 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Objective Multi-Fidelity Bayesian Optimization with Causal Priors
Jan 31, 2026Multi-fidelity Bayesian optimization (MFBO) accelerates the search for the global optimum of black-box functions by integrating inexpensive, low-fidelity approximations. The central task of an MFBO policy is to balance the cost-efficiency of low-fidelity proxies against their reduced accuracy to ensure effective progression toward the high-fidelity optimum. Existing MFBO methods primarily capture associational dependencies between inputs, fidelities, and objectives, rather than causal mechanisms, and can perform poorly when lower-fidelity proxies are poorly aligned with the target fidelity. We propose RESCUE (REducing Sampling cost with Causal Understanding and Estimation), a multi-objective MFBO method that incorporates causal calculus to systematically address this challenge. RESCUE learns a structural causal model capturing causal relationships between inputs, fidelities, and objectives, and uses it to construct a probabilistic multi-fidelity (MF) surrogate that encodes intervention effects. Exploiting the causal structure, we introduce a causal hypervolume knowledge-gradient acquisition strategy to select input-fidelity pairs that balance expected multi-objective improvement and cost. We show that RESCUE improves sample efficiency over state-of-the-art MF optimization methods on synthetic and real-world problems in robotics, machine learning (AutoML), and healthcare.
An Empirical Study of Accuracy-Robustness Tradeoff and Training Efficiency in Self-Supervised Learning
Jan 07, 2025Self-supervised learning (SSL) has significantly advanced image representation learning, yet efficiency challenges persist, particularly with adversarial training. Many SSL methods require extensive epochs to achieve convergence, a demand further amplified in adversarial settings. To address this inefficiency, we revisit the robust EMP-SSL framework, emphasizing the importance of increasing the number of crops per image to accelerate learning. Unlike traditional contrastive learning, robust EMP-SSL leverages multi-crop sampling, integrates an invariance term and regularization, and reduces training epochs, enhancing time efficiency. Evaluated with both standard linear classifiers and multi-patch embedding aggregation, robust EMP-SSL provides new insights into SSL evaluation strategies. Our results show that robust crop-based EMP-SSL not only accelerates convergence but also achieves a superior balance between clean accuracy and adversarial robustness, outperforming multi-crop embedding aggregation. Additionally, we extend this approach with free adversarial training in Multi-Crop SSL, introducing the Cost-Free Adversarial Multi-Crop Self-Supervised Learning (CF-AMC-SSL) method. CF-AMC-SSL demonstrates the effectiveness of free adversarial training in reducing training time while simultaneously improving clean accuracy and adversarial robustness. These findings underscore the potential of CF-AMC-SSL for practical SSL applications. Our code is publicly available at https://github.com/softsys4ai/CF-AMC-SSL.
CURE: Simulation-Augmented Auto-Tuning in Robotics
Feb 08, 2024



Robotic systems are typically composed of various subsystems, such as localization and navigation, each encompassing numerous configurable components (e.g., selecting different planning algorithms). Once an algorithm has been selected for a component, its associated configuration options must be set to the appropriate values. Configuration options across the system stack interact non-trivially. Finding optimal configurations for highly configurable robots to achieve desired performance poses a significant challenge due to the interactions between configuration options across software and hardware that result in an exponentially large and complex configuration space. These challenges are further compounded by the need for transferability between different environments and robotic platforms. Data efficient optimization algorithms (e.g., Bayesian optimization) have been increasingly employed to automate the tuning of configurable parameters in cyber-physical systems. However, such optimization algorithms converge at later stages, often after exhausting the allocated budget (e.g., optimization steps, allotted time) and lacking transferability. This paper proposes CURE -- a method that identifies causally relevant configuration options, enabling the optimization process to operate in a reduced search space, thereby enabling faster optimization of robot performance. CURE abstracts the causal relationships between various configuration options and robot performance objectives by learning a causal model in the source (a low-cost environment such as the Gazebo simulator) and applying the learned knowledge to perform optimization in the target (e.g., Turtlebot 3 physical robot). We demonstrate the effectiveness and transferability of CURE by conducting experiments that involve varying degrees of deployment changes in both physical robots and simulation.
