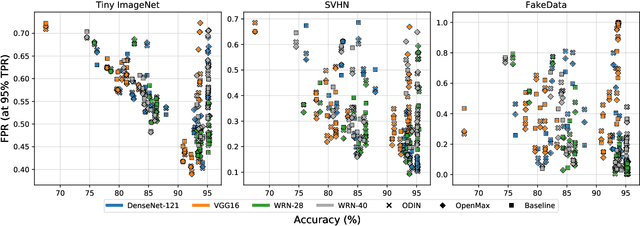
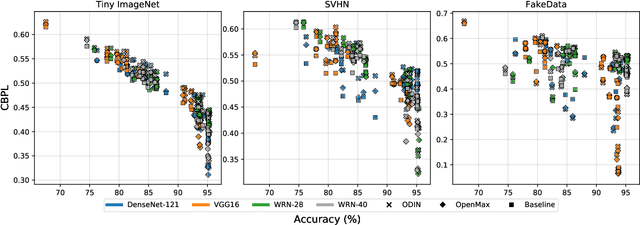
Several areas have been improved with Deep Learning during the past years. Implementing Deep Neural Networks (DNN) for non-safety related applications have shown remarkable achievements over the past years; however, for using DNNs in safety critical applications, we are missing approaches for verifying the robustness of such models. A common challenge for DNNs occurs when exposed to out-of-distribution samples that are outside of the scope of a DNN, but which result in high confidence outputs despite no prior knowledge of such input. In this paper, we analyze three methods that separate between in- and out-of-distribution data, called supervisors, on four well-known DNN architectures. We find that the outlier detection performance improves with the quality of the model. We also analyse the performance of the particular supervisors during the training procedure by applying the supervisor at a predefined interval to investigate its performance as the training proceeds. We observe that understanding the relationship between training results and supervisor performance is crucial to improve the model's robustness and to indicate, what input samples require further measures to improve the robustness of a DNN. In addition, our work paves the road towards an instrument for safety argumentation for safety critical applications. This paper is an extended version of our previous work presented at 2019 SEAA (cf. [1]); here, we elaborate on the used metrics, add an additional supervisor and test them on two additional datasets.