 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Performance of DNN-based Software Services using Automated Layer Caching
Paper and Code
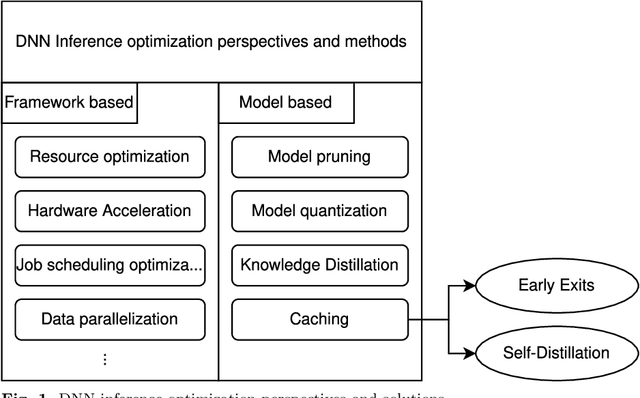
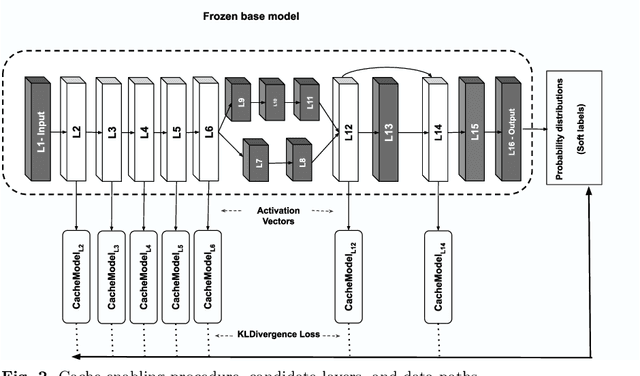
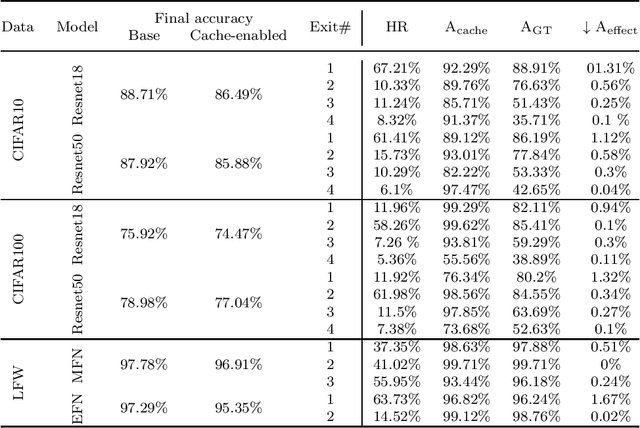
Deep Neural Networks (DNNs) have become an essential component in many application domains including web-based services. A variety of these services require high throughput and (close to) real-time features, for instance, to respond or react to users' requests or to process a stream of incoming data on time. However, the trend in DNN design is toward larger models with many layers and parameters to achieve more accurate results. Although these models are often pre-trained, the computational complexity in such large models can still be relatively significant, hindering low inference latency. Implementing a caching mechanism is a typical systems engineering solution for speeding up a service response time. However, traditional caching is often not suitable for DNN-based services. In this paper, we propose an end-to-end automated solution to improve the performance of DNN-based services in terms of their computational complexity and inference latency. Our caching method adopts the ideas of self-distillation of DNN models and early exits. The proposed solution is an automated online layer caching mechanism that allows early exiting of a large model during inference time if the cache model in one of the early exits is confident enough for final prediction. One of the main contributions of this paper is that we have implemented the idea as an online caching, meaning that the cache models do not need access to training data and perform solely based on the incoming data at run-time, making it suitable for applications using pre-trained models. Our experiments results on two downstream tasks (face and object classification) show that, on average, caching can reduce the computational complexity of those services up to 58\% (in terms of FLOPs count) and improve their inference latency up to 46\% with low to zero reduction in accuracy.