Software Engineering for Robotics: Future Research Directions; Report from the 2023 Workshop on Software Engineering for Robotics
Jan 22, 2024Robots are experiencing a revolution as they permeate many aspects of our daily lives, from performing house maintenance to infrastructure inspection, from efficiently warehousing goods to autonomous vehicles, and more. This technical progress and its impact are astounding. This revolution, however, is outstripping the capabilities of existing software development processes, techniques, and tools, which largely have remained unchanged for decades. These capabilities are ill-suited to handling the challenges unique to robotics software such as dealing with a wide diversity of domains, heterogeneous hardware, programmed and learned components, complex physical environments captured and modeled with uncertainty, emergent behaviors that include human interactions, and scalability demands that span across multiple dimensions. Looking ahead to the need to develop software for robots that are ever more ubiquitous, autonomous, and reliant on complex adaptive components, hardware, and data, motivated an NSF-sponsored community workshop on the subject of Software Engineering for Robotics, held in Detroit, Michigan in October 2023. The goal of the workshop was to bring together thought leaders across robotics and software engineering to coalesce a community, and identify key problems in the area of SE for robotics that that community should aim to solve over the next 5 years. This report serves to summarize the motivation, activities, and findings of that workshop, in particular by articulating the challenges unique to robot software, and identifying a vision for fruitful near-term research directions to tackle them.
IPA: Inference Pipeline Adaptation to Achieve High Accuracy and Cost-Efficiency
Aug 24, 2023Efficiently optimizing multi-model inference pipelines for fast, accurate, and cost-effective inference is a crucial challenge in ML production systems, given their tight end-to-end latency requirements. To simplify the exploration of the vast and intricate trade-off space of accuracy and cost in inference pipelines, providers frequently opt to consider one of them. However, the challenge lies in reconciling accuracy and cost trade-offs. To address this challenge and propose a solution to efficiently manage model variants in inference pipelines, we present IPA, an online deep-learning Inference Pipeline Adaptation system that efficiently leverages model variants for each deep learning task. Model variants are different versions of pre-trained models for the same deep learning task with variations in resource requirements, latency, and accuracy. IPA dynamically configures batch size, replication, and model variants to optimize accuracy, minimize costs, and meet user-defined latency SLAs using Integer Programming. It supports multi-objective settings for achieving different trade-offs between accuracy and cost objectives while remaining adaptable to varying workloads and dynamic traffic patterns. Extensive experiments on a Kubernetes implementation with five real-world inference pipelines demonstrate that IPA improves normalized accuracy by up to 35% with a minimal cost increase of less than 5%.
Independent Modular Networks
Jun 02, 2023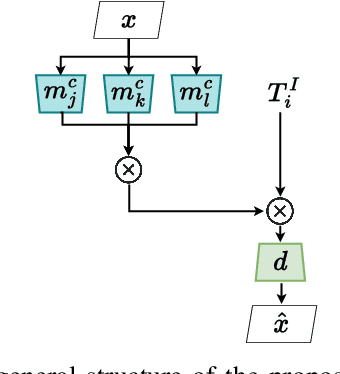
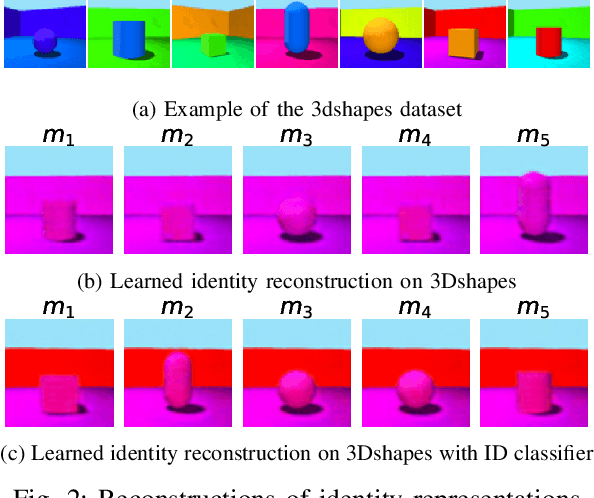
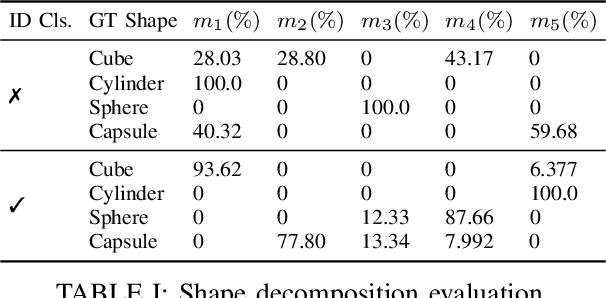
Monolithic neural networks that make use of a single set of weights to learn useful representations for downstream tasks explicitly dismiss the compositional nature of data generation processes. This characteristic exists in data where every instance can be regarded as the combination of an identity concept, such as the shape of an object, combined with modifying concepts, such as orientation, color, and size. The dismissal of compositionality is especially detrimental in robotics, where state estimation relies heavily on the compositional nature of physical mechanisms (e.g., rotations and transformations) to model interactions. To accommodate this data characteristic, modular networks have been proposed. However, a lack of structure in each module's role, and modular network-specific issues such as module collapse have restricted their usability. We propose a modular network architecture that accommodates the mentioned decompositional concept by proposing a unique structure that splits the modules into predetermined roles. Additionally, we provide regularizations that improve the resiliency of the modular network to the problem of module collapse while improving the decomposition accuracy of the model.
Reconciling High Accuracy, Cost-Efficiency, and Low Latency of Inference Serving Systems
Apr 24, 2023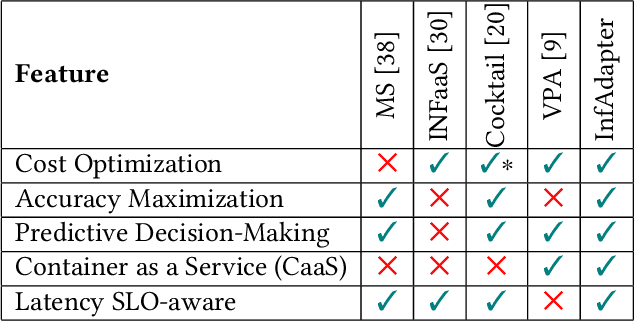
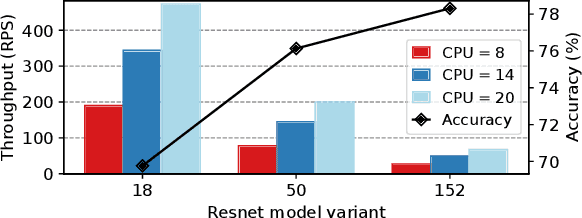
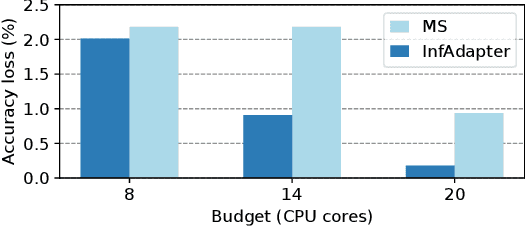

The use of machine learning (ML) inference for various applications is growing drastically. ML inference services engage with users directly, requiring fast and accurate responses. Moreover, these services face dynamic workloads of requests, imposing changes in their computing resources. Failing to right-size computing resources results in either latency service level objectives (SLOs) violations or wasted computing resources. Adapting to dynamic workloads considering all the pillars of accuracy, latency, and resource cost is challenging. In response to these challenges, we propose InfAdapter, which proactively selects a set of ML model variants with their resource allocations to meet latency SLO while maximizing an objective function composed of accuracy and cost. InfAdapter decreases SLO violation and costs up to 65% and 33%, respectively, compared to a popular industry autoscaler (Kubernetes Vertical Pod Autoscaler).
On the Role of Contrastive Representation Learning in Adversarial Robustness: An Empirical Study
Feb 05, 2023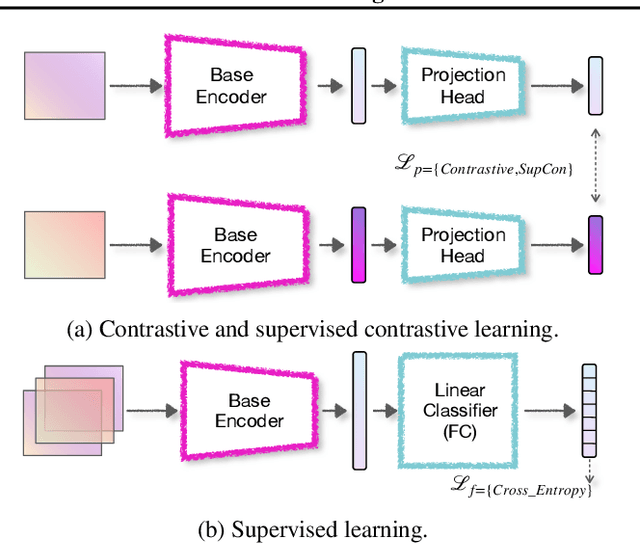

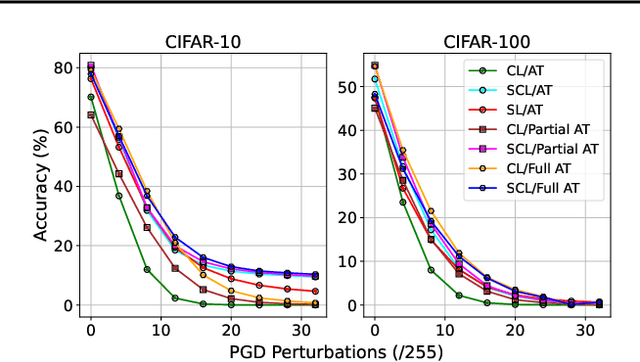

Self-supervised contrastive learning has solved one of the significant obstacles in deep learning by alleviating the annotation cost. This advantage comes with the price of false negative-pair selection without any label information. Supervised contrastive learning has emerged as an extension of contrastive learning to eliminate this issue. However, aside from accuracy, there is a lack of understanding about the impacts of adversarial training on the representations learned by these learning schemes. In this work, we utilize supervised learning as a baseline to comprehensively study the robustness of contrastive and supervised contrastive learning under different adversarial training scenarios. Then, we begin by looking at how adversarial training affects the learned representations in hidden layers, discovering more redundant representations between layers of the model. Our results on CIFAR-10 and CIFAR-100 image classification benchmarks demonstrate that this redundancy is highly reduced by adversarial fine-tuning applied to the contrastive learning scheme, leading to more robust representations. However, adversarial fine-tuning is not very effective for supervised contrastive learning and supervised learning schemes. Our code is released at https://github.com/softsys4ai/CL-Robustness.
CaRE: Finding Root Causes of Configuration Issues in Highly-Configurable Robots
Jan 18, 2023



Robotic systems have several subsystems that possess a huge combinatorial configuration space and hundreds or even thousands of possible software and hardware configuration options interacting non-trivially. The configurable parameters can be tailored to target specific objectives, but when incorrectly configured, can cause functional faults. Finding the root cause of such faults is challenging due to the exponentially large configuration space and the dependencies between the robot's configuration settings and performance. This paper proposes CaRE, a method for diagnosing the root cause of functional faults through the lens of causality, which abstracts the causal relationships between various configuration options and the robot's performance objectives. We demonstrate CaRE's efficacy by finding the root cause of the observed functional faults via CaRE and validating the diagnosed root cause, conducting experiments in both physical robots (Husky and Turtlebot 3) and in simulation (Gazebo). Furthermore, we demonstrate that the causal models learned from robots in simulation (simulating Husky in Gazebo) are transferable to physical robots across different platforms (Turtlebot 3).
Improving the Performance of DNN-based Software Services using Automated Layer Caching
Sep 18, 2022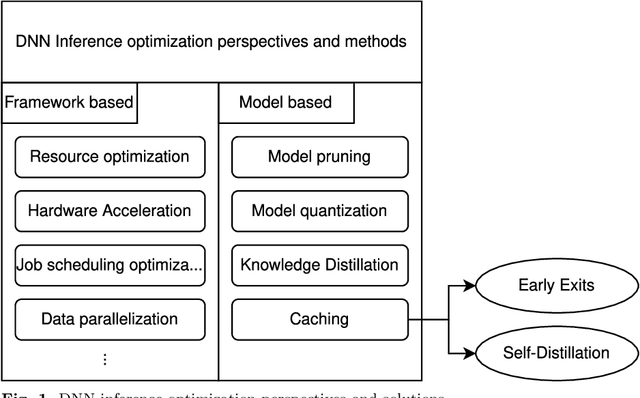
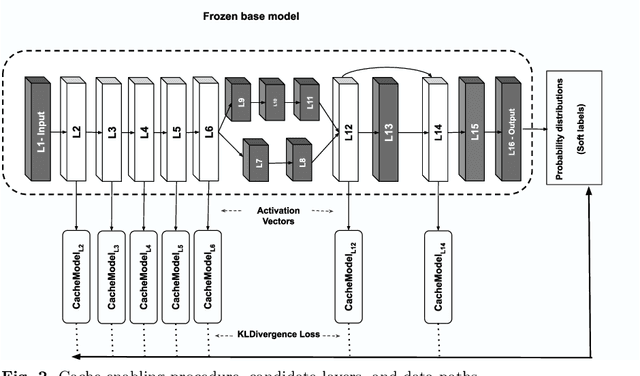
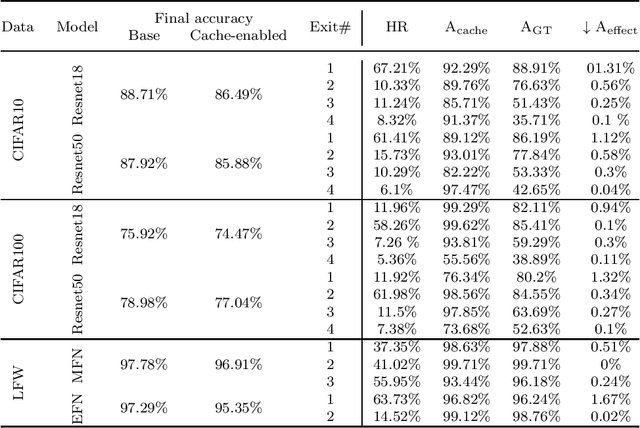
Deep Neural Networks (DNNs) have become an essential component in many application domains including web-based services. A variety of these services require high throughput and (close to) real-time features, for instance, to respond or react to users' requests or to process a stream of incoming data on time. However, the trend in DNN design is toward larger models with many layers and parameters to achieve more accurate results. Although these models are often pre-trained, the computational complexity in such large models can still be relatively significant, hindering low inference latency. Implementing a caching mechanism is a typical systems engineering solution for speeding up a service response time. However, traditional caching is often not suitable for DNN-based services. In this paper, we propose an end-to-end automated solution to improve the performance of DNN-based services in terms of their computational complexity and inference latency. Our caching method adopts the ideas of self-distillation of DNN models and early exits. The proposed solution is an automated online layer caching mechanism that allows early exiting of a large model during inference time if the cache model in one of the early exits is confident enough for final prediction. One of the main contributions of this paper is that we have implemented the idea as an online caching, meaning that the cache models do not need access to training data and perform solely based on the incoming data at run-time, making it suitable for applications using pre-trained models. Our experiments results on two downstream tasks (face and object classification) show that, on average, caching can reduce the computational complexity of those services up to 58\% (in terms of FLOPs count) and improve their inference latency up to 46\% with low to zero reduction in accuracy.